Behandeln von langsamen SQL Server-Leistungseinbußen aufgrund von E/A-Problemen
Gilt für: SQL Server
Dieser Artikel enthält Anleitungen dazu, was E/A-Probleme zu langsamer SQL Server-Leistung und zur Behandlung der Probleme führen.
Definieren der langsamen E/A-Leistung
Leistungsindikatoren werden verwendet, um die langsame E/A-Leistung zu ermitteln. Diese Leistungsindikatoren messen, wie schnell die E/A-Subsystemdienste für jede E/A-Anforderung im Durchschnitt im Hinblick auf die Taktzeit gemessen werden. Die spezifischen Leistungsüberwachungsindikatoren , die die E/A-Latenz in Windows messen, sind Avg Disk sec/ Read, Avg. Disk sec/Writeund Avg. Disk sec/Transfer (kumuliert von Lese- und Schreibvorgängen).
In SQL Server funktionieren die Dinge auf die gleiche Weise. Häufig untersuchen Sie, ob SQL Server E/A-Engpässe meldet, die in der Uhr gemessen werden (Millisekunden). SQL Server stellt E/A-Anforderungen an das Betriebssystem durch Aufrufen der Win32-Funktionen wie WriteFile(), , ReadFile(), WriteFileGather()und ReadFileScatter(). Wenn sie eine E/A-Anforderung sendet, gibt SQL Server die Anforderung mal an und meldet die Dauer der Anforderung mithilfe von Wartetypen. SQL Server verwendet Wait-Typen, um anzuzeigen, dass E/A an verschiedenen Stellen im Produkt wartet. Die E/A-bezogenen Wartezeiten sind:
Wenn diese Wartezeiten 10-15 Millisekunden konsistent überschreiten, wird E/A als Engpass betrachtet.
Notiz
Um Kontext und Perspektive bereitzustellen, hat Microsoft CSS in der Welt der Problembehandlung bei SQL Server Fälle beobachtet, in denen eine E/A-Anforderung eine Sekunde dauerte und so hoch wie 15 Sekunden pro Übertragungs-E/A-Systeme Optimierung benötigt. Umgekehrt hat Microsoft CSS Systeme gesehen, bei denen der Durchsatz unter einer Millisekunden/Übertragung liegt. Mit der heutigen SSD/NVMe-Technologie wurden Durchsatzraten in zehn Mikrosekunden pro Übertragung angeboten. Daher ist die 10-15 Millisekunden/Transfer-Abbildung eine sehr ungefähre Schwelle, die wir basierend auf der kollektiven Erfahrung zwischen Windows- und SQL Server-Ingenieuren in den jahren ausgewählt haben. Wenn Zahlen über diesen ungefähren Schwellenwert hinausgehen, beginnen SQL Server-Benutzer mit der Latenz in ihren Workloads und melden sie. Letztendlich wird der erwartete Durchsatz eines E/A-Subsystems vom Hersteller, Modell, Konfiguration, Workload und potenziell mehreren anderen Faktoren definiert.
Methodik
Ein Flussdiagramm am Ende dieses Artikels beschreibt die Methodik, die Microsoft CSS verwendet, um langsame E/A-Probleme mit SQL Server zu behandeln. Es ist kein erschöpfender oder exklusiver Ansatz, hat sich jedoch als nützlich erwiesen, um das Problem zu isolieren und zu beheben.
Sie können eine der folgenden beiden Optionen auswählen, um das Problem zu beheben:
Option 1: Direktes Ausführen der Schritte in einem Notebook über Azure Data Studio
Notiz
Bevor Sie versuchen, dieses Notizbuch zu öffnen, stellen Sie sicher, dass Azure Data Studio auf Ihrem lokalen Computer installiert ist. Informationen zum Installieren von Azure Data Studio finden Sie unter "Informationen zum Installieren von Azure Data Studio".
Option 2: Führen Sie die Schritte manuell aus.
Die Methodik wird in den folgenden Schritten beschrieben:
Schritt 1: Meldet SQL Server langsam E/A?
