CPU-Analyse
Dieses Handbuch enthält detaillierte Techniken, die Sie verwenden können, um zentrale Verarbeitungseinheiten (CPU)-bezogene Probleme zu untersuchen, die Sichtungsmetriken darstellen.
Die einzelnen Metrik- oder Problemabschnitte in den Bewertungsspezifischen Analyseleitfäden identifizieren häufige Probleme bei der Untersuchung. Dieses Handbuch bietet Techniken und Tools, mit denen Sie diese Probleme untersuchen können.
Die Techniken in diesem Leitfaden verwenden die Windows Leistungsanalyse (WPA) aus dem Windows Performance Toolkit (WPT). Die WPT ist Teil des Windows Assessment and Deployment Kit (Windows ADK) und kann aus dem Windows-Insider-Programm heruntergeladen werden. Weitere Informationen finden Sie in der technischen Referenz zum Windows Performance Toolkit.
Das Thema ist in die folgenden Kategorien gegliedert:
In diesem Abschnitt wird beschrieben, wie CPU-Ressourcen unter Windows 10 verwaltet werden. |
|
In diesem Abschnitt wird erläutert, wie CPU-Informationen im Windows ADK-Toolkit angezeigt und interpretiert werden. |
|
Dieser Abschnitt enthält eine Sammlung von Techniken, die Sie verwenden können, um häufige Problem im Zusammenhang mit der CPU zu untersuchen und zu klären. |
Hintergrund
Dieser Abschnitt enthält einfache Beschreibungen und eine grundlegende Diskussion über die CPU-Leistung. Für eine umfassendere Studie zu diesem Thema empfehlen wir das Buch „Windows Internals, Fifth Edition“.
Moderne Computer können mehrere CPUs enthalten, die in separaten Sockets installiert sind. Jede CPU kann mehrere physische Prozessorkerne hosten, die jeweils einen oder zwei separate Anweisungsstreams gleichzeitig verarbeiten können. Diese einzelnen Anweisungsstreamprozessoren werden vom Windows-Betriebssystem als logische Prozessoren verwaltet.
In diesem Handbuch verweisen sowohl der Prozessor als auch die CPU auf einen logischen Prozessor – also ein Hardwaregerät, das das Betriebssystem zum Ausführen von Programmanweisungen verwenden kann.
Windows 10 verwaltet Die Prozessorhardware auf zwei Hauptmethoden: Power Management, zum Ausgleich des Stromverbrauchs und der Leistung sowie zur Nutzung, um die Verarbeitungsanforderungen von Programmen und Treibern zu ausgleichen.
Prozessorenergieverwaltung
Prozessoren befinden sich nicht immer in einem Betriebszustand. Wenn keine Anweisungen ausgeführt werden können, setzt Windows einen Prozessor in einen Ziel-Leerlaufzustand (oder C-State), wie vom Windows Power Manager bestimmt. Basierend auf CPU-Nutzungsmustern wird der C-Zielzustand eines Prozessors im Laufe der Zeit angepasst.
Leerlaufzustände sind nummerierte Zustände von C0 (aktiv; nicht im Leerlauf) bis hin zu schrittweisen Zuständen mit niedrigerer Leistung. Zu diesen Zuständen gehören C1 (angehalten, aber die Uhr ist weiterhin aktiviert), C2 (angehalten und die Uhr ist deaktiviert), usw. Die Implementierung von Leerlaufzuständen ist prozessorspezifisch. Eine höhere Zustandsnummer in allen Prozessoren spiegelt jedoch einen niedrigeren Stromverbrauch wider, aber auch eine längere Wartezeit, bevor der Prozessor zur Anweisungsverarbeitung zurückkehren kann. Die Zeit, die in Leerlaufzuständen verbracht wird, wirkt sich erheblich auf den Energieverbrauch und die Akkulaufzeit aus.
Einige Prozessoren können in Leistungszuständen (P-) und Drosselung (T-) arbeiten, auch wenn sie aktiv Anweisungen verarbeiten. P-Zustände definieren die Taktfrequenzen und Spannungsebenen, die der Prozessor unterstützt. T-Zustände ändern die Taktfrequenz nicht direkt, können aber die effektive Taktgeschwindigkeit verringern, indem die Verarbeitungsaktivität auf einigen Bruchteilen von Taktstrichen übersprungen wird. Zusammen bestimmen die aktuellen P- und T-Zustände die effektive Betriebsfrequenz des Prozessors. Niedrigere Frequenzen entsprechen geringerer Leistung und geringerer Stromverbrauch.
Der Windows Power Manager bestimmt einen geeigneten P- und T-Zustand für jeden Prozessor, basierend auf CPU-Nutzungsmustern und Systemleistungsrichtlinien. Die Zeit, die in Hochleistungszuständen im Vergleich zu Zuständen mit niedriger Leistung verbracht wird, wirkt sich erheblich auf den Energieverbrauch und die Akkulaufzeit aus.
Prozessornutzungsverwaltung
Windows verwendet drei Hauptabstraktionen zum Verwalten der Prozessornutzung.
Prozesse
Threads
Verzögerte Prozeduraufrufe (DPCs) und Interrupt Service Routinen (ISRs)
Prozesse und Threads
Alle Benutzermodusprogramme in Windows werden im Kontext eines Prozesses ausgeführt. Ein Prozess enthält die folgenden Attribute und Komponenten:
Ein virtueller Adressraum
Prioritätsklasse
Geladene Programmmodule
Umgebungs- und Konfigurationsinformationen
Mindestens ein Thread
Obwohl Prozesse die Programmmodule, Kontext und Umgebung enthalten, sind sie nicht direkt für die Ausführung auf einem Prozessor geplant. Stattdessen werden Threads, die einem Prozess gehören, für die Ausführung auf einem Prozessor geplant.
Ein Thread verwaltet Ausführungskontextinformationen. Fast alle Berechnungen werden als Teil eines Threads verwaltet. Threadaktivität wirkt sich grundsätzlich auf Messungen und Systemleistung aus.
Da die Anzahl der Prozessoren in einem System begrenzt ist, können alle Threads nicht gleichzeitig ausgeführt werden. Windows implementiert die Zeitfreigabe des Prozessors, wodurch ein Thread für einen bestimmten Zeitraum ausgeführt werden kann, bevor der Prozessor zu einem anderen Thread wechselt. Der Akt des Wechsels zwischen Threads wird als Kontextschalter bezeichnet und wird von einer Windows-Komponente mit dem Namen " Dispatcher" ausgeführt. Der Dispatcher trifft Threadplanungsentscheidungen basierend auf Priorität, idealer Prozessor und Affinität, Quanten und Zustand.
Priority
Priorität ist ein wichtiger Faktor bei der Auswahl des auszuführenden Threads durch den Dispatcher. Die Threadpriorität ist eine ganze Zahl von 0 bis 31. Wenn ein Thread ausführbare Datei ist und eine höhere Priorität hat als ein aktuell ausgeführter Thread, wird der Thread mit niedrigerer Priorität sofort vorgelassen, und der Thread mit höherer Priorität wird kontextverwechselt.
Wenn ein Thread ausgeführt oder ausgeführt werden kann, können keine Threads mit niedrigerer Priorität ausgeführt werden, es sei denn, es gibt genügend Prozessoren, um beide Threads gleichzeitig auszuführen, oder es sei denn, der Thread mit höherer Priorität ist auf die Ausführung nur auf eine Teilmenge verfügbarer Prozessoren beschränkt. Threads haben eine Basispriorität, die vorübergehend zu höheren Prioritäten erhöht werden kann, z. B. wenn der Prozess das Vordergrundfenster besitzt oder wenn eine E/A abgeschlossen ist.
Ideale Prozessor und Affinität
Der ideale Prozessor und die Affinität eines Threads bestimmen die Prozessoren, auf denen ein gegebener Thread ausgeführt werden soll. Jeder Thread verfügt über einen idealen Prozessor, der entweder vom Programm oder automatisch von Windows festgelegt wird. Windows verwendet eine Round-Robin-Methode, sodass jeder Prozessor eine ungefähr gleiche Anzahl von Threads zugewiesen wird. Wenn möglich, plant Windows einen Thread, der auf seinem idealen Prozessor ausgeführt wird; Der Thread kann jedoch gelegentlich auf anderen Prozessoren ausgeführt werden.
Die Prozessoraffinität eines Threads beschränkt die Prozessoren, auf denen ein Thread ausgeführt wird. Dies ist eine stärkere Einschränkung als das ideale Prozessorattribute des Threads. Das Programm legt die Affinität mithilfe von SetThreadAffinityMask fest. Affinität kann verhindern, dass Threads jemals auf bestimmten Prozessoren ausgeführt werden.
Quantum
Kontextschalter sind teure Vorgänge. Windows ermöglicht in der Regel, dass jeder Thread für einen Bestimmten Zeitraum ausgeführt wird, der als Quanten bezeichnet wird, bevor er zu einem anderen Thread wechselt. Die Quantendauer soll die scheinbare Reaktionsfähigkeit des Systems beibehalten. Dadurch wird der Durchsatz maximiert, indem der Aufwand des Kontextwechsels minimiert wird. Quantendauern können zwischen Clients und Servern variieren. Quantendauern sind in der Regel länger auf einem Server, um den Durchsatz auf Kosten der scheinbaren Reaktionsfähigkeit zu maximieren. Auf Clientcomputern weist Windows insgesamt kürzere Quanten zu, bietet jedoch einen längeren Quantenpunkt für den Thread, der dem aktuellen Vordergrundfenster zugeordnet ist.
State
Jeder Thread ist zu einem bestimmten Zeitpunkt in einem bestimmten Ausführungszustand vorhanden. Windows verwendet drei Zustände, die für die Leistung relevant sind; dies sind: Ausführen, Bereit und Warten.
Threads, die derzeit ausgeführt werden, befinden sich im Zustand "Ausführen ". Threads, die ausgeführt werden können, aber derzeit nicht ausgeführt werden, befinden sich im Status Bereit. Threads, die nicht ausgeführt werden können (da sie auf ein bestimmtes Ereignis warten) befinden sich im Status Warten.
