Konvertieren Ihres PyTorch-Modells in das ONNX-Format
In der vorherigen Phase dieses Tutorials haben wir PyTorch verwendet, um unser Machine Learning-Modell zu erstellen. Dieses Modell ist jedoch eine .pth-Datei. Um es in die Windows ML-App integrieren zu können, müssen Sie das Modell in das ONNX-Format konvertieren.
Exportieren des Modells
Zum Exportieren eines Modells verwenden Sie die torch.onnx.export()-Funktion. Diese Funktion führt das Modell aus und zeichnet eine Ablaufverfolgung auf, welche Operatoren zum Berechnen der Ausgaben verwendet werden.
- Kopieren Sie den folgenden Code in die
DataClassifier.py-Datei in Visual Studio oberhalb Ihrer Hauptfunktion (Main).
#Function to Convert to ONNX
def convert():
# set the model to inference mode
model.eval()
# Let's create a dummy input tensor
dummy_input = torch.randn(1, 3, 32, 32, requires_grad=True)
# Export the model
torch.onnx.export(model, # model being run
dummy_input, # model input (or a tuple for multiple inputs)
"Network.onnx", # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['input'], # the model's input names
output_names = ['output'], # the model's output names
dynamic_axes={'input' : {0 : 'batch_size'}, # variable length axes
'output' : {0 : 'batch_size'}})
print(" ")
print('Model has been converted to ONNX')
Es ist wichtig, vor dem Exportieren des Modells model.eval() oder model.train(False) aufzurufen, da dies das Modell in den Rückschlussmodus versetzt. Dies ist erforderlich, da sich Operatoren wie dropout oder batchnorm im Rückschluss- und Trainingsmodus unterschiedlich verhalten.
- Um die Konvertierung in ONNX auszuführen, fügen Sie der Hauptfunktion einen Aufruf der Konvertierungsfunktion hinzu. Sie müssen das Modell nicht erneut trainieren, daher kommentieren wir einige Funktionen aus, die nicht mehr ausgeführt werden müssen. Die Hauptfunktion sieht wie folgt aus.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
convert()
- Führen Sie das Projekt erneut aus, indem Sie auf der Symbolleiste die Schaltfläche
Start Debuggingauswählen oderF5drücken. Es ist nicht erforderlich, das Modell erneut zu trainieren. Laden Sie einfach das vorhandene Modell aus dem Projektordner.
Navigieren Sie zu Ihrem Projektspeicherort, und suchen Sie das ONNX-Modell neben dem .pth-Modell.
Hinweis
Möchten Sie mehr erfahren? Lesen Sie das PyTorch-Tutorial zum Exportieren eines Modells.
Untersuchen Sie Ihr Modell.
Öffnen Sie die Modelldatei
Network.onnxmit Neutron.Wählen Sie den Datenknoten aus, um die Modelleigenschaften zu öffnen.
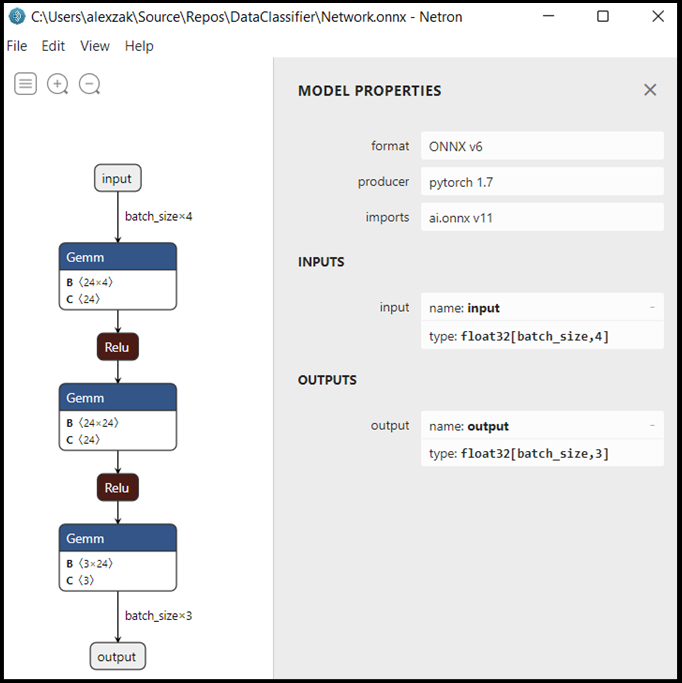
Wie Sie sehen können, erfordert das Modell ein 32-Bit-Tensor-Float-Objekt (mehrdimensionales Array) als Eingabe und gibt ein Tensor-Float-Objekt als Ausgabe zurück. Das Ausgabearray enthält die Wahrscheinlichkeit für jede Bezeichnung. So wie Sie das Modell erstellt haben, werden die Bezeichnungen von drei Zahlen dargestellt, von denen jede mit einer bestimmten Schwertlilienart verbunden ist.
| Bezeichnung 1 | Bezeichnung 2 | Bezeichnung 3 |
|---|---|---|
| 0 | 1 | 2 |
| Iris-setosa | Iris-versicolor | Iris-virginica |
Sie müssen diese Werte extrahieren, um die richtige Vorhersage mit der Windows ML-App anzuzeigen.
Nächste Schritte
Unser Modell ist bereit für die Bereitstellung. Als nächstes erstellen wir für das Hauptereignis eine Windows-Anwendung und führen sie lokal auf Ihrem Windows-Gerät aus.