SQL Server kann E/A-Latenz auf verschiedene Arten melden:
- E/A-Wartetypen
- DMV
sys.dm_io_virtual_file_stats - Fehlerprotokoll oder Anwendungsereignisprotokoll
E/A-Wartetypen
Ermitteln Sie, ob die E/A-Latenz von SQL Server-Wartetypen gemeldet wird. Die Werte , WRITELOGund ASYNC_IO_COMPLETION die Werte PAGEIOLATCH_*mehrerer weniger gängiger Wartetypen sollten in der Regel unter 10-15 Millisekunden pro E/A-Anforderung bleiben. Wenn diese Werte konsistenter sind, ist ein E/A-Leistungsproblem vorhanden und erfordert eine weitere Untersuchung. Die folgende Abfrage kann Ihnen helfen, diese Diagnoseinformationen auf Ihrem System zu sammeln:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Dateistatistiken in sys.dm_io_virtual_file_stats
Führen Sie die folgende Abfrage aus, um die Latenz auf Datenbankdateiebene anzuzeigen, wie in SQL Server angegeben:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Betrachten Sie die AvgLatency Und LatencyAssessment Spalten, um die Latenzdetails zu verstehen.
Fehler 833, der im Fehlerprotokoll oder Anwendungsereignisprotokoll gemeldet wurde
In einigen Fällen können Sie fehler 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) im Fehlerprotokoll beobachten. Sie können SQL Server-Fehlerprotokolle auf Ihrem System überprüfen, indem Sie den folgenden PowerShell-Befehl ausführen:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Weitere Informationen zu diesem Fehler finden Sie auch im Abschnitt MSSQLSERVER_833 .
Schritt 2: Geben Perfmon-Leistungsindikatoren die E/A-Latenz an?
Wenn SQL Server die E/A-Latenz meldet, verweisen Sie auf Betriebssystemzähler. Sie können ermitteln, ob ein E/A-Problem vorliegt, indem Sie den Latenzindikator Avg Disk Sec/Transferuntersuchen. Der folgende Codeausschnitt gibt eine Möglichkeit zum Sammeln dieser Informationen über PowerShell an. Es sammelt Leistungsindikatoren auf allen Datenträgervolumes: "_total". Wechseln Sie zu einem bestimmten Laufwerkvolume (z. B. "D:"). Um zu ermitteln, welche Volumes Ihre Datenbankdateien hosten, führen Sie die folgende Abfrage in Ihrem SQL Server aus:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Sammeln Sie Avg Disk Sec/Transfer Metriken für Ihre Auswahlmenge:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Wenn die Werte dieses Indikators konsistent über 10-15 Millisekunden liegen, müssen Sie sich das Problem weiter ansehen. Gelegentliche Spitzen zählen in den meisten Fällen nicht, aber achten Sie darauf, die Dauer einer Spitzen zu überprüfen. Wenn die Spitze mindestens eine Minute dauerte, handelt es sich um ein Plateau als eine Spitzenspitze.
Wenn die Leistungsüberwachungsindikatoren keine Latenz melden, aber SQL Server dies tut, liegt das Problem zwischen SQL Server und dem Partitions-Manager, d. h. Filtertreibern. Der Partitions-Manager ist eine E/A-Ebene, auf der das Betriebssystem Perfmon-Leistungsindikatoren sammelt. Um die Latenz zu beheben, stellen Sie die richtigen Ausschlüsse von Filtertreibern sicher, und beheben Sie Filtertreiberprobleme. Filtertreiber werden von Programmen wie Antivirensoftware, Sicherungslösungen, Verschlüsselung, Komprimierung usw. verwendet. Mit diesem Befehl können Sie Filtertreiber auf den Systemen und den Volumes auflisten, an die sie angeschlossen sind. Anschließend können Sie die Treibernamen und Softwareanbieter im Artikel "Zugewiesene Filterhöhen " nachschlagen.
fltmc instances
Weitere Informationen finden Sie unter Auswählen von Antivirensoftware, die auf Computern ausgeführt werden soll, auf denen SQL Server ausgeführt wird.