Ein Zustand zum Zustandsübergang wird in Abbildung 1 Threadstatusübergängen angezeigt:
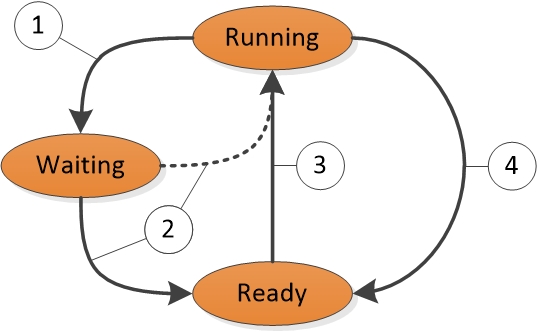
Abbildung 1 Threadstatusübergänge
Abbildung 1 Threadstatusübergänge werden wie folgt erläutert:
Ein Thread im Running-Zustand initiiert einen Übergang in den Waiting-Zustand, indem er eine Wait-Funktion wie WaitForSingleObject oder Sleep(> 0).
Ein laufender Thread oder eine Kernel-Operation bereitet einen Thread im Wartezustand vor (z. B. SetEvent oder Timer-Ablauf). Wenn ein Prozessor leer ist oder wenn der gelesene Thread eine höhere Priorität hat als ein aktuell ausgeführter Thread, kann der gelesene Thread direkt zum Ausführungszustand wechseln. Andernfalls wird er in den Zustand "Bereit" versetzt.
Ein Thread im Ready-Zustand wird für die Verarbeitung durch den Verteiler geplant, wenn ein ausgeführter Thread wartet, (Sleep(0)) oder das Ende seines Quantens erreicht.
Ein Thread im Zustand "Ausführen" wird durch den Verteiler ausgeschaltet und in den Zustand "Bereit" versetzt, wenn er von einem Thread mit höherer Priorität vorgesetzt wird, ergibt (Sleep(0)) oder wenn sein Quantenende endet.
Ein Thread, der im Wartezustand vorhanden ist, weist nicht unbedingt auf ein Leistungsproblem hin. Die meisten Threads verbringen erhebliche Zeit im Wartezustand, wodurch Prozessoren leerlaufzustände eingeben und Energie sparen können. Der Threadstatus wird nur dann zu einem wichtigen Leistungsfaktor, wenn ein Benutzer darauf wartet, dass ein Thread einen Vorgang abschließt.
DPCs und ISRs
Zusätzlich zur Verarbeitung von Threads reagieren Prozessoren auf Benachrichtigungen von Hardwaregeräten wie Netzwerkkarten oder Timern. Wenn ein Hardwaregerät prozessorverwendte Aufmerksamkeit erfordert, generiert es eine Unterbrechung. Windows reagiert auf einen Hardwareunterbruch, indem ein aktuell ausgeführter Thread angehalten und der ISR ausgeführt wird, der dem Unterbrechung zugeordnet ist.
Während der Ausführung eines ISR kann ein Prozessor daran gehindert werden, andere Aktivitäten zu behandeln, einschließlich anderer Unterbrechungen. Aus diesem Grund müssen ISRs schnell abgeschlossen werden, oder die Systemleistung kann beeinträchtigt werden. Um die Ausführungszeit zu verringern, planen ISRs häufig DPCs zum Ausführen von Arbeiten, die als Reaktion auf einen Unterbrechung ausgeführt werden müssen. Für jeden logischen Prozessor verwaltet Windows eine Warteschlange mit geplanten DPCs. DPCs übernehmen Priorität über Threads auf jeder Prioritätsebene. Bevor ein Prozessor zur Verarbeitung von Threads zurückkehrt, führt er alle DPCs in seiner Warteschlange aus.
Während der Ausführung eines Prozessors DPCs und ISRs können keine Threads auf diesem Prozessor ausgeführt werden. Diese Eigenschaft kann zu Problemen für Threads führen, die bei einem bestimmten Durchsatz oder mit präzisem Timing arbeiten müssen, z. B. einen Thread, der Audio- oder Videowiedergabe ausführt. Wenn die Prozessorzeit, die zum Ausführen von DPCs und ISRs verwendet wird, verhindert, dass diese Threads ausreichend Verarbeitungszeit erhalten, erreicht der Thread möglicherweise nicht seinen erforderlichen Durchsatz oder beendet seine Arbeitselemente rechtzeitig.
Windows ADK-Tools
Die Windows ADK schreibt Hardwareinformationen und Bewertungen in Bewertungsergebnissedateien. WPA bietet detaillierte Informationen zur CPU-Auslastung in verschiedenen Diagrammen. In diesem Abschnitt wird erläutert, wie Sie mithilfe von Windows ADK und WPA CPU-Leistungsdaten sammeln, anzeigen und analysieren können.
Windows ADK-Bewertungsergebnissedateien
Da Windows nur symmetrische Multiprocessing-Systeme unterstützt, gelten alle Informationen in diesem Abschnitt für alle installierten CPUs und Kerne.
Detaillierte CPU-Hardwareinformationen sind im EcoSysInfo Abschnitt einer Bewertungsergebnisdateien unter dem <Processor><Instance id=”0”> Knoten verfügbar.
Zum Beispiel:
<Processor>
<Instance id="0">
<ProcessorName>The name of the first CPU</ProcessorName>
<TSCFrequency>The maximum frequency of the first CPU</TSCFrequency>
<NumProcs>The total number of processors</NumProcs>
<NumCores>The total number of cores</NumCores>
<NumCPUs>The total number of logical processors</NumCPUs>
...and so on...
Diagramme
Nachdem Sie eine Ablaufverfolgung in WPA geladen haben, finden Sie Prozessorhardwareinformationen unter den Abschnitten Trace/System Configuration/General and Trace/System Configuration/PnP der WPA-Benutzeroberfläche.
Hinweis Alle Verfahren in diesem Leitfaden treten in WPA auf.
CPU-Idle-Zustandsdiagramm
Wenn Leerlaufstatusinformationen in einer Ablaufverfolgung gesammelt werden, wird das Diagramm "Power/CPU Idle States " in der WPA-Benutzeroberfläche angezeigt. Dieses Diagramm enthält immer Daten für den Ziel-Leerlaufstatus für jeden Prozessor. Das Diagramm enthält auch Informationen zum tatsächlichen Leerlaufzustand jedes Prozessors, wenn dieser Zustand vom Prozessor unterstützt wird.
Jede Zeile in der folgenden Tabelle beschreibt eine Leerlaufzustandsänderung für den Ziel- oder Ist-Zustand eines Prozessors. Die folgenden Spalten sind für jede Zeile im Diagramm verfügbar:
| Column | Details |
|---|---|
CPU |
Der Prozessor, der von der Zustandsänderung betroffen ist. |
entry_time |
Die Zeit, zu der der Prozessor den Leerlaufzustand eingegeben hat. |
Beendigungszeitpunkt |
Die Zeit, zu der der Prozessor den Leerlaufzustand beendet hat. |
Max. Dauer (ms) |
Die Zeit, die im Leerlaufzustand (Standardaggregation:maximum) ausgegeben wird. |
Min:Duration(ms) |
Die Zeit, die im Leerlaufzustand ausgegeben wird (Standardaggregation:minimum). |
Nächster Staat |
Der Zustand, zu dem der Prozessor nach dem aktuellen Zustand wechselt. |
Vorzustand |
Der Zustand, von dem der Prozessor vor dem aktuellen Zustand überstieg. |
State |
Der aktuelle Leerlaufzustand. |
Zustand (numerischer Zustand) |
Der aktuelle Leerlaufzustand als Zahl (z. B. 0 für C0). |
Summe:Dauer(ms) |
Die Zeit, die im Leerlaufzustand (Standardaggregation:summe) ausgegeben wird. |
Tabelle |
Nicht verwendet |
type |
Entweder Ziel (für den ausgewählten Zielzustand des Power Managers für den Prozessor) oder "Actual" (für den tatsächlichen Leerlaufzustand des Prozessors). |
Das Standard-WPA-Profil stellt zwei Voreinstellungen für dieses Diagramm bereit: Zustand nach Typ, CPU und Zustandsdiagramm nach Typ, CPU.
Zustand nach Typ, CPU
Die Target- und Actual-Zustände jeder CPU werden zusammen mit der Statusnummer auf der Y-Achse im Zustand nach Typ, CPU-Diagramm dargestellt. Abbildung 2 Status des CPU-Leerlaufstatus nach Typ, CPU zeigt den tatsächlichen Zustand der CPU an, da sie zwischen aktiven und Ziel-Leerlaufzuständen schwankt.
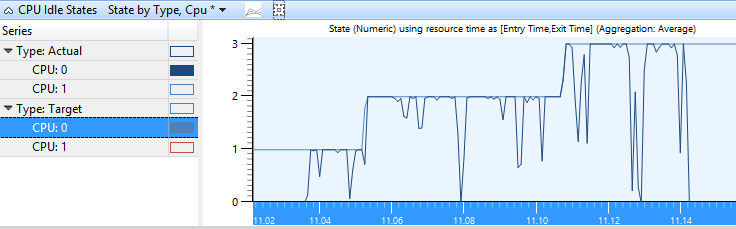
Abbildung 2 CPU-Leerlaufstatus nach Typ, CPU
Zustandsdiagramm nach Typ, CPU
In diesem Diagramm werden die Status "Ziel" und "Tatsächlich" jeder CPU im Zeitachsenformat angezeigt. Jeder Zustand weist eine separate Zeile in der Zeitachse auf. Abbildung 3 CPU-Idle-Zustandsdiagramm nach Typ, CPU zeigt die gleichen Daten wie Abbildung 2 CPU-Idle-Statusstatus nach Typ, CPU, in einer Zeitachsenansicht.
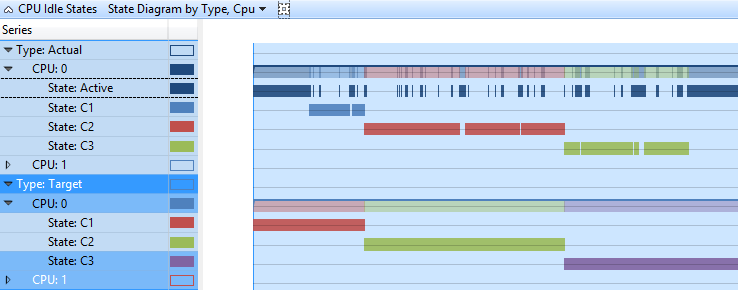
Abbildung 3 CPU-Idle-Zustandsdiagramm nach Typ, CPU
CPU-Häufigkeitsdiagramm
Wenn CPU-Häufigkeitsdaten auf einem System gesammelt wurden, das mehrere P- oder T-Zustände unterstützt, steht das CPU-Frequenzdiagramm auf der WPA-Benutzeroberfläche zur Verfügung. Jede Zeile in der folgenden Tabelle stellt die Uhrzeit auf einer bestimmten Häufigkeitsebene für einen Prozessor dar. Die Spalte "Frequenz" (MHz) enthält eine begrenzte Anzahl von Frequenzen, die den P-Zuständen und T-Zuständen entsprechen, die vom Prozessor unterstützt werden. Die folgenden Spalten sind für jede Zeile im Diagramm verfügbar:
| Column | Details |
|---|---|
Dauer: |
Die Dauer wird als Prozentsatz der Gesamt-CPU-Zeit über den aktuell sichtbaren Zeitraum ausgedrückt. |
Anzahl |
Die Anzahl der Häufigkeitsänderungen (immer 1 für einzelne Zeilen). |
CPU |
Die CPU, die von der Frequenzänderung betroffen ist. |
entry_time |
Die Zeit, zu der die CPU den P-Zustand eingegeben hat. |
Beendigungszeitpunkt |
Die Zeit, zu der die CPU den P-Zustand beendet hat. |
Mittelwert Häufigkeit |
Die Häufigkeit der CPU während der Zeit, zu der sie sich im P-Zustand befindet. |
Max. Dauer (ms) |
Die Zeit, die im P-Zustand (Standardaggregation:maximum) ausgegeben wird. |
Min:Duration(ms) |
Die Zeit, die im P-Zustand (Standardaggregation:minimum) ausgegeben wird. |
Summe:Dauer(ms) |
Die Zeit, die im P-Zustand (Standardaggregation:summe) ausgegeben wird. |
Tabelle |
Nicht verwendet |
type |
Weitere Informationen zum P-Zustand. |
Das Standardprofil definiert die Häufigkeit nach CPU-Voreinstellung für dieses Diagramm. Abbildung 4 CPU-Häufigkeit durch CPU zeigt eine CPU an, da sie zwischen drei P-Zuständen übergibt:

Abbildung 4 CPU-Häufigkeit nach CPU
CPU-Auslastung (Stichproben) Graph
Die Daten, die im CPU-Nutzungsdiagramm (Sampled) angezeigt werden, stellen Beispiele von CPU-Aktivitäten dar, die im regulären Samplingintervall durchgeführt werden. In den meisten Spuren ist dies eine Millisekunden (1ms). Jede Zeile in der Tabelle stellt eine einzelne Stichprobe dar.
Das Gewicht des Beispiels stellt die Bedeutung dieses Beispiels dar, relativ zu anderen Beispielen. Die Gewichtung entspricht dem Zeitstempel des aktuellen Beispiels minus dem Zeitstempel des vorherigen Beispiels. Das Gewicht entspricht nicht immer dem Stichprobenintervall aufgrund von Schwankungen im Systemzustand und der Aktivität.
Abbildung 5 CPU Sampling stellt dar, wie Daten gesammelt werden:
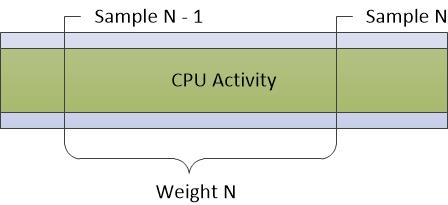
Abbildung 5 CPU-Sampling
CPU-Aktivitäten, die zwischen Stichproben auftreten, werden bei dieser Samplingmethode nicht aufgezeichnet. Daher sind Aktivitäten von sehr kurzer Dauer wie DPCs und ISRs nicht gut in der CPU-Sampling-Grafik dargestellt.
Die folgenden Spalten sind für jede Zeile im Diagramm verfügbar:
| Column | Details |
|---|---|
Gewichtung: |
Die Gewichtung wird als Prozentsatz der gesamten CPU-Zeit ausgedrückt, die über den aktuell sichtbaren Zeitraum ausgegeben wird. |
Adresse |
Die Speicheradresse der Funktion, die sich am oberen Rand des Stapels befindet. |
Alle {count} |
Die Anzahl der Beispiele, die durch eine Zeile dargestellt werden. Diese Zahl enthält Beispiele, die ausgeführt werden, wenn ein Prozessor leer ist. Für einzelne Zeilen ist diese Spalte immer 1. |
Anzahl |
Die Anzahl der Beispiele, die durch eine Zeile dargestellt werden, ausgenommen Beispiele, die beim Leerlauf eines Prozessors durchgeführt werden. Für einzelne Zeilen ist diese Spalte immer 1 (oder 0, für Fälle, in dem die CPU in einem Niedrigleistungszustand war). |
CPU |
Der 0-basierte Index der CPU, auf der dieses Beispiel genommen wurde. |
Anzeigename |
Der Anzeigename des aktiven Prozesses. |
DPC/ISR |
Unabhängig davon, ob das Beispiel reguläre CPU-Nutzung, ein DPC/ISR oder einen Zustand mit niedriger Leistung gemessen hat. |
Funktion |
Die Funktion am oberen Rand des Stapels. |
Modul |
Das Modul, das die Funktion oben im Stapel enthält. |
Priority |
Die Priorität des ausgeführten Threads. |
Prozess |
Der Imagename des Prozesses, der den ausgeführten Code besitzt. |
Prozessname |
Der vollständige Name (einschließlich Prozess-ID) des Prozesses, der den ausgeführten Code besitzt. |
Stapel |
Der Stapel des ausgeführten Threads. |
Thread-ID |
Die ID des ausgeführten Threads. |
Threadstartfunktion |
Die Funktion, mit der der ausgeführte Thread gestartet wurde. |
Threadstartmodul |
Das Modul, das die Threadstartfunktion enthält. |
TimeStamp |
Die Zeit, zu der die Probe genommen wurde |
Weight |
Die Zeit (in Millisekunden), die durch das Beispiel dargestellt wird (also die Zeit seit dem letzten Beispiel). |
Das Standardprofil stellt die folgenden Voreinstellungen für dieses Diagramm bereit:
Auslastung nach CPU
Auslastung nach Priorität
Nutzung nach Prozess
Auslastung nach Prozess und Thread
Auslastung nach CPU
Die CPU-Auslastung durch CPU-Diagramm zeigt, wie die Arbeit zwischen Prozessoren verteilt wird. Abbildung 6 CPU-Auslastung durch CPU zeigt diese Verteilung für zwei CPUs:
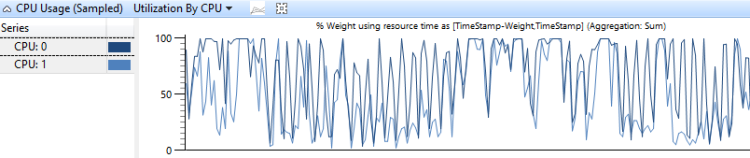
Abbildung 6 CPU-Nutzungsauslastung nach CPU
Auslastung nach Priorität
Die CPU-Verwendung , die nach Threadpriorität gruppiert ist, zeigt, wie hohe Prioritätsthreads sich auf untere Prioritätsthreads auswirken. Abbildung 7 CPU-Auslastung (Beispiel) durch Priorität zeigt dieses Diagramm an:
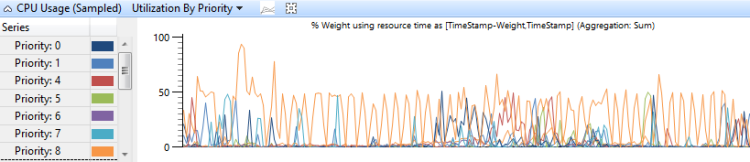
Abbildung 7 CPU-Nutzung (Beispiel) Auslastung nach Priorität
Nutzung nach Prozess
CPU-Verwendung , die nach Prozess gruppiert wird, zeigt die relative Verwendung von Prozessen an. Abbildung 8 CPU-Auslastung (Beispiel) nach Prozess zeigt diese Voreinstellung an. In diesem Beispieldiagramm wird gezeigt, dass ein Prozess mehr CPU-Zeit als die anderen Prozesse benötigt.
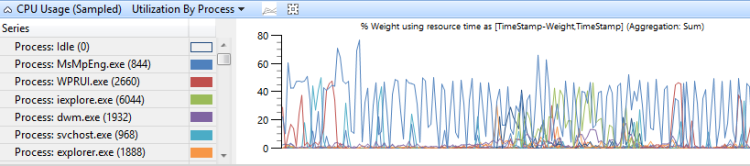
Abbildung 8 CPU-Verwendung (Beispiel) Auslastung nach Prozess
Auslastung nach Prozess und Thread
CPU-Verwendung , die nach Prozess gruppiert ist und dann nach Thread gruppiert wird, zeigt die relative Verwendung von Prozessen und den Threads in jedem Prozess an. Abbildung 9 CPU-Nutzung (Beispiel) Auslastung nach Prozess und Thread zeigt diese Voreinstellung an. Die Threads eines einzelnen Prozesses werden in diesem Diagramm ausgewählt.
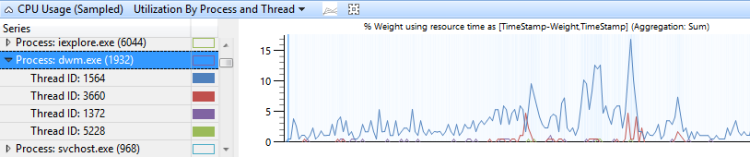
Abbildung 9 CPU-Auslastung (Beispiel) durch Prozess und Thread
CPU-Auslastung (präzise) Graph
Der CPU-Nutzungsdiagramm (Präzise) erfasst Informationen, die mit Kontextwechselereignissen verknüpft sind. Jede Zeile stellt eine Reihe von Daten dar, die einem einzelnen Kontextschalter zugeordnet sind; das heißt, wenn ein Thread ausgeführt wurde. Daten werden für die folgende Ereignissequenz gesammelt:
Der neue Thread wird ausgeschaltet.
Der neue Thread wird durch den bereitstehenden Thread ausgeführt.
Der neue Thread wird umgestellt, wodurch ein alter Thread gewechselt wird.
Der neue Thread wird erneut ausgeschaltet.
In Abbildung 10 PRÄZISEs Diagramm zur CPU-Verwendung fließt die Zeit von links nach rechts. Die Diagrammbeschriftungen entsprechen Spaltennamen im CPU-Nutzungsdiagramm (Präzises) Diagramm. Beschriftungen für Zeitstempelspalten werden oben im Diagramm angezeigt, und Beschriftungen für Spalten für Intervalldauer werden am unteren Rand des Diagramms angezeigt.
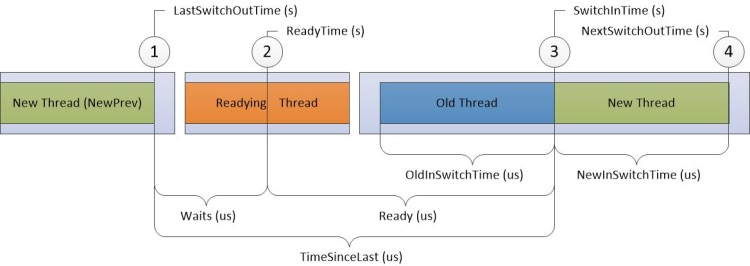
Abbildung 10 CPU-Verwendung präzises Diagramm
Unterbrechungen in der Zeitachse in Abbildung 10 CPU-Nutzungsgenaues Diagramm teilen die Zeitachse in Regionen, die gleichzeitig auf verschiedenen CPUs auftreten können. Diese Zeitachsen können überlappen, solange die Reihenfolge der nummerierten Ereignisse nicht geändert wird. Beispielsweise kann der Readying-Thread gleichzeitig auf Prozessor-2 ausgeführt werden, wenn ein neuer Thread ausgeschaltet und dann wieder auf Prozessor-1 aktiviert ist.
Informationen werden für die folgenden vier Ziele in der Zeitachse aufgezeichnet:
Neuer Thread, der der Thread ist, der gewechselt wurde. Es ist der primäre Fokus dieser Zeile im Diagramm.
NewPrev-Thread, der sich auf das vorherige Mal bezieht, in dem der neue Thread gewechselt wurde.
Bereiter Thread, der der Thread ist, der den neuen Thread vorbereitet hat, um verarbeitet zu werden.
Alter Thread, der der Thread ist, der ausgeschaltet wurde, wenn der neue Thread gewechselt wurde.
Die Daten in der folgenden Tabelle beziehen sich auf jeden Zielthread:
| Column | Details |
|---|---|
% CPU Usage |
Die CPU-Auslastung des neuen Threads nach dem Wechsel. Dieser Wert wird als Prozentsatz der gesamten CPU-Zeit über den aktuell sichtbaren Zeitraum ausgedrückt. |
Anzahl |
Die Anzahl der Kontextwechsel, die durch die Zeile dargestellt werden. Für einzelne Zeilen lautet dieser Wert immer 1. |
Count:Waits |
Die Anzahl der Wartezeiten, die durch die Zeile dargestellt werden. Dies ist immer 1 für einzelne Zeilen, außer wenn ein Thread zu einem Leerlaufzustand wechselt; in diesem Fall ist er auf 0 festgelegt. |
CPU |
Die CPU, auf der der Kontextschalter aufgetreten ist. |
CPU-Verwendung (ms) |
Die CPU-Auslastung des neuen Threads nach dem Kontextwechsel Dies entspricht der NewInSwitchTime, wird jedoch in Millisekunden angezeigt. |
IdealCpu |
Die ideale CPU, die vom Zeitplaner für den neuen Thread ausgewählt wurde. |
LastSwitchOutTime (s) |
Das vorherige Mal, als der neue Thread ausgeschaltet wurde. |
NewInPri |
Die Priorität des neuen Threads, der gewechselt wird. |
NewInSwitchTime(s) |
NextSwitchOutTime(s) minus SwitchInTime(s) |
NewOutPri |
Die Priorität des neuen Threads, wenn er ausschaltet. |
NewPrevOutPri |
Die Priorität des neuen Threads, wenn er zuvor ausgeschaltet wurde. |
NewPrevState |
Der Zustand des neuen Threads, nachdem er zuvor ausgeschaltet wurde. |
NewPrevWaitMode |
Der Wartenmodus des neuen Threads, wenn er zuvor ausgeschaltet wurde. |
NewPrevWaitReason |
Der Grund dafür, dass der neue Thread ausgeschaltet wurde. |
NewPriDecr |
Die Prioritätssteigerung, die sich auf den Thread auswirkt. |
NewProcess |
Der Prozess des neuen Threads |
NewProcess-Name |
Der Name des Prozesses des neuen Threads, einschließlich PID. |
NewQnt |
Nicht verwendet. |
newState |
Der Zustand des neuen Threads nach dem Wechsel. |
NewThreadId |
Die Thread-ID des neuen Threads |
NewThreadStack |
Der Stapel des neuen Threads, wenn dieser eingefügt wird. |
NewThreadStartFunction |
Die Startfunktion des neuen Threads. |
NewThreadStartModule |
Das Startmodul des neuen Threads. |
NewWaitMode |
Der Wartenmodus des neuen Threads. |
NewWaitReason |
Der Grund dafür, dass der neue Thread ausgeschaltet wurde. |
NextSwitchOutTime(s) |
Der Zeitpunkt, an dem der neue Thread als nächstes gewechselt wurde. |
OldInSwitchTime(s) |
Die Zeit, in der der alte Thread gewechselt wurde, bevor es ausgeschaltet wurde. |
