Problembehandlung für Abfragen, die in SQL Server anscheinend nie enden
In diesem Artikel werden die Schritte zur Problembehandlung für das Problem beschrieben, bei dem Sie eine Abfrage haben, die scheinbar nie abgeschlossen ist, oder es kann viele Stunden oder Tage dauern.
Was ist eine nie endende Abfrage?
Dieses Dokument konzentriert sich auf Abfragen, die weiterhin ausgeführt oder kompiliert werden, d. h. ihre CPU nimmt weiter zu. Sie gilt nicht für Abfragen, die blockiert oder auf eine Ressource warten, die nie freigegeben wird (die CPU bleibt konstant oder ändert sich nur sehr wenig).
Wichtig
Wenn eine Abfrage die Ausführung beendet, wird sie schließlich abgeschlossen. Es kann nur ein paar Sekunden dauern, oder es kann mehrere Tage dauern.
Der Begriff "Never-End" wird verwendet, um die Wahrnehmung einer Abfrage zu beschreiben, die nicht abgeschlossen wird, wenn die Abfrage tatsächlich abgeschlossen wird.
Identifizieren einer nie endenden Abfrage
Führen Sie die folgenden Schritte aus, um festzustellen, ob eine Abfrage kontinuierlich ausgeführt oder bei einem Engpass hängen bleibt:
Führen Sie die folgende Abfrage aus:
DECLARE @cntr int = 0 WHILE (@cntr < 3) BEGIN SELECT TOP 10 s.session_id, r.status, r.wait_time, r.wait_type, r.wait_resource, r.cpu_time, r.logical_reads, r.reads, r.writes, r.total_elapsed_time / (1000 * 60) 'Elaps M', SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1, ((CASE r.statement_end_offset WHEN -1 THEN DATALENGTH(st.TEXT) ELSE r.statement_end_offset END - r.statement_start_offset) / 2) + 1) AS statement_text, COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid)) + N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text, r.command, s.login_name, s.host_name, s.program_name, s.last_request_end_time, s.login_time, r.open_transaction_count, atrn.name as transaction_name, atrn.transaction_id, atrn.transaction_state FROM sys.dm_exec_sessions AS s JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st LEFT JOIN (sys.dm_tran_session_transactions AS stran JOIN sys.dm_tran_active_transactions AS atrn ON stran.transaction_id = atrn.transaction_id) ON stran.session_id =s.session_id WHERE r.session_id != @@SPID ORDER BY r.cpu_time DESC SET @cntr = @cntr + 1 WAITFOR DELAY '00:00:05' ENDÜberprüfen Sie die Beispielausgabe.
Die Schritte zur Problembehandlung in diesem Artikel gelten speziell, wenn Sie eine Ausgabe ähnlich wie die folgende feststellen, bei der die CPU proportional zur verstrichenen Zeit erhöht wird, ohne erhebliche Wartezeiten. Es ist wichtig zu beachten, dass Änderungen in
logical_readsdiesem Fall nicht relevant sind, da einige CPU-gebundene T-SQL-Anforderungen möglicherweise überhaupt keine logischen Lesevorgänge durchführen (z. B. Ausführen von Berechnungen oder einerWHILESchleife).session_id status cpu_time logical_reads wait_time wait_type 56 „Wird ausgeführt“ 7038 101000 0 NULL 56 runnable 12040 301000 0 NULL 56 „Wird ausgeführt“ 17020 523000 0 NULL Dieser Artikel ist nicht anwendbar, wenn Sie ein Warteszenario wie das folgende beobachten, bei dem sich die CPU nicht sehr leicht ändert oder ändert, und die Sitzung auf eine Ressource wartet.
session_id status cpu_time logical_reads wait_time wait_type 56 Angehalten 0 3 8312 LCK_M_U 56 Angehalten 0 3 13318 LCK_M_U 56 Angehalten 0 5 18331 LCK_M_U
Weitere Informationen finden Sie unter Diagnose von Wartezeiten oder Engpässen.