Vermeiden Sie die Verwendung von Encrypting File System (EFS) und Dateisystemkomprimierung, da sie dazu führen, dass asynchrone E/A synchron und daher langsamer wird. Weitere Informationen finden Sie im Artikel "Asynchrone Datenträger-E/A" als synchron im Windows-Artikel .
Schritt 3: Ist das E/A-Subsystem überlastet über die Kapazität hinaus?
Wenn SQL Server und das Betriebssystem angeben, dass das E/A-Subsystem langsam ist, überprüfen Sie, ob die Ursache dafür ist, dass das System über die Kapazität hinaus überfordert wird. Sie können die Kapazität überprüfen, indem Sie sich die E/A-Leistungsindikatoren Disk Bytes/Sec, Disk Read Bytes/Secoder Disk Write Bytes/Sec. Erkundigen Sie sich bei Ihrem Systemadministrator oder Hardwareanbieter nach den erwarteten Durchsatzspezifikationen für Ihr SAN (oder ein anderes E/A-Subsystem). Sie können z. B. nicht mehr als 200 MB/s E/S von E/A über eine HBA-Karte mit 2 GB/s oder 2 GB/s dedizierten Port auf einem SAN-Switch übertragen. Die erwartete Durchsatzkapazität, die von einem Hardwarehersteller definiert wird, definiert, wie Sie von hier fortfahren.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Schritt 4: Wird die schwere E/A-Aktivität von SQL Server durch SQL Server getrieben?
Wenn das E/A-Subsystem überlastet ist, finden Sie heraus, ob SQL Server der Schuldige ist, indem Sie sich (am häufigsten) und Page Writes/Sec (viel weniger häufig) für die jeweilige Instanz ansehen Buffer Manager: Page Reads/Sec . Wenn SQL Server der Haupt-E/A-Treiber und das E/A-Volume über das System hinausgeht, arbeiten Sie mit den Anwendungsentwicklungsteams oder Anwendungsanbietern zusammen mit:
- Optimieren Sie Abfragen, z. B. bessere Indizes, aktualisieren Sie Statistiken, schreiben Sie Abfragen neu, und entwerfen Sie die Datenbank neu.
- Erhöhen Sie den maximalen Serverspeicher , oder fügen Sie mehr RAM auf dem System hinzu. Mehr RAM speichert mehr Daten- oder Indexseiten zwischen, ohne häufig von einem Datenträger erneut zu lesen, wodurch die E/A-Aktivität reduziert wird. Ein erhöhter Arbeitsspeicher kann auch reduziert
Lazy Writes/secwerden, was durch Lazy Writer-Leerungen gesteuert wird, wenn es häufig erforderlich ist, mehr Datenbankseiten im begrenzten Arbeitsspeicher zu speichern. - Wenn Sie feststellen, dass Seitenschreibvorgänge die Quelle für schwere E/A-Aktivitäten sind, überprüfen
Buffer Manager: Checkpoint pages/secSie, ob dies auf massive Seitenspülungen zurückzuführen ist, die erforderlich sind, um die Konfigurationsanforderungen des Wiederherstellungsintervalls zu erfüllen. Sie können entweder indirekte Prüfpunkte verwenden, um E/A im Laufe der Zeit auszuprobieren oder den Hardware-E/A-Durchsatz zu erhöhen.
Ursachen
Im Allgemeinen sind die folgenden Probleme die Gründe, warum SQL Server-Abfragen unter E/A-Latenz leiden:
Hardwareprobleme:
San-Konfiguration (Switch, Kabel, HBA, Speicher)
Überschrittene E/A-Kapazität (nicht ausgeglichen im gesamten SAN-Netzwerk, nicht nur Back-End-Speicher)
Treiber- oder Firmwareprobleme
Hardwareanbieter und/oder Systemadministratoren müssen in dieser Phase eingebunden werden.