OldOutPri |
Die Priorität des alten Threads, wenn es ausgeschaltet wurde. |
OldProcess |
Der Besitzerprozess des vorbereitenden Threads |
OldProcess-Name |
Der Name des Prozesses des neuen Threads, einschließlich PID. |
OldQnt |
Nicht verwendet. |
OldState |
Der Zustand des alten Threads nach dem Wechsel. |
OldThreadId |
Die Thread-ID des alten Threads. |
OldThreadStartFunction |
Die Startfunktion des alten Threads. |
OldThreadStartModule |
Das Startmodul des alten Threads. |
OldWaitMode |
Der Wartenmodus des alten Threads. |
OldWaitReason |
Der Grund dafür, dass der alte Thread ausgeschaltet wurde. |
PrevCState |
Der vorherige CState des Prozessors. Wenn dies nicht 0 (Aktiv) ist, war der Prozessor in einem Leerlaufzustand, bevor der neue Thread kontextgeschaltet wurde. |
Ready(s) |
SwitchInTime(s) minusReadyTime (s) |
Vorbereiten von ThreadId |
Die Thread-ID des vorbereitenden Threads |
Vorbereiten von ThreadStartFunction |
Die Startfunktion des bereitstehenden Threads. |
Vorbereiten von ThreadStartModule |
Das Startmodul des bereitstehenden Threads. |
ReadyingProcess |
Der Besitzerprozess des vorbereitenden Threads |
ReadyingProcess Name |
Der Name des Prozesses des neuen Threads, einschließlich PID. |
ReadyThreadStack |
Der Stapel des vorbereitenden Threads |
ReadyTime (s) |
Die Vorbereitungsdauer für den neuen Thread |
SwitchInTime(s) |
Der Zeitpunkt, zu dem der neue Thread eingefügt wurde |
TimeSinceLast (s) |
SwitchInTime(s) minus LastSwitchOutTime (s) |
Waits (s) |
ReadyTime (s) minus LastSwitchOutTime (s) |
Das Standardprofil verwendet die folgenden Voreinstellungen für dieses Diagramm:
Zeitachse nach CPU
Zeitachse nach Prozess, Thread
Verwendung nach Priorität bei Kontextwechselbeginn
Auslastung nach CPU
Auslastung nach Prozess, Thread
Zeitachse nach CPU
Die CPU-Auslastung pro CPU-Zeitachse zeigt, wie die Arbeit zwischen Prozessoren verteilt wird. Abbildung 11 CPU-Auslastung (Präzise) Zeitachse nach CPU zeigt die Zeitachse auf einem Achtprozessorsystem an:
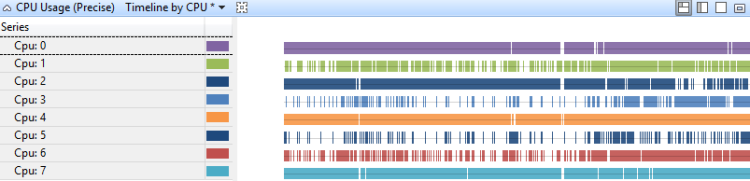
Abbildung 11 CPU-Auslastung (Präzise) Zeitachse nach CPU
Zeitachse nach Prozess, Thread
Die CPU-Auslastung pro Prozess, pro Threadzeitachse, zeigt an, welche Prozesse Threads zu bestimmten Zeiten ausgeführt haben. Abbildung 12 Zeitachse (Präzise) Zeitachse nach Prozess, Thread zeigt diese Zeitachse über mehrere Prozesse hinweg:
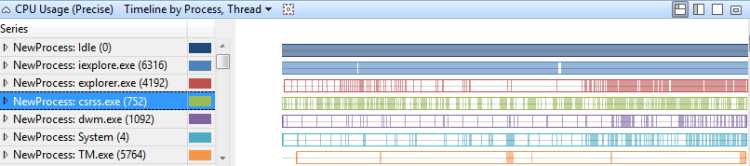
Abbildung 12 Verwendungszeitachse (präzise) nach Prozess, Thread
Verwendung nach Priorität bei Kontextwechselbeginn
In diesem Diagramm werden Platzen der Threadaktivität mit hoher Priorität auf jeder Prioritätsebene identifiziert. Abbildung 13 CPU-Auslastung (Präzise) Verwendung nach Priorität bei Context Switch Begin zeigt die Verteilung der Prioritäten:
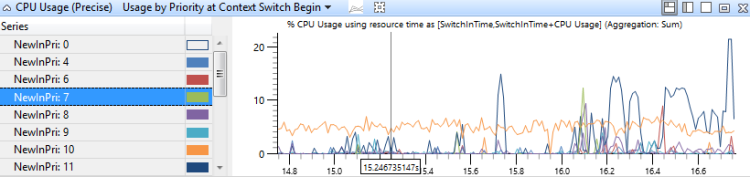
Abbildung 13 CPU-Auslastung (Präzise) Verwendung nach Priorität bei Context Switch Begin
Auslastung nach CPU
In diesem Diagramm wird die CPU-Auslastung gruppiert und von CPU dargestellt, um zu zeigen, wie die Arbeit zwischen Prozessoren verteilt wird. Abbildung 14 CPU-Auslastung (Präzise) Auslastung nach CPU zeigt dieses Diagramm für ein System mit acht Prozessoren.
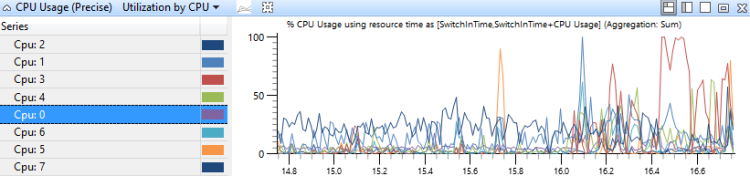
Abbildung 14 CPU-Auslastung (präzise) nach CPU
Auslastung nach Prozess, Thread
In diesem Diagramm wird die CPU-Auslastung zunächst nach dem Prozess und dann nach dem Thread gruppiert. Es zeigt die relative Verwendung von Prozessen und die Threads in jedem Prozess Abbildung 15 CPU-Auslastung (Präzise) Auslastung nach Prozess, Thread zeigt diese Verteilung über mehrere Prozesse hinweg:
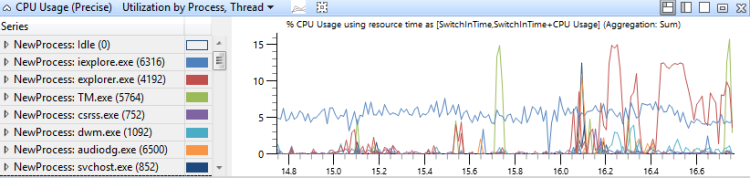
Abbildung 15 CPU-Auslastung (präzise) nach Prozess, Thread
DPC/ISR Graph
Das DPC/ISR-Diagramm ist die primäre Quelle für DPC/ISR-Informationen in WPA. Jede Zeile im Diagramm stellt ein Fragment dar, das einen Zeitraum darstellt, in dem ein DPC oder ISR unterbrechungsfrei ausgeführt wurde. Daten werden am Anfang und Ende von Fragmenten gesammelt. Zusätzliche Daten werden gesammelt, wenn ein DPC/ISR abgeschlossen ist. Abbildung 16 DPC/ISR-Diagramm zeigt, wie dies funktioniert:
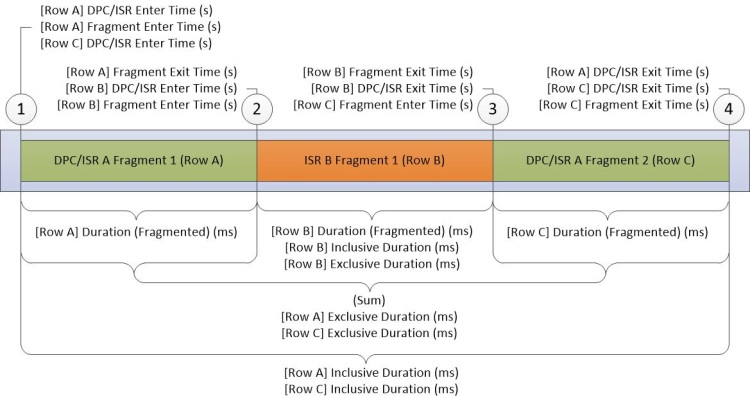
Abbildung 16 DPC/ISR-Diagramm
Abbildung 16 DPC/ISR-Diagramm beschreibt Daten, die während der folgenden Aktivitäten gesammelt wurden:
DPC/ISR-A wird ausgeführt.
Ein Geräteunterbruch, der eine höhere Unterbrechungsstufe als DPC/ISR-A hat, bewirkt , dass ISR-BDPC/ISR A unterbrochen wird, wodurch das erste Fragment von DPC/ISR-A beendet wird.
ISR-B abgeschlossen und endet damit das Fragment von ISR-B. DPC/ISR-A setzt die Ausführung in einem zweiten Fragment fort.
DPC/ISR-A abgeschlossen, wodurch das zweite Fragment von DPC/ISR-A beendet wird.
Eine Zeile für jedes Fragment wird in der Datentabelle angezeigt. Die Fragmente für DPC/ISR-A teilen identische Informationen mit nicht fragmentierten Spalten.
Die Spalten für das DPC/ISR-Diagramm beschreiben Informationen auf Fragmentebene oder DPC/ISR-Ebenenspalten. Jedes Fragment unterscheidet sich unterschiedliche Daten in Spalten auf Fragmentebene und identische Daten in DPC/ISR-Spalten.
| Column | Details |
|---|---|
% Dauer (fragmentiert) |
Dauer (fragmentiert), die als Prozentsatz der Gesamt-CPU-Zeit über den aktuell sichtbaren Zeitraum ausgedrückt wird. |
% Exklusive Dauer |
Exklusive Dauer, die als Prozentsatz der Gesamt-CPU-Zeit über den aktuell sichtbaren Zeitraum ausgedrückt wird. |
% Inklusive Dauer |
Inklusive Dauer, die als Prozentsatz der Gesamt-CPU-Zeit über den aktuell sichtbaren Zeitraum ausgedrückt wird. |
Adresse |
Die Speicheradresse der DPC- oder ISR-Funktion. |
Anzahl (DPCs/ISRs) |
Die Anzahl der DPCs/ISRs, die durch diese Zeile dargestellt werden. Dies ist immer 1 für Zeilen, die das endgültige Fragment eines DPC/ISR darstellen; andernfalls ist diese Anzahl 0. |
Anzahl (Fragmente) |
Die Anzahl der Fragmente, die durch die Zeile dargestellt werden. Für einzelne Zeilen lautet dieser Wert immer 1. |
CPU |
Der Index des logischen Prozessors, auf dem der DPC oder ISR ausgeführt wurde. |
DPC-Typ |
Für DPC, den Typ von DPC, entweder Normal oder Timer. Dieser Wert ist für einen ISR leer. |
DPC/ISR-Eingabezeit (s) |
Die Zeit in der Ablaufverfolgung, wenn der DPC/ISR gestartet wurde. |
DPC/ISR Exit Time (s) |
Die Zeit vom Anfang der Ablaufverfolgung bis zum Abschluss des DPC/ISR. |
Dauer (fragmentiert) (ms) |
Fragment Exit Time (s) minus Fragment Enter Time (s) in Millisekunden. |
Exklusive Dauer (ms) |
Die Summe der fragmentierten Dauer in ms. für alle Fragmente dieses DPC/ISR. |
Fragment |
Wenn der DPC/ISR dieser Zeile mehrere Fragmente aufweist, lautet dieser Wert "True". andernfalls lautet " False". |
Fragment |
Wenn dies nicht das einzige Fragment für diesen DPC/ISR war, lautet dieser Wert "True"; andernfalls lautet " False". |
Fragment-Eingabezeit (s) |
Die Zeit, zu der das Fragment gestartet wurde. |
Fragmentausgangszeit (s) |
Uhrzeit, zu der die Ausführung des Auftrags beendet wurde. |
Funktion |
Die DPC- oder ISR-Funktion, die ausgeführt wurde. |
Inklusive Dauer (ms) |
DPC/ISR Exit Time (s) minus DPC/ISR Enter Time (s) in Millisekunden. |
MessageIndex |
Der Unterbrechungsindex für signalgesteuerte Unterbrechungen. |
Modul |
Das Modul, das die DPC- oder ISR-Funktion enthält. |
Rückgabewert |
Der Rückgabewert des DPC/ISR |
type |
Der Typ des Ereignisses; dies ist entweder DPC oder Interrupt (ISR). |
Vektor |
Der Wert des Unterbrechungsvektors auf dem Gerät. |
Das Standardprofil verwendet die folgenden Voreinstellungen für dieses Diagramm:
[DPC;ISR;DPC/ISR] Dauer nach CPU
[DPC;ISR;DPC/ISR] Dauer nach Modul, Funktion
[DPC;ISR;DPC/ISR] Zeitachse nach Modul, Funktion
[DPC;ISR;DPC/ISR] Dauer nach CPU
DPC/ISR-Ereignisse werden von der CPU aggregiert, auf der sie ausgeführt wurden und nach Dauer sortiert werden. In diesem Diagramm wird die Zuordnung der DPC-Aktivität für CPUs dargestellt. Abbildung 17 DPC/ISR Duration by CPU zeigt dieses Diagramm für ein System mit acht Prozessoren.
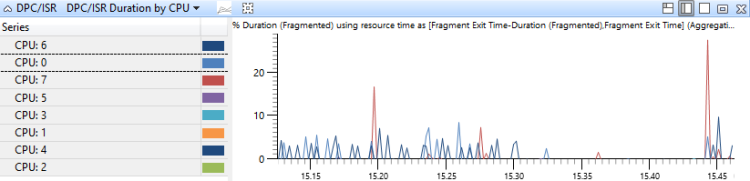
Abbildung 17 DPC/ISR-Dauer nach CPU
[DPC;ISR;DPC/ISR] Dauer nach Modul, Funktion
DPC/ISR-Ereignisse werden in diesem Diagramm anhand des Moduls und der Funktion der DPC/ISR-Routinen aggregiert und nach Dauer sortiert. Dies zeigt, welche DPC/ISR-Routinen die meiste Zeit verbraucht haben, in Abbildung 18 DPC/ISR-Dauer nach Modul, Funktion zeigt einen Zeitraum an, der DPC/ISR-Aktivität in zwei Modulen angibt:
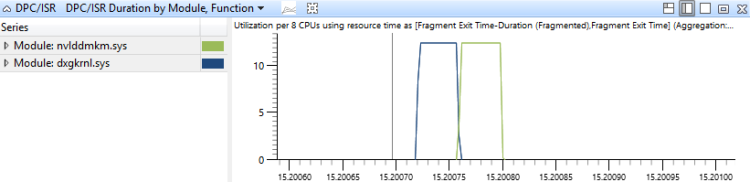
Abbildung 18 DPC/ISR-Dauer nach Modul, Funktion
[DPC;ISR;DPC/ISR] Zeitachse nach Modul, Funktion
DPC/ISR-Ereignisse werden in diesem Diagramm durch das Modul und die Funktion der DPC/ISR-Routinen aggregiert. Sie werden als Zeitachse dargestellt. Dieses Diagramm enthält eine detaillierte Ansicht des Zeitraums, in dem DPCs/ISRs ausgeführt wurden. Dieses Diagramm kann auch zeigen, wie einzelne DPC/ISRs fragmentiert werden können. Abbildung 19 DPC/ISR-Zeitachse nach Modul, Funktion zeigt eine Zeitachse der Aktivität in drei Modulen:

Abbildung 19 DPC/ISR-Zeitachse nach Modul, Funktion
Stapelbäume
Stapelstrukturen werden in den CPU-Auslastungstabellen (Sampled), CPU-Auslastung (Präzise) und DPC/ISR-Tabellen in WPA und in Problemen angezeigt, die in Bewertungsberichten gemeldet werden. Stapelstrukturen stellen die Aufrufstapel dar, die mehreren Ereignissen im Laufe eines Zeitraums zugeordnet sind. Jeder Knoten in der Struktur stellt ein Stapelsegment dar, das von einer Teilmenge der Ereignisse geteilt wird. Die Struktur wird aus den einzelnen Stapeln erstellt und in Abbildung 20 Stapel aus drei Ereignissen dargestellt:

Abbildung 20 Stapel aus drei Ereignissen
Abbildung 21 Allgemeine Segmente identifiziert zeigt, wie häufige Sequenzen für dieses Diagramm identifiziert werden:

Abbildung 21 Allgemeine Segmente identifiziert
Abbildung 22 Struktur, die aus Stapeln erstellt wurde, zeigt, wie die allgemeinen Segmente kombiniert werden, um die Knoten einer Struktur zu bilden:
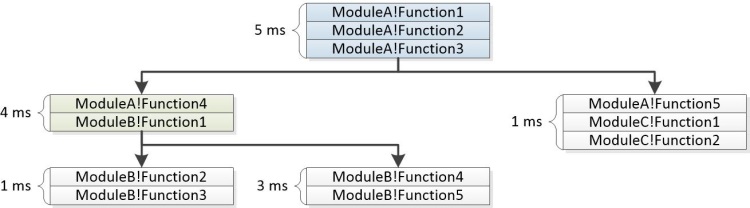
Abbildung 22 Struktur, die aus Stapeln erstellt wurde
Die Spalte "Stacks " in der WPA-Benutzeroberfläche enthält einen Erweiterungser für jeden Nicht-Blattknoten. In den gemeldeten Bewertungsproblemen wird die Struktur zusammen mit den Aggregatgewichten angezeigt. Einige Verzweigungen können aus dem Diagramm entfernt werden, wenn ihre Gewichtungen keinen angegebenen Schwellenwert erfüllen. Der folgende Beispielstapel zeigt, wie die oben dargestellten Ereignisse als Teil eines gemeldeten Bewertungsproblems angezeigt werden.
5ms ModuleA!Function1
5ms ModuleA!Function2
5ms ModuleA!Function3
|
4ms |-ModuleA!Function4
4ms | ModuleB!Function1
| |
1ms | |-ModuleB-Function2
1ms | | ModuleB-Function3
| |
3ms | |-ModuleB!Function3
3ms | ModuleB!Function4
|
1ms |-ModuleA!Function5
1ms ModuleC!Function1
1ms ModuleC!Function2
Der <itself> Knoten in einem Stapel stellt die Zeit dar, zu der sich eine Funktion selbst am oberen Rand des Stapels befindet. Der <itself> Knoten enthält nicht die Zeit, die in Funktionen verbracht wird, die von der übergeordneten Funktion aufgerufen werden. Diese Dauer wird als exklusive Zeit bezeichnet, die in der Funktion verbracht wird.
Beispielsweise ruft Function1 Function2 auf. Funktion2 hat 2ms in einer CPU-intensiven Schleife verbracht und eine andere Funktion aufgerufen, die für 4ms ausgeführt wurde. Dies kann durch den folgenden Stapel dargestellt werden:
6ms ModuleA!Function1
|
2ms |-<itself>
4ms |-ModuleA!Function2
4ms ModuleB!Function3
4ms ModuleB-Function4
Techniken
In diesem Abschnitt wird ein Standardansatz für die Leistungsanalyse beschrieben. Es bietet Techniken, mit denen Sie allgemeine CPU-bezogene Leistungsprobleme untersuchen können.
Leistungsanalyse ist ein vierstufiger Prozess:
Definieren Sie das Szenario und das Problem.
Identifizieren Sie die Komponenten, die beteiligt sind, und den relevanten Zeitraum.
Aufstellen einer Hypothese, was geschehen hätte sollen
Verwenden Sie das Modell, um Probleme zu identifizieren und Stammursachen zu untersuchen.
Definieren des Szenarios und des Problems
Der erste Schritt in der Leistungsanalyse besteht darin, das Szenario und das Problem klar zu definieren. Viele Leistungsprobleme wirken sich auf Szenarien aus, die anhand von Bewertungsmetriken gemessen werden. Zum Beispiel:
Szenario 1: Eine physische Ressource wird nicht vollständig genutzt. Beispielsweise kann ein Server keine Netzwerkverbindung vollständig nutzen, da es keine Pakete schnell genug verschlüsseln kann.
Szenario 2: Eine physische Ressource wird mehr genutzt als es sein sollte. Ein System verwendet beispielsweise erhebliche CPU-Ressourcen während eines Leerlaufzeitraums, der Akkustrom verwendet.
Szenario 3: Aktivitäten werden nicht mit einer erforderlichen Rate abgeschlossen. Beispielsweise werden Frames während der Videowiedergabe verworfen, da die Frames nicht schnell genug decodiert werden.
Szenario 4: Eine Aktivität wurde verzögert. Beispielsweise hat der Benutzer Internet Explorer gestartet, aber es dauerte länger als erwartet, um eine Registerkarte zu öffnen.
Szenarien 3 und 4, da sie sich auf CPU-Ressourcen beziehen, werden in diesem Handbuch behandelt. Szenarien 1 und 2 sind außerhalb des Umfangs und nicht abgedeckt. Um diese Probleme zu analysieren, können Sie mit einer mehrdeutigen Beobachtung wie "es ist zu langsam" beginnen und zusätzliche Fragen stellen, um das Szenario und das genaue Problem zu identifizieren.
Identifizieren der Komponenten und des Zeitraums
Nachdem das Szenario und das Problem identifiziert wurden, können Sie die komponenten identifizieren, die beteiligt sind, und den Zeitraum des Interesses. Die Komponenten umfassen Hardwareressourcen, Prozesse und Threads.
Sie finden häufig den Zeitbereich des Interesses, indem Sie die zugeordnete Aktivität im Analysehandbuch identifizieren. Eine Aktivität ist ein Intervall zwischen einem Startereignis und einem Stoppereignis, das Sie in WPA auswählen und vergrößern können. Wenn eine Aktivität nicht definiert ist, können Sie den Zeitraum finden, indem Sie nach bestimmten generischen Ereignissen suchen, die dem Szenario zugeordnet sind, oder indem Sie nach Änderungen in der Ressourcenauslastung suchen, die den Anfang und das Ende eines Szenarios markieren könnte. Wenn die CPU z. B. für zwei Sekunden leer war und dann vier Sekunden voll genutzt und dann wieder für zwei Sekunden leer ist, kann die vier Sekunden der vollständigen Auslastung der Bereich für eine Ablaufverfolgung sein, die die Videowiedergabe erfasst.
Modellerstellung
Um die Ursachen eines Problems zu verstehen, müssen Sie über ein Modell verfügen, das geschehen sollte. Das Modell beginnt mit dem Problem oder einem zugeordneten Ziel für die Metrik; Beispiel: "Dieser Vorgang sollte in weniger als 5 Sekunden abgeschlossen sein."
Ein umfassenderes Modell enthält Informationen dazu, wie die Komponenten ausgeführt werden sollen. So wird beispielsweise die Kommunikation zwischen Komponenten erwartet? Welche Ressourcenauslastung ist typisch? Wie lange dauert der Betrieb in der Regel?
Informationen für das Modell finden Sie häufig im Bewertungsanalysehandbuch. Wenn diese Ressource nicht verfügbar ist, können Sie eine Ablaufverfolgung aus ähnlicher Hardware und Software erstellen, die das Leistungsproblem nicht aufweist, um ein Modell zu erstellen.
Verwenden Des Modells zum Identifizieren von Problemen und anschließendes Untersuchen von Ursachen
Nachdem Sie ein Modell haben, können Sie eine Ablaufverfolgung mit dem Modell vergleichen, um Probleme zu identifizieren. Ein Modell für eine bestimmte Aktivität mit dem Namen "Angehaltene Geräte" kann beispielsweise vorschlagen, dass die gesamte Aktivität in drei Sekunden abgeschlossen werden sollte, während jede Instanz einer Unteraktivität namens <"Suspend Device Name>" nicht mehr als 100Ms dauern sollte. Wenn zwei Instanzen der Unteraktivität <"Angehaltene Gerätename>" jeweils 800Ms dauern, sollten Sie diese Instanzen untersuchen.
Jede Abweichung des Modells kann analysiert werden, um eine Stammursache zu finden. Sie sollten den Zustand der beteiligten Threads untersuchen und nach gängigen Stammursachen suchen. Einige wichtige CPU-bezogene Stammursachen, für Aktivitäten, die nicht mit einer erforderlichen Rate abgeschlossen werden oder verzögert werden, werden hier beschrieben:
Direkte CPU-Nutzung: Die entsprechenden Threads erhalten vollständige CPU-Ressourcen, aber das erforderliche Programm wurde nicht schnell genug ausgeführt. Dies kann durch eine Programmfehlerfunktion oder durch langsame Hardware verursacht werden.
Thread-Störungen: Ein Thread hat nicht genügend Laufzeit erhalten, da stattdessen andere Threads ausgeführt wurden. In diesem Fall gilt der Thread als ausgehungert oder vorbelastet.
DPC/ISR-Störungen: Threads haben nicht genügend Laufzeit erhalten, da CPUs bei der Verarbeitung von DPCs oder ISRs beschäftigt waren.
In vielen Fällen wirkt sich eine dieser Stammursachen nicht spürbar auf den Thread aus, und der Thread verbringt die meisten seiner Zeit in einem Wartezeitzustand. In diesem Fall müssen Sie das Ereignis identifizieren und untersuchen, für das der Thread wartet. Diese rekursive Untersuchungsart wird als Wartenanalyse bezeichnet und beginnt mit der Identifizierung des kritischen Pfads.
Erweiterte Technik: Warten der Analyse und des kritischen Pfads
Eine Aktivität ist ein Netzwerk von Vorgängen, einige sequenzielle und einige parallele, die von einem Startereignis zu einem Endereignis fließen. Ein Start-/Endereignispaar in einer Ablaufverfolgung kann als Aktivität betrachtet werden. Der längste Pfad über dieses Netzwerk von Vorgängen wird als kritischer Pfad bezeichnet. Durch die Verringerung der Dauer eines Vorgangs auf dem kritischen Pfad wird die Dauer der gesamten Aktivität direkt reduziert, obwohl sie auch den kritischen Pfad ändern kann.
Abbildung 23 Aktivitätsvorgänge zeigt die Aktivität von drei Threads. Thread-1 sendet das Aktivitätsstartereignis und wartet dann auf Thread-2 und Thread-3, um ihre Aufgaben abzuschließen. Thread-2 schließt zuerst seine Aufgabe ab, gefolgt von Thread-3. Wenn beide Threads ihre Aufgaben abgeschlossen haben, wird Thread-1 gelesen und das Aktivitätsereignis abgeschlossen.
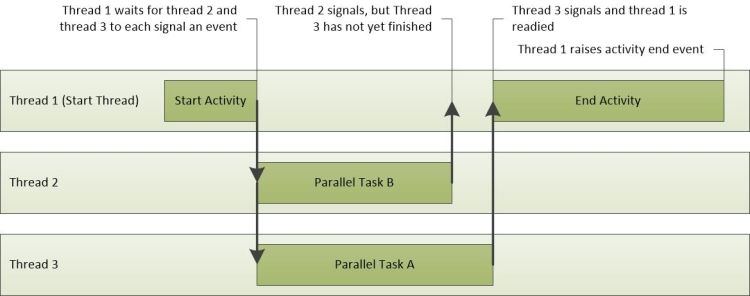
Abbildung 23 Aktivitätsvorgänge
In diesem Szenario enthält der kritische Pfad Teile von Thread-3 und Thread-1. Diese werden in Abbildung 24 Kritischer Pfad nachverfolgt. Da Thread-2 sich nicht auf dem kritischen Pfad befindet, wirkt sich die Zeit, die es benötigt, um seine Aufgabe abzuschließen, nicht auf die Gesamtaktivitätszeit aus.
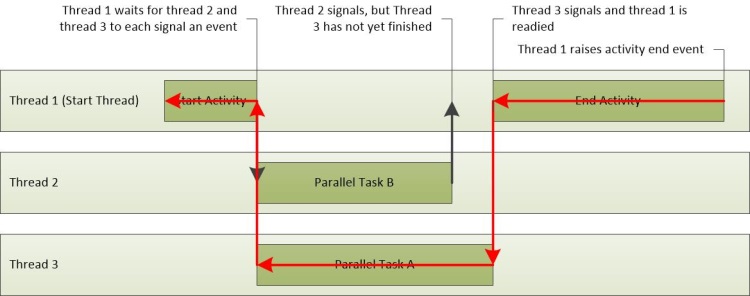
Abbildung 24 kritischer Pfad
Der kritische Pfad ist eine Literalantwort mit niedriger Ebene, um zu fragen, warum eine Aktivität so viel Zeit nahm wie es getan hat. Nachdem wichtige Segmente des kritischen Pfads bekannt sind, können sie analysiert werden, um die Probleme zu finden, die zur Gesamtverzögerung beitragen.
Allgemeiner Ansatz zum Suchen des kritischen Pfads
Der erste Schritt zum Ermitteln des kritischen Pfads besteht darin, das Szenariomodell zu überprüfen, um den Zweck und die Implementierung der Aktivität zu verstehen.
Das Verständnis einer Aktivität kann dazu beitragen, bestimmte Vorgänge, Prozesse und Threads zu identifizieren, die sich möglicherweise auf dem kritischen Pfad befinden. Beispielsweise kann eine Verzögerung im Schnellstart-Fortsetzen-Explorer Init-Aktivität durch RunOnce-Anwendungen und den Explorer-Initialisierungsprozess verursacht werden, die beide eine erhebliche Menge an I/O erfordern.
Nachdem Sie das Szenariomodell überprüft haben, überprüfen Sie, ob die Bewertung Probleme für die betroffene Aktivität gemeldet hat. Viele Male wird eine Näherung des kritischen Pfads in bewertungsbemeldete Verzögerungsprobleme eingeschlossen. Der kritische Pfad wird als Sequenz von Warten und bereiten Aktionen angezeigt. Es kann von Anfang bis Ende als Sequenz von Ereignissen gelesen werden, wobei das primäre verzögerte Segment des kritischen Pfads in der Mitte der Liste enthalten ist. Der letzte Eintrag in der Liste ist die Aktion, die den Thread gelesen hat, der die Aktivität abgeschlossen hat.
Wenn Sie manuell nach dem kritischen Pfad suchen müssen, empfehlen wir Ihnen, den Prozess und den Thread zu identifizieren, der die Aktivität abgeschlossen hat und rückwärts arbeitet, sobald die Aktivität abgeschlossen wurde. Sie können den Prozess und den Thread identifizieren, der eine Aktivität gestartet hat, und den Prozess und den Thread, der eine Aktivität abgeschlossen hat, über das Aktivitätsdiagramm in WPA.
Das Aktivitätsdiagramm zeigt an, wenn die Ablaufverfolgung über eine XML-Datei zur Bewertungsergebnisse geladen wird. Um den Prozess und den Thread zu identifizieren, der einer bestimmten Aktivität zugeordnet ist, erweitern Sie das Diagramm auf die Aktivität des Interesses, und wechseln Sie dann zur Ansicht "Graph +Tabelle". Legen Sie den Diagrammmodus auf "Tabelle" fest. Die Spalten "Start", "Thread-ID", " End-Thread-ID" und " Endthread-ID " werden für jede Aktivität in der Tabelle angezeigt.
Nachdem Sie den Start- und Endprozess kennen, den Thread und die Implementierung der Aktivität, kann der kritische Pfad rückwärts nachverfolgt werden. Beginnen Sie mit der Analyse des Threads, der die Aktivität abgeschlossen hat, um zu bestimmen, wie dieser Thread die meisten Zeit verbracht hat: Ausführen, Bereit oder Warten.
Erhebliche Laufzeit gibt an, dass die direkte CPU-Nutzung möglicherweise zur Dauer des kritischen Pfads beigetragen hat. Zeit, die im bereiten Modus verbracht wurde, gibt an, dass andere Threads zur Dauer des kritischen Pfads beitragen, indem sie verhindern, dass ein Thread auf dem kritischen Pfad ausgeführt wird. Im Status Wartet verbrachte Zeit deutet darauf hin, dass der aktuelle Thread auf E/A-Vorgänge, Timer oder andere Threads und Prozesse im kritischen Pfad wartet.
Jeder Thread, der den aktuellen Thread gelesen hat, ist wahrscheinlich ein weiterer Link im kritischen Pfad und kann auch analysiert werden, bis die Dauer des kritischen Pfads berücksichtigt wird.
Prozedur: Suchen des kritischen Pfads in WPA
Im folgenden Verfahren wird davon ausgegangen, dass Sie eine Aktivität im Aktivitätsdiagramm identifiziert haben, für die Sie den kritischen Pfad finden möchten.
Sie können den Prozess identifizieren, der die Aktivität abgeschlossen hat, indem Sie auf die Aktivität im Aktivitätsdiagramm zeigen.
Fügen Sie das CPU-Nutzungsdiagramm (Präzise) hinzu. Zoomen Sie auf die betroffenen Aktivitäten, und wenden Sie die Auslastung nach Prozess, Thread-Voreinstellung an.
Klicken Sie mit der rechten Maustaste auf die Spaltenüberschriften, und machen Sie die Spalten ReadyThreadStack und CPU-Nutzung (MS) sichtbar. Entfernen Sie die Spalten Ready (us) [Max] und Waits (us) [Max].
Erweitern Sie den Zielprozess, und sortieren Sie sie entsprechend nach CPU-Nutzung (ms), Ready (us) [Summe], und Warten (us) [Summe].
Suchen Sie im Prozess nach den NewThreadIds , die die höchste Zeit in "Ausführen", "Bereit" oder "Warten" verbracht haben.
Threads, die erhebliche Zeit in den Status "Ausführen" oder "Bereit" verbringen, stellen möglicherweise die direkte CPU-Nutzung auf dem kritischen Pfad dar. Beachten Sie, dass ihre Thread-IDs.Threads, die erhebliche Zeit im Wartenstatus verbringen, möglicherweise auf I/O, einen Zeitgeber oder auf einem anderen Thread im kritischen Pfad warten.
Um zu ermitteln, was die Threads warten, erweitern Sie die NewThreadId-Gruppe , um das ReadyThreadStack anzuzeigen.
Erweitern Sie [Stamm].
Stapel, die mit KiDispatchInterrupt beginnen, sind nicht mit einem anderen Thread verknüpft. Um zu ermitteln, was der Thread in diesen Stapeln wartet, erweitern Sie KiDispatchInterrupt , und zeigen Sie die Funktionen im untergeordneten Stapel an. IopfCompleteRequest gibt an, dass der gelesene Thread auf I/O wartet. KiTimerExpiration gibt an, dass der gelesene Thread auf einen Zeitgeber wartet.
Erweitern Sie Stapel, die nicht mit KiDispatchInterrupt beginnen, bis Sie einen ReadyingProcess und ein ReadyingThread sehen. Wenn der Prozess bereits erweitert wird, erweitern Sie die NewThreadId , die dem ReadyingThread entspricht. Wiederholen Sie diesen Schritt, bis Sie einen Thread finden, der ausgeführt, bereit ist, aus einem anderen Grund warten oder auf einen anderen Prozess warten. Wenn der Thread auf einen anderen Prozess wartet, wiederholen Sie diese Prozedur mithilfe dieses Prozesses.
Beispiel
In diesem Beispiel wird eine Verzögerung im Schnellstart-Fortsetzen-Explorer Init-Aktivität angezeigt. Eine Suche im Bereich "Probleme " zeigt, dass sieben Verzögerungstypprobleme für diese Aktivität gemeldet werden. Jede dieser Probleme kann als Segment des kritischen Pfads überprüft werden. Die folgenden Schlüsselsegmente werden identifiziert:
Thread 3872 des Prozesses TestBootStrapper.exe (3024) wird für 2,1 Sekunden vorgeempt.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) verwendet 1 Sekunde CPU-Zeit.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) löscht eine Registrierungsstruktur für 544 Millisekunden.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) wird für 513 Millisekunden geschlafen.
Threads 4052 und 4036 von Explorer.exe von Datenträger gelesen, wodurch eine 461 Millisekundenverzögerung verursacht wird.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) sternt für 187 Millisekunden.
Thread 3872 von Prozess TestBootStrapper.exe schreibt 3,5 MB auf datenträger, wodurch eine Verzögerung von 178 Millisekunden verursacht wird.
Die Probleme zeigen, dass diese Aktivität um 5,2 Sekunden verzögert wurde. Diese Verzögerungen tragen einen großen Anteil der Aktivitäten insgesamt 6,3 Sekunden lang bei. Die TestBootStrapper.exe-Anwendung ist hauptsächlich für die Verzögerung verantwortlich, hauptsächlich weil sie andere Verarbeitungsaufgaben vorbesetzte.
Untersuchen von Problemen im kritischen Pfad
Vergrößern Sie den betroffenen Bereich, und fügen Sie die Spalten "ReadyThreadStack " und " CPU-Nutzung" (ms) hinzu.
In diesem Fall ist Explorer.exe der Prozess, der die Aktivität abgeschlossen. Erweitern Sie den explorer.exe Prozess, und sortieren Sie sie entsprechend nach CPU-Nutzung (ms), Ready (us) [Summe], und Waits (us) [Summe], wie in den folgenden Abbildungen dargestellt:

Abbildung 25 Aktivität nach CPU-Nutzung (ms)

Abbildung 26 Aktivität nach Ready (us)

Abbildung 27 Aktivität durch Warten (us)
Die Sortierung nach der Spalte CPU-Nutzung (MS) zeigt eine obere untergeordnete Zeile von 299 Millisekunden an. Die Sortierung nach der Spalte "Bereit" (us) [Summe] zeigt eine obere untergeordnete Zeile von 46Ms an. Die Sortierung nach der Spalte "Waits" (us) [Summe] zeigt eine obere untergeordnete Zeile von 5749 Millisekunden und eine zweite Zeile von 4902 Millisekunden an. Da diese Zeilen erheblich zur Verzögerung beitragen, sollten Sie sie weiter untersuchen.
Erweitern Sie die Stapel, um die bereitstehenden Threads anzuzeigen, wie in den folgenden Abbildungen gezeigt:
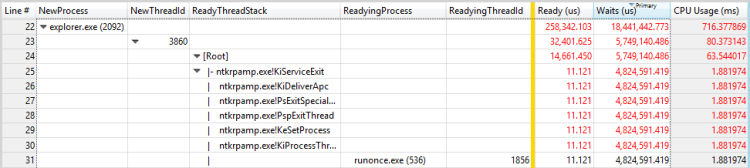
Abbildung 28 Vorbereiten des Prozesses und bereiter Thread für einen Thread
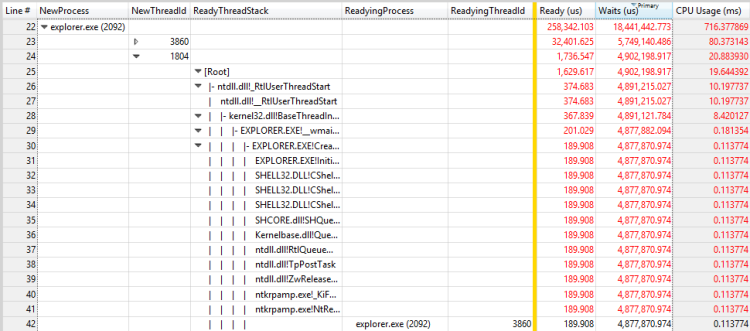
Abbildung 29 Fertigungsprozess und Bereitungsthread für einen anderen Thread
In diesem Beispiel verbringt der erste Thread die meisten zeitlangen Wartezeiten für den RunOnce.exe Prozess zum Beenden. Sie sollten untersuchen, warum der RunOnce.exe Prozess so viel Zeit benötigt, um fertig zu sein. Der zweite Thread wartet auf den ersten Thread und ist wahrscheinlich ein unbedeutender Link in derselben Wartenkette.
Wiederholen Sie die Schritte in dieser Prozedur für RunOnce.exe. Die primäre Beitragsspalte ist Waits (us), und es hat vier mögliche Mitwirkende.
Erweitern Sie jeden Mitwirkenden, um zu sehen, dass die ersten drei Mitwirkenden auf den vierten Mitwirkenden warten. Diese Situation macht die ersten drei Mitwirkenden für die Wartenkette unbedeutend. Der vierte Mitwirkende wartet auf einen anderen Prozess, TestBootStrapper.exe.
Dieses Szenario wird in Abbildung 30 Bereitungsprozess und Bereitungsthread für einen Thread in RunOnce.exe angezeigt:
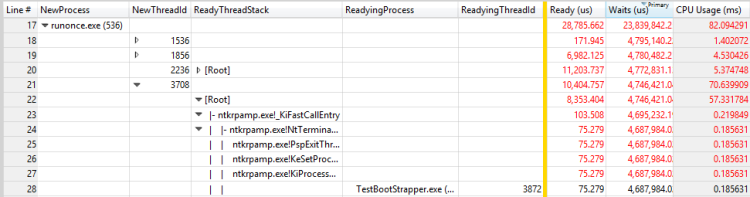
Abbildung 30 Fertigungsprozess und Bereitungsthread für einen Thread in RunOnce.exe
Wiederholen Sie die Schritte in dieser Prozedur für TestBootStrapper.exe. Die Ergebnisse werden in den folgenden drei Zahlen gezeigt:

Abbildung 31 Threads nach CPU-Verwendung (ms)

Abbildung 32 Threads nach Bereit (us)

Abbildung 33 Threads nach Warten (us)
Thread 3872 hat ungefähr 1 Sekunde ausgeführt, 2 Sekunden bereit und 1,3 Sekunden warten. Da dieser Thread auch der bereite Thread für Thread 3872 ist, tragen die Ausführungs- und Bereitzeiten wahrscheinlich zur Verzögerung bei. Die Bewertung meldet die folgenden Probleme, deren Zeiten mit den Verzögerungen übereinstimmen:
Thread 3872 des Prozesses TestBootStrapper.exe (3024) wird für 2,1 Sekunde vorgeempt.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) sternt für 187 Millisekunden.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) verwendet 1 Sekunde CPU-Zeit.
Um andere Probleme zu finden, zeigen Sie das Ereignis an, für das thread 3872 wartet. Erweitern Sie ReadyThreadStack , um Mitwirkende auf die 1,3 Sekunden wartezeit anzuzeigen, wie in Abbildung 34 Mitwirkende zur Wartezeit dargestellt:

Abbildung 34 Mitwirkende zur Wartezeit
KiRetireDpcList ist in der Regel I/O-bezogene und KiTimerExpiration ist ein Zeitgeber. Sie können sehen, wie der I/Os- und Timer initiiert wurden, indem Sie den ReadyThreadStack entfernen und dann den NewThreadStack anzeigen. Diese Ansicht zeigt drei verwandte Funktionen, wie in Abbildung 35 I/Os und Timer auf NewThreadStack dargestellt:

Abbildung 35 I/Os und Timer auf NewThreadStack
Diese Ansicht gibt die folgenden Details offen:
Thread 3872 des Prozesses TestBootStrapper.exe (3024) löscht eine Registrierungsstruktur für 544 Millisekunden.
Thread 3872 des Prozesses TestBootStrapper.exe (3024) wird für 513 Millisekunden geschlafen.
Thread 3872 von Prozess TestBootStrapper.exe schreibt 3,5 MB auf Datenträger, wodurch eine Verzögerung von 178 Millisekunden verursacht wird.
Wenn Sie mit der Untersuchung des kritischen Pfads begonnen haben, analysierten Sie die wichtigste Wartenursache in Explorer.exe und ignorierten alle Teile des kritischen Pfads, der nach dieser Wartezeit aufgetreten ist. Um diesen zuvor ignorierten Abschnitt des kritischen Pfads zu erfassen, müssen Sie sich die Zeitachse ansehen. Fügen Sie die CPU-Verwendung (Präzise) hinzu, und wenden Sie die Zeitachse nach Prozess, Thread-Voreinstellung an.
Filter, um nur die prozesse einzuschließen, die als Teil des kritischen Pfads identifiziert werden. Das resultierende Diagramm wird in Abbildung 36 Kritische Pfadzeitachse angezeigt:

Abbildung 36 Kritische Pfadachse
Abbildung 36 Kritische Pfadzeitachse zeigt, dass Explorer.exe mehr Arbeit ausgeführt haben, nachdem sie nicht mehr auf RunOnce.exe wartet. Vergrößern Sie den Zeitraum nach der zuvor analysierten Wartenkette, und führen Sie eine weitere Analyse aus. In diesem Fall zeigt die Analyse eine große Anzahl von Threads an, die für Explorer.exe intern sind und keine klare Ablaufverfolgung durch den kritischen Pfad. In diesem Fall ist eine weitere Analyse nicht wahrscheinlich, dass aktionenbare Einblicke erzielt werden.
Direkte CPU-Nutzung
Aktivitäten werden häufig verzögert, da ein Thread im kritischen Pfad erhebliche CPU-Zeit verwendet. Mithilfe des Threadstatusmodells können Sie sehen, dass dieses Problem durch einen Thread auf dem kritischen Pfad gekennzeichnet ist, der eine außergewöhnliche Zeit im Ausführungszustand ausgibt. Bei einigen Hardware kann diese schwere CPU-Nutzung zu Verzögerungen beitragen.
Problemerkennung
Viele Bewertungen verwenden Heuristiken, um direkte CPU-Nutzungsprobleme zu identifizieren. Die erhebliche CPU-Nutzung auf dem kritischen Pfad wird als Problem in folgendem Formular gemeldet:
CPU-Verwendung durch Prozess P verzögert die beeinträchtigte Aktivität A für x Sekunden
Wo P der Prozess ist, der ausgeführt wird, ist A die Aktivität und x ist die Zeit in Sekunden.
Wenn diese Probleme für eine Aktivität gemeldet werden, die Verzögerungen verursacht, kann die direkte CPU-Nutzung die Ursache sein.
Untersuchen der direkten CPU-Nutzung
Sie können das Problem manuell identifizieren, indem Sie nach einzelnen CPUs suchen, die 100 % CPU-Nutzung in der CPU-Nutzung (Beispiel) -Diagramm verursachen.
Zoomen Sie auf einen Bereich des Interesses im Diagramm, und wählen Sie die Verwendung durch Prozess und Thread-Voreinstellung aus.
Standardmäßig zeigt die Tabelle Zeilen oben an, die die höchste Aggregat-CPU-Nutzung aufweisen. Diese Threads werden auch am oberen Rand des CPU-Nutzungsdiagramms (Beispiel) angezeigt.
Hinweis Auf einem System mit mehreren Prozessoren scheint ein Thread, der 100 % eines einzelnen Prozessors verwendet, 100/(Anzahl der logischen Prozessoren) zu verwenden. Auf dieser Art von System kann nur der virtuelle Leerlaufthread (PID 0, TID 0) eine größere Prozessorauslastung als 100/(Anzahl der logischen Prozessoren) anzeigen. Wenn die Prozesse und Threads, die die meisten CPU nutzen, alle Threads im kritischen Pfad entsprechen, ist die direkte CPU-Nutzung wahrscheinlich ein Faktor.
Beispiel für Assessment-Reported Direkte CPU-Nutzungsproblem
Die CPU-Verwendung durch den TestUM.exe-Prozess (4024) verzögert die betroffene Aktivität, den schnellen Startvorgang TestIM.exe für 2,1 Sekunden. In diesem Beispiel wird in Abbildung 37 Thread 3208 gezeigt:
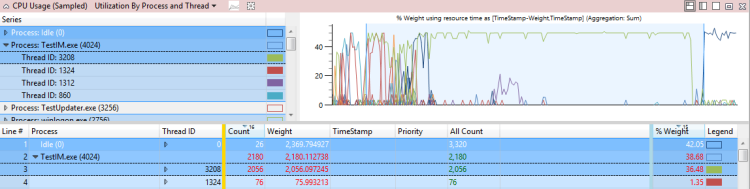
Abbildung 37 Thread 3208
Untersuchung
Nachdem Sie feststellen, dass die direkte CPU-Nutzung zu einer Verzögerung auf dem kritischen Pfad beiträgt, müssen Sie die spezifischen Module und Funktionen identifizieren, die zur Verzögerung beitragen.
Technik: Überprüfen eines Assessment-Reported Direkte CPU-Nutzungsproblems
Sie können ein problem mit der Bewertung gemeldeten direkten CPU-Nutzung erweitern, um den kritischen Pfad anzuzeigen, der durch die direkte CPU-Nutzung beeinflusst wird. Wenn Sie den Knoten erweitern, der der CPU-Nutzung zugeordnet ist, werden die Stapel angezeigt, die dem CPU-Einsatz und zugeordneten Modulen zugeordnet sind. Diese Ansicht wird in Abbildung 38 Erweiterter CPU-Nutzungssegment angezeigt:
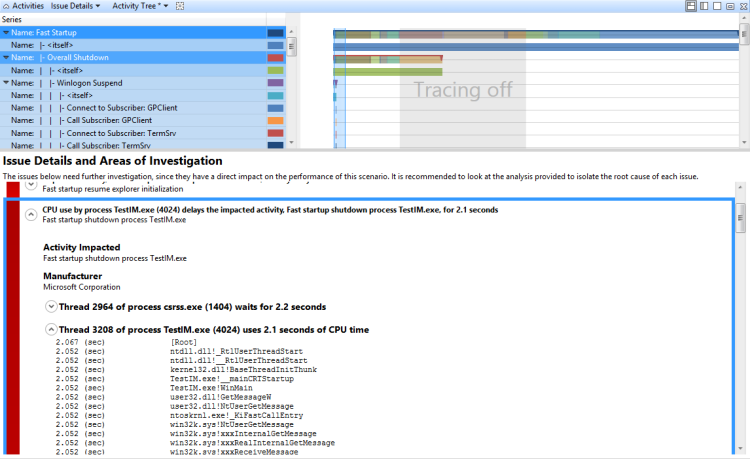
Abbildung 38 Erweiterte CPU-Nutzungssegment
Technik: Manuell erkunden Sie die Stapel einer direkten CPU-Nutzungsproblem
Wenn die Bewertung kein Problem meldete, oder wenn Sie zusätzliche Überprüfungen benötigen, können Sie mithilfe des CPU-Nutzungsdiagramms (Beispiel) Informationen zu den Modulen und Funktionen, die an einem CPU-Nutzungsproblem beteiligt sind, manuell sammeln. Dazu müssen Sie den Bereich des Interesses vergrößern und die Stapel anzeigen, die nach CPU-Nutzung sortiert sind.
Manuell erkunden Sie die Stapel einer direkten CPU-Nutzungsproblem
Klicken Sie im Menü Ablaufverfolgung auf Symbole laden.
Zoomen Sie die Zeitachse, um nur den Teil des kritischen Pfads anzuzeigen, der von dem CPU-Problem betroffen ist.
Anwenden der Auslastung nach Prozess- und Thread-Voreinstellung .
Fügen Sie die Stapelspalte zur Anzeige hinzu, und ziehen Sie diese Spalte dann rechts neben der Thread-ID (links der Leiste).
Erweitern Sie den Prozess und den Thread, um die Stapelbäume anzuzeigen.
Die Zeilen im Stapel werden in absteigender Reihenfolge nach % der CPU-Nutzung sortiert. Dadurch werden die interessantesten Stapel oben platziert. Wenn Sie die Stapel erweitern, schauen Sie sich die Spalte % Gewicht an, um sicherzustellen, dass der Fokus auf den Zeilen bleibt, die die höchste Verwendung haben.
Wenn Sie eine Kopie des Stapels extrahieren möchten, wählen Sie alle Zeilen aus, klicken Sie mit der rechten Maustaste, und klicken Sie auf "Auswahl kopieren".
Lösung
Sie können Sowohl die Konfigurations- als auch die Komponentenebenen verwenden, um eine hohe CPU-Nutzung zu beheben.
Die direkte CPU-Nutzung hat höhere Auswirkungen auf Computer, die untere End-Prozessoren haben. In diesen Fällen können Sie dem Computer weitere Verarbeitungsleistung hinzufügen. Oder Sie können die Problemmodule möglicherweise aus dem kritischen Pfad oder aus dem System entfernen. Wenn Sie die Komponenten ändern können, sollten Sie einen der folgenden Ergebnisse in Betracht ziehen:
Entfernen des CPU-intensiven Codes aus dem kritischen Pfad
Verwenden von effizienteren CPU-Algorithmen
Zurückstellen oder Cachearbeit
Thread-Störungen
Die CPU-Verwendung durch Threads, die nicht auf dem kritischen Pfad sind (und die möglicherweise nicht mit der Aktivität verknüpft sind), können Threads verursachen, die auf dem kritischen Pfad verzögert werden. Das Threadstatusmodell zeigt, dass dieses Problem durch Threads auf dem kritischen Pfad gekennzeichnet ist, die eine ungewöhnliche Zeit im Bereit-Zustand verbringen.
Problemerkennung
Viele Bewertungen verwenden Heuristiken, um störungenbezogene Probleme zu identifizieren. Diese werden in einem der folgenden beiden Formulare gemeldet:
Prozess P ist ausgehungert. Die Starvation verursacht eine Verzögerung der betroffenen Aktivität A von x ms.
Der Prozess P wird vorgebeutet. Die Voreinsicht verursacht eine Verzögerung der betroffenen Aktivität A von x ms.
Wo P der Prozess ist, ist A die Aktivität und x ist die Zeit in ms.
Das erste Formular spiegelt die Störung von Threads auf derselben Prioritätsebene wie den Thread auf dem kritischen Pfad wider. Das zweite Formular spiegelt Störungen von Threads wider, die auf einer höheren Prioritätsebene sind als der Thread auf dem kritischen Pfad.
Wenn diese Arten von Problemen für eine verzögerte Aktivität gemeldet werden, kann Thread-Störungen die Ursache sein. Sie können das CPU-Nutzungsdiagramm (Präzise) verwenden, um das Problem manuell zu identifizieren.
Identifizieren von Thread-Störungen
Vergrößern Sie das Intervall, und wenden Sie die Auslastung nach CPU-Voreinstellung an. Eine Auslastung von 100 % in allen CPUs gibt ein Störungsproblem an.
Wenden Sie die Auslastung nach Prozess, Thread vor und sortieren Sie nach der ersten Spalte "Bereit" (us). (Dies ist die Spalte, die die Summenaggregation enthält.)
Erweitern Sie den Prozess der Aktivität, die betroffen ist, und schauen Sie sich die Bereitzeit für Threads auf dem kritischen Pfad an. Dieser Wert ist die maximale Zeit, mit der die Verzögerung reduziert werden kann, indem sie ein Problem mit Thread-Störungen auflösen. Ein Wert mit einer Größe, die relativ zur untersuchungsbezogenen Verzögerung erheblich ist, gibt an, dass ein Thread-Störungsproblem vorhanden ist.
Abbildung 39 CPU-Auslastung ist in der Nähe von 100 % und Abbildung 40 Thread-Störungsproblem dieses Szenarios:

Abbildung 39 CPU-Auslastung ist in der Nähe von 100 %
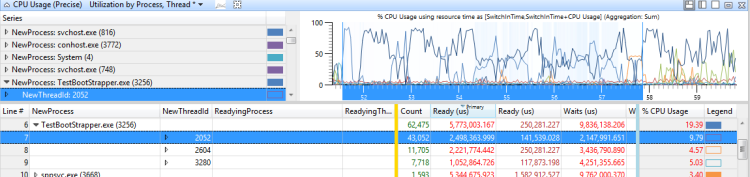
Abbildung 40 Thread-Störungenproblem
Untersuchung
Nachdem das Problem identifiziert wurde, müssen Sie bestimmen, warum der betroffene Thread so viel Zeit im Status "Bereit" verbracht hat.
Technik: Ermitteln, warum ein Thread zeit im Bereit-Zustand verbracht hat
Sie können das CPU-Nutzungsdiagramm (Präzise) verwenden, um zu bestimmen, warum ein Thread Zeit im Bereit-Zustand verbracht hat. Sie müssen zunächst bestimmen, ob der Thread auf bestimmte Prozessoren beschränkt ist. Obwohl Sie diese Informationen nicht direkt abrufen können, können Sie den CPU-Nutzungsverlauf eines Threads während der Zeiträume hoher CPU-Auslastung untersuchen. Dies ist der Zeitraum, in dem Threads häufig zwischen Prozessoren wechseln.
Ermitteln der Einschränkungen des Prozessors eines Threads
Zoomen Sie auf den betroffenen Bereich.
Fügen Sie das CPU-Nutzungsdiagramm (Präzise) hinzu, und wenden Sie die Auslastung nach Prozess, Thread-Voreinstellung an.
Verwenden Sie das Dialogfeld "Erweitert", um eine Cpu-Spalte hinzuzufügen, die rechts neben NewThreadId einen Eindeutigen Count-Aggregationsmodus aufweist.
Filtern Sie das Diagramm, um nur die Threads anzuzeigen, in denen Sie interessiert sind.
Der Wert in der Cpu-Spalte spiegelt die Anzahl der Prozessoren wider, auf denen der Thread während des aktuellen Zeitintervalls ausgeführt wurde. In Zeiträumen von 100 % CPU-Auslastung ungefährt diese Zahl die Anzahl der Prozessoren, auf denen dieser Thread ausgeführt werden darf. Wenn der Wert kleiner als die Anzahl der verfügbaren Prozessoren ist, ist der Thread wahrscheinlich auf bestimmte CPUs beschränkt.
Abbildung 41 Eingeschränkte Threads bietet ein Beispiel für dieses Diagramm:
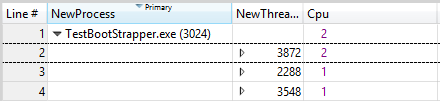
Abbildung 41 eingeschränkte Threads
Nachdem Sie die Prozessoreinschränkungen eines Threads kennen, können Sie bestimmen, welche Vor- oder Ausgehunger des Threads vorgesetzt wurden. Dazu müssen Sie die Intervalle identifizieren, die der Thread im Bereit-Zustand verbracht hat, und überprüfen Sie dann, welche anderen Threads oder Prozesse während dieser Intervalle ausgeführt wurden.
Bestimmen Sie, welche Vorbeeinstande oder Starved the Thread
Erstellen Sie ein Diagramm, das anzeigt, wann der Thread im Bereit-Zustand war und die Auslastung nach Prozess anwenden, Thread-Voreinstellung .
Öffnen Sie den Ansichts-Editor, klicken Sie auf "Erweitert", und wählen Sie die Registerkarte " Graphkonfiguration " aus.
Legen Sie die Startzeit auf ReadyTime (s) fest, und legen Sie die Dauer auf Bereit (us), wie in Abbildung 42 Bereitzeitspalten dargestellt. Klicken Sie auf OK.

Abbildung 42 Bereitzeitspalten
Ersetzen Sie im Ansichts-Editor die CPU-Verwendungsspalte (%) durch die Spalte "Bereit" (us) [Summe] .
Wählen Sie den Thread des Interesses aus, um ein Diagramm zu erstellen, das ähnlich wie Abbildung 43 Bereitzeitdiagramm ist:

Abbildung 43 Zeitdiagramm
In diesem Fall hat der Thread erhebliche Zeit im Bereit-Zustand verbracht. Um die typische Priorität zu bestimmen, fügen Sie derSpalte "NewInPri " eine Durchschnittliche Aggregation hinzu.
In diesem Fall ist die durchschnittliche Priorität des Threads genau 8. Diese Zahl gibt an, dass es wahrscheinlich ein Hintergrundthread ist, der nie Prioritätserhöhungen erhält.
Nachdem die durchschnittliche Priorität bekannt ist, sehen Sie sich die CPU-Aktivität für die CPUs an, auf denen der Thread ausgeführt werden darf.
In diesem Fall wurde der Thread bestimmt, nur eine Affinität für CPU 1 zu haben.
Fügen Sie ein weiteres CPU-Nutzungsdiagramm (Präzise) hinzu, und wenden Sie die Auslastung nach CPU-Voreinstellung an. Wählen Sie den entsprechenden Gültigkeitsbereich aus.
Öffnen Sie die Erweiterte Ansicht, und fügen Sie einen Filter für die Priorität hinzu, die Sie zuvor gefunden haben, um diesen Thread auszufiltern. Dieses Szenario wird in Abbildung 44 Threadfilter angezeigt:
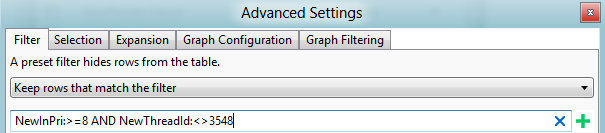
Abbildung 44 Threadfilter
In Abbildung 45 CPU-Nutzung, Bereitzeit und anderen Threadaktivitäten zeigt das obere Diagramm die CPU-Nutzung von Thread 3548 an. Das mittlere Diagramm zeigt die Zeit, zu der der Thread bereit war, und das untere Diagramm zeigt Aktivität auf den CPUs an, auf denen der Thread ausgeführt werden darf (in diesem Fall Cpu1).
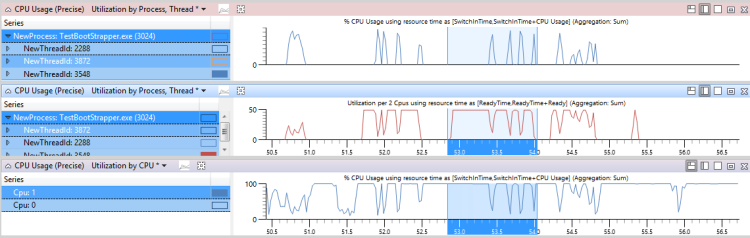
Abbildung 45 CPU-Nutzung, Bereitzeit und andere Threadaktivität
Zoomen Sie in einen Bereich, in dem der Thread bereit war, aber nicht ausgeführt wurde, für die meisten Zeit während dieses Intervalls.
Fügen Sie im CPU-NutzungsdiagrammNewInPri links neben der Leiste hinzu, und untersuchen Sie die Ergebnisse.
Threads oder Prozesse, die Prioritäten aufweisen, die der Priorität des Zielthreads entsprechen, zeigen die Uhrzeit an, zu der der Thread ausgehungert wurde. Threads oder Prozesse, die höhere Priorität haben als die Zielthreadpriorität, zeigen die Uhrzeit an, zu der der Thread vorgebestanden wurde. Sie können die Gesamtzeit berechnen, für die der Thread vorgedracht wurde, indem Sie die Zeiten aller präemptiven Threads und Aktionen hinzufügen.
Abbildung 46 Verwendung nach Priorität Beim Vorbereiten des Zielthreads wird gezeigt, dass 730ms der Threadzeit vorgerückt wurden, und 300Ms der Threadzeit wurden ausgehungert. (Diese Abbildung wird auf ein Intervall von 1192ms vergrößert.)
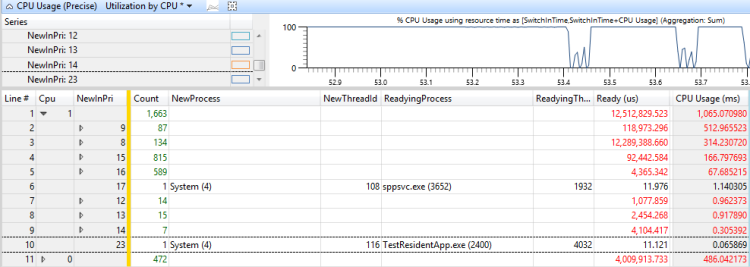
Abbildung 46 Verwendung nach Priorität, wenn Zielthread bereit war
Um zu ermitteln, welche Threads für die Vorabsetzung und die Starvation dieses Threads verantwortlich sind, fügen Sie die Spalte "NewProcess " rechts neben der Spalte "NewInPri " hinzu, und überprüfen Sie die Prioritätsebenen, auf denen Prozesse ausgeführt wurden. In diesem Fall wurden die Vorbeeinigung und die Starvation hauptsächlich durch einen anderen Thread im gleichen Prozess und durch TestResidentApp.exe verursacht. Sie können davon ausgehen, dass diese Prozesse regelmäßige Prioritätserhöhungen über ihrer Basispriorität erhalten.
Lösung
Sie können Vor- oder Hungerprobleme beheben, indem Sie die Konfiguration oder Komponenten ändern. Berücksichtigen Sie die folgenden Abhilfemaßnahmen:
Entfernen Sie die problematischen Prozesse aus dem System.
Passen Sie die Basispriorität der problematischen Prozesse an...
Ändern Sie den Zeitpunkt, zu dem die problematischen Prozesse ausgeführt werden; Beispielsweise verzögern Sie ihre Startzeit, wenn der Computer neu gestartet wird.
Wenn die Problemkomponenten geändert werden können, gestalten Sie sie so neu, dass sie weniger CPU-intensiv sind oder bei niedrigerer Priorität ausgeführt werden sollen.
DPC/ISR-Störungen
Wenn übermäßige Prozessorzeit durch Ausführen von DPCs und ISRs verbraucht wird, ist möglicherweise nicht genügend CPU-Zeit verfügbar, um Threads auszuführen. Diese Situation kann zu ähnlichen Verzögerungen bei Thread-Störungen führen. Wenn Threads Vorgänge mit einer regelmäßigen hohen Häufigkeitsrate ausführen müssen, z. B. in der Videowiedergabe oder Animation, können Störungen durch DPCs und ISRs operative Probleme verursachen.
Problemerkennung
Viele Bewertungen verwenden Heuristiken, um DPC/ISR-verwandte Probleme zu identifizieren. DPC/ISR-Aktivität wird als verdächtiger identifiziert, wenn es als Problem in der folgenden Form gemeldet wird:
DPC D überschreitet den Schwellenwert von m Millisekunden x Mal während P. Die n-Instanzen dieses DPC werden für eine kombinierte Gesamtsumme von t Millisekunden ausgeführt.
Wenn D der DPC ist, ist m die Anzahl der Millisekunden, die den Schwellenwert festlegen, x ist die Anzahl der Zeiten, die der DPC den Schwellenwert überschritten hat, P ist der aktuelle Prozess, n ist die Anzahl der Instanzen, die der DPC ausgeführt hat, und nicht die Gesamtzeit in Millisekunden, die der DPC über den Schwellenwert ausgeführt hat.
Beispielsweise wird das folgende Problem durch eine Bewertung gemeldet:
DPC sdbus.sys! SdbusWorkerDpc überschreitet das Ziel von 3,0 Millisekunden 153 Mal während der Media Engine-Lebensdauer. Die 153 Instanzen dieses DPC führen insgesamt 864 Millisekunden aus.
Wenn dieses Problem für eine Aktivität gemeldet wird, die Problemereignisse oder Verzögerungen anzeigt, kann die DPC/ISR-Aktivität die Ursache sein.
Manuelles Identifizieren von DPC/ISR-Störungen
Um DPC/ISR-Störungen manuell zu identifizieren, öffnen Sie eine Ablaufverfolgung in WPA, und identifizieren Sie die Problemereignisse des Interesses. Dies sind bewertungsspezifische generische Ereignisse wie Microsoft-Windows-Dwm-Core:SCHEDULE_GLITCH oder Microsoft-Windows-MediaEngine:DroppedFrame.
Fügen Sie neben dem Diagramm der Ereignisse die DPC/ISR-Dauer nach CPU-Diagramm hinzu. Wenn Spitzen in der DPC/ISR-Dauer durch CPU-Diagramm mit den Problemereignissen ausgerichtet sind, kann DPC/ISRs ein Faktor sein, um die Probleme zu verursachen.
Vergrößern Sie für zusätzliche Daten den Zeitraum, der 100Ms auftritt, bevor mehrere Problemereignisse angezeigt werden. Wenn erhebliche DPC/ISR-Aktivität in einem oder mehreren Prozessoren im Bereich 100ms angezeigt wird, bevor die Problemereignisse aufgetreten sind, können Sie schließen, dass die Problemereignisse durch die DPC/IRS-Aktivität verursacht wurden.
Um zu ermitteln, ob DPC/ISR-Störungen zu Verzögerungen führen, zoomen Sie zu einem Bereich, der einen ausgeführten Thread anzeigt. Beachten Sie die CPU oder CPUs, auf denen dieser Thread ausgeführt wird.
Wenden Sie im DPC/ISR-Diagramm die DPC/ISR-Dauer nach CPU-Voreinstellung an, und zeigen Sie die DPC/ISR-Aktivität auf den relevanten CPUs in diesem Zeitbereich an.
Abbildung 47 Problemereignisse und DPC/ISR-Aktivität zeigt, dass Thread 864 von iexplore.exe für die betroffene Aktivität relevant ist. Thread 864 befindet sich im Ausführungszustand auf CPU2 für 10,65 % des Zeitbereichs in der Ansicht. Das DPC/ISR-Diagramm zeigt jedoch, dass CPU2 bei der Ausführung von DPC/ISRs für 10 % dieser Zeit beschäftigt war.
Hinweis Die meisten DPC/ISRs haben keine so hohe Auswirkung wie in diesem Beispiel gezeigt.
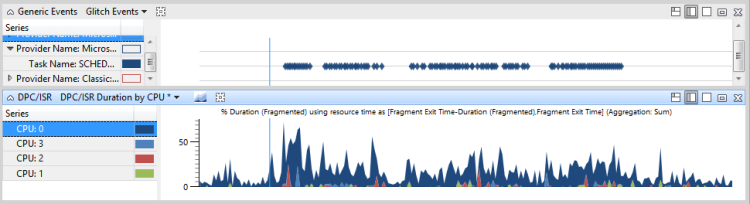
Abbildung 47 Problemereignisse und DPC/ISR-Aktivität
In Abbildung 48 DPC/ISR, die nicht mit Problemereignissen verbunden sind, werden DPC/ISRs angezeigt, die nicht mit Leistungsproblemen verbunden sind:
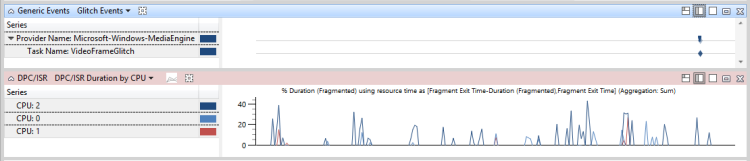
Abbildung 48 DPC/ISR nicht mit Problemereignissen verbunden
In Abbildung 49 Verzögerung, die durch DPC/ISR-Störungen verursacht wird, werden DPC/ISRs gezeigt, um Leistungsprobleme zu verursachen:
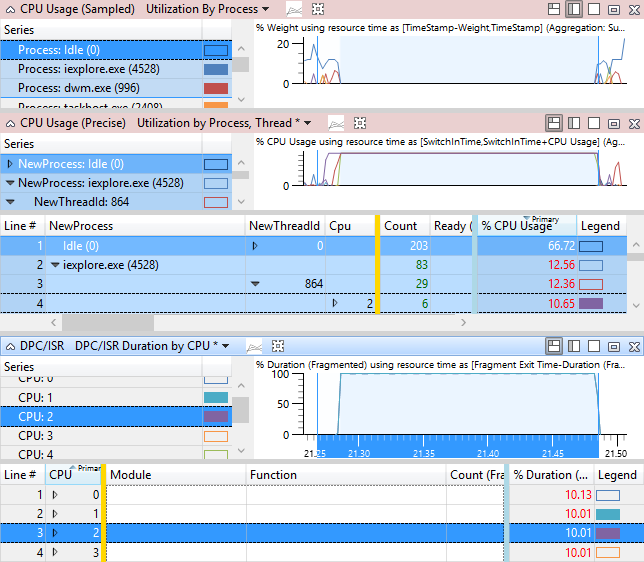
Abbildung 49 Verzögerung, die durch DPC/ISR-Störungen verursacht wurde
Untersuchung
Nachdem Sie festgestellt haben, dass DPCs/ISRs im Zusammenhang mit Problemen oder Verzögerungen stehen, müssen Sie bestimmen, welche spezifischen DPCs/ISRs beteiligt sind und warum sie häufig oder für eine übermäßige Zeit ausgeführt werden.
Technik: Überprüfen eines Assessment-Reported DPC/ISR-Problems
In der Bewertung gemeldeten DPC/ISR-Problemen können Sie das Problem erweitern, das die wichtigsten Prozesse anzeigt, die vom DPC oder ISR vorgelöst werden. Erweitern Sie den Stapel, um die DPC-Aktivität für den Prozess anzuzeigen, der am meisten mit der betroffenen Aktivität verknüpft ist, wie in der Abbildung gezeigt, erweitern Sie den Stapel, um zu verstehen, was der DPC tut. Abbildung 50 Erweiterter DPC-Stapel zeigt den erweiterten Stapel an:
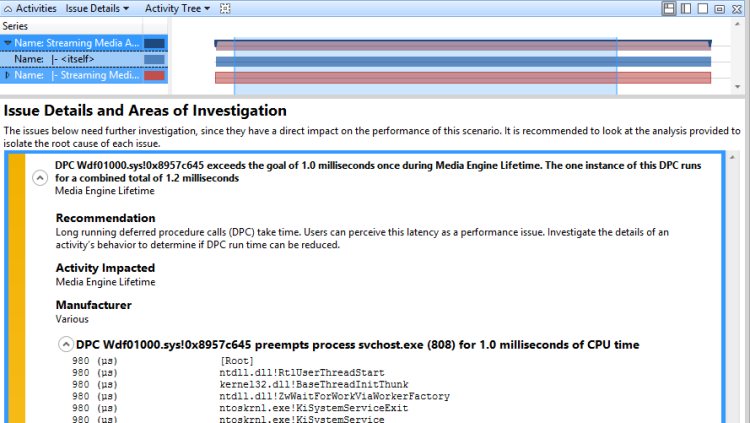
Abbildung 50 Erweiterter DPC-Stapel
Technik: Suchen Sie die höchste Dauer DPCs/ISRs und überprüfen Sie die Stapel
Wenn eine Bewertung den DPC/ISR nicht als Problem meldet, können Sie die DPC/ISR - und CPU-Nutzungsdiagramme (Beispiel) verwenden, um Stapelinformationen für die relevantesten DPCs abzurufen. Es wird empfohlen, einen DPC/ISR von Interesse zu finden, dessen Modul und Funktion zu beachten und dann die Beispiele im CPU-Nutzungsdiagramm (Beispiel) zu finden, um vollständige Stapelinformationen abzurufen.
Suchen sie nach den höchsten DPCs/ISRs und überprüfen Sie die Stapel
Vergrößern Sie das Intervall des Interesses.
Wählen Sie im DPC/ISR-Diagramm die voreingestellte DPC/ISR-Dauer nach Modul, Funktion aus.
Wenn Symbole geladen werden, werden DPC/ISR-Ereignisse nach Gesamtdauer sortiert und dann nach Modul und Funktion sortiert. Die oberen Zeilen in der Liste enthalten die DPC/ISR-Ereignisse, die wahrscheinlich die Ereignisprobleme verursacht haben. Beachten Sie die Namen des Moduls und der Funktion.
Wählen Sie im CPU-Nutzungsdiagramm (Beispiel) die Verwendung nach Prozess-Voreinstellung aus. Standardmäßig blendet diese voreingestellte DPC/ISR-Aktivität aus.
Öffnen Sie den Ansichts-Editor, und klicken Sie auf "Erweitert".
Ändern Sie auf der Registerkarte "Filter " die Zeilen ausblenden , die der Filtereinstellung entsprechen, um Zeilen beizubehalten, die dem Filter entsprechen. Dadurch können DPC/ISR-Aktivitäten angezeigt werden.
Entfernen Sie die Spalte "Prozess" , und fügen Sie die Stapelspalte hinzu, um DPCs/ISRs anzuzeigen, die nach Stapel sortiert sind.
Löschen Sie die aktuelle Zeilenauswahl.
Klicken Sie mit der rechten Maustaste auf eine Zelle in der Spalte "Stapel" , und klicken Sie dann in dieser Spalte auf "Suchen".
Geben Sie ein Modul und eine Funktion ein, die Sie in Schritt 2 dieser Prozedur aufgeführt haben.
Aktivieren Sie die aktuelle Auswahl, und klicken Sie auf "Alle suchen", um alle Instanzen der Funktion auszuwählen.
Nachdem alle Zeilen ausgewählt sind, klicken Sie mit der rechten Maustaste, und klicken Sie auf "Butterfly/View Callees".
Diese Ansicht zeigt die Aktivitäten dieser bestimmten Funktion, sortiert nach Gesamtdauer. Die Ansicht ähnelt einer Stapelanzeige in der detaillierten Ansicht eines Bewertungsproblems. Die Gewichtungsspalte ungefährt die inklusive Zeit, die von jeder Funktion auf dem Stapel in Millisekunden verbracht wird.
Diese Ansicht wird in Abbildung 51 Angerufenen eines DPC angezeigt, der nach ungefährer Dauer sortiert ist:

Abbildung 51 Angerufene eines DPC nach ungefährer Dauer sortiert
Technik: Überprüfen Long-Running DPCs/ISRs
Die Gesamtdauer der DPCs/ISRs ist wichtig, aber lange ausgeführte einzelne DPCs/ISRs sind wahrscheinlicher, dass Verzögerungen auftreten. Im DPC/ISR-Diagramm zeigt die Spalte "Inklusive Dauer( ms)" in absteigender Reihenfolge die maximale Dauer einzelner DPC/ISRs an. Die vordefinierten Long DPCs/ISRs , die in einigen Bewertungsprofilen verfügbar sind, können Sie diese Ansicht filtern, um nur DPCs/ISRs anzuzeigen, die eine inklusive Dauer haben, die größer als 1Ms ist.
Hinweis Wenn diese Voreinstellung nicht verfügbar ist, können Sie den Ansichts-Editor, erweiterten Abschnitt, öffnen, um einen Filter hinzuzufügen.
Lösung
DPC/ISR-Aktivität spiegelt häufig ein Hardware- oder Softwareproblem wider, das auf Hardware- oder Komponentenebene korrigiert werden muss. Auf Konfigurationsebene können Sie die Hardware ersetzen oder den zugehörigen Treiber auf eine feste Version aktualisieren. Auf Komponentenebene sollten Hardware und Treiber bewährte Methoden für DPCs/ISRs von MSDN befolgen und threadierte DPCs nach Möglichkeit verwenden. Threaded DPCs werden nicht auf der Verteilerebene auf Client editionen von Windows ausgeführt. Weitere Informationen zu bewährten Methoden für DPCs/ISRs finden Sie unter Richtlinien für ISR- und DPC-Verhalten und Einführung in Threaded DPCs.
Zugehörige Themen
Power Management und ACPI – Architektur und Treiberunterstützung
PPM in Windows Vista and Windows Server 2008
Planung, Threadkontext und IRQL