Lange Kompilierungszeit
In seltenen Fällen können Sie feststellen, dass die CPU im Laufe der Zeit kontinuierlich steigt, aber das wird nicht von der Abfrageausführung gesteuert. Stattdessen könnte sie durch eine übermäßig lange Kompilierung (die Analyse und Kompilierung einer Abfrage) gesteuert werden. Überprüfen Sie in diesen Fällen die transaction_name Ausgabespalte, und suchen Sie nach einem Wert von sqlsource_transform. Dieser Transaktionsname gibt eine Kompilierung an.
Erfassen von Diagnosedaten
- SQL Server 2008 – SQL Server 2014 (vor SP2)
- SQL Server 2014 (nach SP2) und SQL Server 2016 (vor SP1)
- SQL Server 2016 (nach SP1) und SQL Server 2017
- SQL Server 2019 und höhere Versionen
Führen Sie die folgenden Schritte aus, um Diagnosedaten mithilfe von SQL Server Management Studio (SSMS) zu sammeln:
Erfassen Sie den XML-Code für den geschätzten Abfrageausführungsplan .
Überprüfen Sie den Abfrageplan, um festzustellen, ob offensichtliche Anzeichen dafür vorhanden sind, woher die Langsamkeit kommen kann. Typische Beispiele sind u. a.:
- Tabellen- oder Indexüberprüfungen (betrachten Sie geschätzte Zeilen).
- Geschachtelte Schleifen, die von einem riesigen äußeren Tabellendatensatz gesteuert werden.
- Geschachtelte Schleifen mit einem großen Verzweigung auf der inneren Seite der Schleife.
- Tabellenspools.
- Funktionen in der
SELECTListe, die eine lange Zeit dauern, um jede Zeile zu verarbeiten.
Wenn die Abfrage jederzeit schnell ausgeführt wird, können Sie die "schnellen" Ausführungen des tatsächlichen XML-Ausführungsplans erfassen, um sie zu vergleichen.
Methode zum Überprüfen der gesammelten Pläne
In diesem Abschnitt wird veranschaulicht, wie die gesammelten Daten überprüft werden. Sie verwendet die in SQL Server 2016 SP1 und höheren Builds und Versionen gesammelten XML-Abfragepläne (mithilfe der Erweiterung *.sqlplan).
Führen Sie die folgenden Schritte aus, um Ausführungspläne zu vergleichen:
Öffnen Sie eine zuvor gespeicherte Abfrageausführungsplandatei (SQLPLAN).