Abfrageprobleme: SQL Server sättigungt Datenträgervolumes mit E/A-Anforderungen und verschiebt das E/A-Subsystem über die Kapazität hinaus, wodurch die E/A-Übertragungsraten hoch sind. In diesem Fall besteht die Lösung darin, die Abfragen zu finden, die eine hohe Anzahl logischer Lesevorgänge (oder Schreibvorgänge) verursachen, und diese Abfragen so zu optimieren, dass Datenträger-E/A mit entsprechenden Indizes minimiert wird, ist der erste Schritt, um dies zu tun. Halten Sie außerdem Statistiken auf dem neuesten Stand, da sie den Abfrageoptimierer mit ausreichenden Informationen bereitstellen, um den besten Plan auszuwählen. Außerdem kann ein falscher Datenbankentwurf und abfrageentwurf zu einer Zunahme der E/A-Probleme führen. Daher kann die Neugestaltung von Abfragen und manchmal Tabellen bei verbesserten E/A-Vorgängen hilfreich sein.
Filtertreiber: Die SQL Server-E/A-Antwort kann stark beeinträchtigt werden, wenn Dateisystemfiltertreiber schwere E/A-Datenverkehr verarbeiten. Es wird empfohlen, die Auswirkungen auf die E/A-Leistung zu vermeiden, geeignete Dateiausschlüsse von Antivirenscans und korrektem Filtertreiberdesign von Softwareanbietern.
Andere Anwendungen: Eine andere Anwendung auf demselben Computer mit SQL Server kann den E/A-Pfad mit übermäßigen Lese- oder Schreibanforderungen sättigungen. Diese Situation kann das E/A-Subsystem über Kapazitätsgrenzen hinausschieben und die E/A-Langsamkeit für SQL Server verursachen. Identifizieren Sie die Anwendung, und optimieren Sie sie, oder verschieben Sie sie an anderer Stelle, um ihre Auswirkungen auf den E/A-Stapel zu beseitigen.