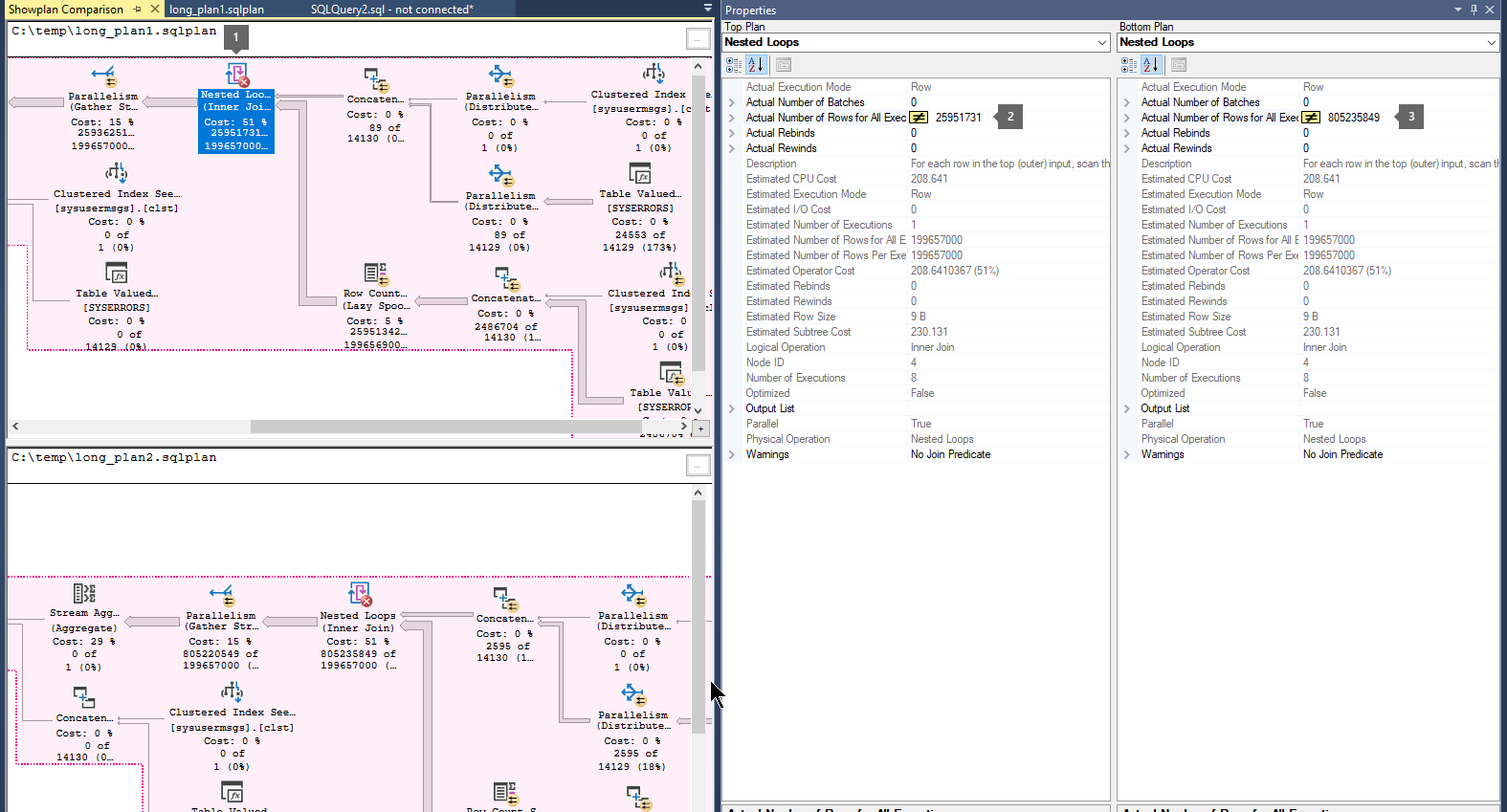
Klicken Sie mit der rechten Maustaste in einen leeren Bereich des Ausführungsplans, und wählen Sie "Showplan vergleichen" aus.
Wählen Sie die zweite Abfrageplandatei aus, die Sie vergleichen möchten.
Suchen Sie nach dicken Pfeilen, die eine große Anzahl von Zeilen angeben, die zwischen Operatoren fließen. Wählen Sie dann den Operator vor oder nach dem Pfeil aus, und vergleichen Sie die Anzahl der tatsächlichen Zeilen über zwei Pläne hinweg.
Vergleichen Sie die pläne für das zweite und dritte, um festzustellen, ob der größte Zeilenfluss in denselben Operatoren erfolgt.
Hier sehen Sie ein Beispiel:

Lösung
Stellen Sie sicher, dass Statistiken für die tabellen aktualisiert werden, die in der Abfrage verwendet werden.
Suchen Sie im Abfrageplan nach einer fehlenden Indexempfehlung, und wenden Sie alle an.
Schreiben Sie die Abfrage um, um sie zu vereinfachen:
- Verwenden Sie selektivere
WHEREPrädikate, um die im Vorfeld verarbeiteten Daten zu reduzieren. - Trennen Sie es.
- Wählen Sie einige Teile in temporäre Tabellen aus, und verknüpfen Sie sie später.
- Entfernen Sie
TOP,EXISTSundFAST(T-SQL) in den Abfragen, die aufgrund des Optimierungszeilenziels für eine sehr lange Zeit ausgeführt werden. Alternativ können Sie denDISABLE_OPTIMIZER_ROWGOALHinweis verwenden. Weitere Informationen finden Sie unter Row Goals Gone Rogue. - Vermeiden Sie die Verwendung allgemeiner Tabellenausdrücke (Common Table Expressions, CTEs) in Solchen Fällen, wie sie Anweisungen in einer einzigen großen Abfrage kombinieren.
- Verwenden Sie selektivere
Versuchen Sie, Abfragehinweise zu verwenden, um einen besseren Plan zu erstellen:
HASH JOINoderMERGE JOINHinweisFORCE ORDER-HinweisFORCESEEK-HinweisRECOMPILE- USE
PLAN N'<xml_plan>', wenn Sie über einen schnellen Abfrageplan verfügen, den Sie erzwingen können
Verwenden Sie Abfragespeicher (QDS), um einen gut bekannten Plan zu erzwingen, wenn ein solcher Plan vorhanden ist und ob Ihre SQL Server-Version Abfragespeicher unterstützt.