Grafische Darstellung der Methodik
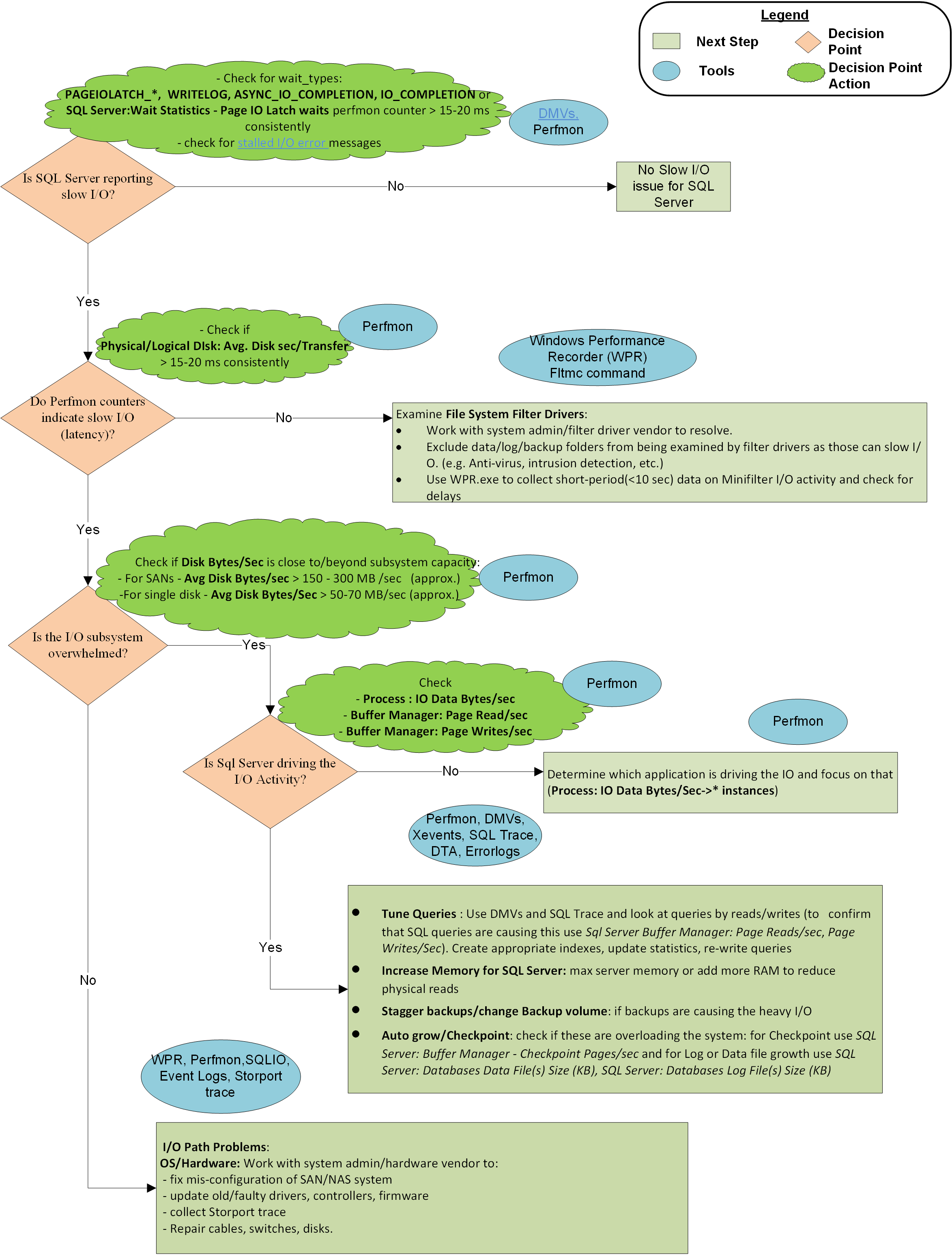
Informationen zu E/A-bezogenen Wartetypen
Im Folgenden finden Sie Beschreibungen der gängigen Wartetypen, die in SQL Server beobachtet werden, wenn Datenträger-E/A-Probleme gemeldet werden.
PAGEIOLATCH_EX
Tritt auf, wenn eine Aufgabe auf einem Riegel auf eine Daten- oder Indexseite (Puffer) in einer E/A-Anforderung wartet. Die Latch-Anforderung befindet sich im Exklusivmodus. Ein Exklusivmodus wird verwendet, wenn der Puffer auf den Datenträger geschrieben wird. Lange Wartezeiten können Probleme mit dem Datenträgersubsystem anzeigen.
PAGEIOLATCH_SH
Tritt auf, wenn eine Aufgabe auf einem Riegel auf eine Daten- oder Indexseite (Puffer) in einer E/A-Anforderung wartet. Die Latch-Anforderung befindet sich im Modus "Freigegeben". Der Freigegebene Modus wird verwendet, wenn der Puffer vom Datenträger gelesen wird. Lange Wartezeiten können Probleme mit dem Datenträgersubsystem anzeigen.
PAGEIOLATCH_UP
Tritt auf, wenn eine Aufgabe auf einen Riegel für einen Puffer in einer E/A-Anforderung wartet. Die Latch-Anforderung befindet sich im Updatemodus. Lange Wartezeiten können Probleme mit dem Datenträgersubsystem anzeigen.
WRITELOG
Tritt auf, wenn eine Aufgabe auf den Abschluss eines Transaktionsprotokolls wartet. Wenn der Protokoll-Manager den temporären Inhalt auf den Datenträger schreibt, tritt ein Löschvorgang auf. Häufige Vorgänge, die Protokolllöschvorgänge verursachen, sind Transaktions-Commits und Prüfpunkte.