Diagnostizieren von Wartezeiten oder Engpässen
Dieser Abschnitt ist hier als Referenz enthalten, falls Ihr Problem keine lange ausgeführte CPU-Treiberabfrage ist. Sie können es verwenden, um Abfragen zu behandeln, die aufgrund von Wartezeiten lang sind.
Um eine Abfrage zu optimieren, die auf Engpässe wartet, identifizieren Sie, wie lange die Wartezeit ist und wo der Engpass liegt (der Wartetyp). Nachdem der Wartetyp bestätigt wurde, reduzieren Sie die Wartezeit, oder beseitigen Sie die Wartezeit vollständig.
Um die ungefähre Wartezeit zu berechnen, subtrahieren Sie die CPU-Zeit (Arbeitszeit) von der verstrichenen Zeit einer Abfrage. In der Regel ist die CPU-Zeit die tatsächliche Ausführungszeit, und der verbleibende Teil der Lebensdauer der Abfrage wartet.
Beispiele für die Berechnung der ungefähren Wartezeit:
| Verstrichene Zeit (ms) | CPU-Zeit (ms) | Wartezeit (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1.000 | 6080 |
Identifizieren des Engpasses oder Wartens
Führen Sie die folgende Abfrage aus, >um historische Langewarteabfragen zu identifizieren (z. B. 20 % der gesamt verstrichenen Wartezeit). Diese Abfrage verwendet Seit dem Start von SQL Server Leistungsstatistiken für zwischengespeicherte Abfragepläne.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCFühren Sie die folgende Abfrage aus, um derzeit ausgeführte Abfragen mit einer Wartezeit von mehr als 500 ms zu identifizieren:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Wenn Sie einen Abfrageplan sammeln können, überprüfen Sie die WaitStats aus den Ausführungsplaneigenschaften in SSMS:
- Führen Sie die Abfrage mit "Ist-Ausführungsplan einschließen" aus.
- Klicken Sie mit der rechten Maustaste auf den operator ganz links auf der Registerkarte "Ausführungsplan "
- Wählen Sie "Eigenschaften" und dann "WaitStats "-Eigenschaft aus.
- Überprüfen Sie die WaitTimeMs und WaitType.
Wenn Sie mit PSSDiag/SQLdiag oder SQL LogFinder LightPerf/GeneralPerf-Szenarien vertraut sind, sollten Sie eine dieser Szenarien verwenden, um Leistungsstatistiken zu sammeln und Wartende Abfragen auf Ihrer SQL Server-Instanz zu identifizieren. Sie können die gesammelten Datendateien importieren und die Leistungsdaten mit SQL Nexus analysieren.
Verweise zur Beseitigung oder Reduzierung von Wartezeiten
Die Ursachen und Auflösungen für jeden Wartetyp variieren. Es gibt keine allgemeine Methode zum Auflösen aller Wartetypen. Im Folgenden finden Sie Artikel zur Problembehandlung und Behebung häufig auftretender Wartetypprobleme:
- Verstehen und Beheben von Blockierungsproblemen (LCK_M_*)
- Verstehen und Beheben von Problemen durch Blockierungen in Azure SQL-Datenbank
- Behandeln von langsamen SQL Server-Leistung durch E/A-Probleme (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Konflikt beim Einfügen von PAGELATCH_EX auf letzter Seite in SQL Server auflösen
- Arbeitsspeicher gewährt Erläuterungen und Lösungen (RESOURCE_SEMAPHORE)
- Problembehandlung für langsame Abfragen, die aus ASYNC_NETWORK_IO Wartetyp resultieren
- Problembehandlung bei HADR_SYNC_COMMIT Wartetyp mit AlwaysOn-Verfügbarkeitsgruppen
- Funktionsweise: CMEMTHREAD und Debuggen
- Parallelität wird mit Aktionen gewartet (CXPACKET und CXCONSUMER)
- THREADPOOL-Wartezeit
Beschreibungen vieler Wait-Typen und deren Angabe finden Sie in der Tabelle unter "Waits".