Häufige Gründe für lange Wartezeiten WRITELOG sind:
Latenz des Transaktionsprotokolldatenträgers: Dies ist die häufigste Ursache für
WRITELOGWartezeiten. Im Allgemeinen empfiehlt es sich, die Daten und Protokolldateien auf separaten Volumes zu speichern. Transaktionsprotokoll-Schreibvorgänge sind sequenzielle Schreibvorgänge beim Lesen oder Schreiben von Daten aus einer Datendatei ist zufällig. Das Mischen von Daten und Protokolldateien auf einem Laufwerkvolume (insbesondere herkömmliche spinnende Festplattenlaufwerke) führt zu übermäßiger Datenträgerkopfbewegung.Zu viele VLFs: Zu viele virtuelle Protokolldateien (VLFs) können Wartezeiten verursachen
WRITELOG. Zu viele VLFs können andere Arten von Problemen verursachen, z. B. lange Wiederherstellung.Zu viele kleine Transaktionen: Während große Transaktionen zu Blockierungen führen können, können zu viele kleine Transaktionen zu einer anderen Reihe von Problemen führen. Wenn Sie eine Transaktion nicht explizit beginnen, führt jedes Einfügen, Löschen oder Aktualisieren zu einer Transaktion (wir rufen diese automatische Transaktion auf). Wenn Sie 1.000 Einfügungen in einer Schleife ausführen, werden 1.000 Transaktionen generiert. Jede Transaktion in diesem Beispiel muss einen Commit ausführen, was zu einem Leeren des Transaktionsprotokolls und 1.000 Transaktionsleerungen führt. Wenn möglich, gruppieren Sie einzelne Aktualisierungen, Löschen oder Einfügen in eine größere Transaktion, um die Leerungen des Transaktionsprotokolls zu reduzieren und die Leistung zu erhöhen. Dieser Vorgang kann zu weniger
WRITELOGWartezeiten führen.Planungsprobleme führen dazu, dass Log Writer-Threads nicht schnell genug geplant werden: Vor SQL Server 2016 hat ein einzelner Log Writer-Thread alle Protokollschreibvorgänge ausgeführt. Wenn Probleme mit der Threadplanung (z. B. hohe CPU) aufgetreten sind, konnten sowohl der Log Writer-Thread als auch die Protokolllöschungen verzögert werden. In SQL Server 2016 wurden bis zu vier Log Writer-Threads hinzugefügt, um den Protokollschreibdurchsatz zu erhöhen. Siehe SQL 2016 – Es wird einfach schneller ausgeführt: Mehrere Log Writer-Worker. In SQL Server 2019 wurden bis zu acht Log Writer-Threads hinzugefügt, wodurch der Durchsatz noch verbessert wird. Außerdem kann jeder reguläre Workerthread in SQL Server 2019 Schreibvorgänge direkt protokollieren, anstatt in den Log Writer-Thread zu posten. Mit diesen Verbesserungen
WRITELOGwürden Wartezeiten selten durch Terminplanungsprobleme ausgelöst.
ASYNC_IO_COMPLETION
Tritt auf, wenn einige der folgenden E/A-Aktivitäten auftreten:
- Der Masseneinfügungsanbieter ("Massenvorgang einfügen") verwendet diesen Wartetyp beim Ausführen von E/A.
- Lesen der Rückgängig-Datei in LogShipping und Weiterleiten von Async-E/A für den Protokollversand.
- Lesen der tatsächlichen Daten aus den Datendateien während einer Datensicherung.
IO_COMPLETION
Tritt auf, während auf den Abschluss von E/A-Vorgängen gewartet wird. Dieser Wartetyp umfasst im Allgemeinen I/Os, die nicht mit Datenseiten (Puffern) verknüpft sind. Beispiele:
- Lesen und Schreiben von Sortier-/Hashergebnissen von/auf den Datenträger während eines Überlaufs (Überprüfen der Leistung des tempdb-Speichers ).
- Lesen und Schreiben von eifrigen Spools auf datenträger (überprüfen Sie den tempdb-Speicher ).
- Leseprotokollblöcke aus dem Transaktionsprotokoll (bei jedem Vorgang, der bewirkt, dass das Protokoll vom Datenträger gelesen wird , z. B. Wiederherstellung).
- Lesen einer Seite vom Datenträger, wenn die Datenbank noch nicht eingerichtet ist.
- Kopieren von Seiten in eine Datenbankmomentaufnahme (Copy-on-Write).
- Schließen von Datenbankdateien und Dateientkomprimierung.
BACKUPIO
Tritt auf, wenn eine Sicherungsaufgabe auf Daten wartet oder auf einen Puffer zum Speichern von Daten wartet. Dieser Typ ist nicht typisch, außer wenn eine Aufgabe auf eine Bandhalterung wartet.