Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel enthält Lösungen für Probleme im Zusammenhang mit der Wiederherstellungswarteschlange.
Was ist die Wiederherstellungswarteschlange?
Änderungen, die in einer Verfügbarkeitsgruppendatenbank am primären Replikat vorgenommen werden, werden an alle sekundären Replikate gesendet, die in derselben Verfügbarkeitsgruppe definiert sind. Nachdem diese Änderungen bei den sekundären Replikaten angekommen sind, werden sie zunächst in die Transaktionsprotokolldatei der Verfügbarkeitsgruppendatenbank geschrieben. Microsoft SQL Server verwendet dann den Wiederherstellungs - oder Redo-Vorgang , um die Datenbankdateien zu aktualisieren.
Wenn die Änderungen an einer Verfügbarkeitsgruppe schneller als wiederhergestellt werden können, wird eine Wiederherstellungswarteschlange gebildet. Diese Warteschlange besteht aus gehärteten Transaktionsprotokolltransaktionen, die nicht in der Datenbank wiederhergestellt wurden.
Symptome und Wirkung der Wiederherstellung (Wiederholen) Warteschlangen
Das Abfragen primärer und sekundärer Replikate gibt unterschiedliche Ergebnisse zurück.
Schreibgeschützte Workloads, die sekundäre Replikate abfragen, können veraltete Daten abfragen. Wenn die Wiederherstellungswarteschlange auftritt, werden Änderungen an Daten in der primären Replikatdatenbank möglicherweise nicht in der sekundären Datenbank angezeigt, wenn Sie dieselben Daten abfragen.
Obwohl Änderungen an der sekundären Datenbank eingehen und in die Datenbankprotokolldatei geschrieben werden, werden die Änderungen erst abgefragt, wenn sie wiederhergestellt und in die Datenbankdateien wiederhergestellt werden. Der Wiederherstellungsvorgang macht diese Änderungen lesbar.
Weitere Informationen finden Sie im Abschnitt "Datenlatenz im sekundären Replikat " unter "Unterschiede zwischen den Verfügbarkeitsmodi für eine AlwaysOn-Verfügbarkeitsgruppe".
Die Failoverzeit ist länger, oder RTO wird überschritten.
Recovery Time Objective (RTO) ist die maximale Ausfallzeit der Datenbank, die eine Organisation verarbeiten kann. RTO beschreibt auch, wie schnell die Organisation nach einem Ausfall wieder auf die Datenbank zugreifen kann. Wenn eine erhebliche Wiederherstellungswarteschlange in einem sekundären Replikat vorhanden ist, wenn ein Failover auftritt, kann die Wiederherstellung länger dauern. Nach der Wiederherstellung wechselt die Datenbank zur primären Rolle und stellt den Status der Datenbank dar, die vor dem Failover vorhanden war. Eine längere Wiederherstellungszeit kann verzögern, wie schnell die Produktion nach einem Failover fortgesetzt wird.
Verschiedene Diagnosefeatures melden verfügbarkeitsgruppenwiederherstellung in der Warteschlange
Im Falle der Wiederherstellungswarteschlange meldet das Always On-Dashboard in SQL Server Management Studio (SSMS) möglicherweise eine fehlerhafte Verfügbarkeitsgruppe.
So überprüfen Sie die Wiederherstellungswarteschlange (Wiederholen)
Die Wiederherstellungswarteschlange ist eine Maßeinheit pro Datenbank, die mithilfe des Always On-Dashboards auf dem primären Replikat oder mithilfe der sys.dm_hadr_database_replica_states dynamischen Verwaltungsansicht (DYNAMIC Management View, DMV) im primären oder sekundären Replikat überprüft werden kann. Leistungsmonitor Leistungsindikatoren überprüfen die Wiederherstellungswarteschlange und die Wiederherstellungsrate. Diese Leistungsindikatoren müssen für das sekundäre Replikat überprüft werden.
In den nächsten Abschnitten werden Methoden zum aktiven Überwachen der Wiederherstellungswarteschlange für Die Verfügbarkeitsgruppendatenbank bereitgestellt.
Abfrage-sys.dm_hadr_database_replica_states
Der sys.dm_hadr_database_replica_states DMV meldet eine Zeile für jede Verfügbarkeitsgruppendatenbank. Eine Spalte im Bericht ist redo_queue_size. Dieser Wert ist die Größe der Wiederherstellungswarteschlange, wie in Kilobyte gemessen. Sie können eine Abfrage einrichten, die der folgenden Abfrage ähnelt, um jeden Trend in der Größe der Wiederherstellungswarteschlange alle 30 Sekunden zu überwachen. Die Abfrage wird im primären Replikat ausgeführt. Es verwendet das is_local=0 Prädikat, um die Daten für das sekundäre Replikat zu melden, wo redo_queue_size und redo_rate welche relevant sind.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
So sieht die Ausgabe aus.

Überprüfen der Wiederherstellungswarteschlange im Always On Dashboard
Führen Sie die folgenden Schritte aus, um die Wiederherstellungswarteschlange zu überprüfen:
Öffnen Sie das Always On Dashboard in SSMS, indem Sie mit der rechten Maustaste auf eine Verfügbarkeitsgruppe in SSMS Objekt-Explorer klicken.
Wählen Sie " Dashboard anzeigen" aus.
Die Verfügbarkeitsgruppendatenbanken werden zuletzt aufgelistet, und es werden einige Daten in den Datenbanken gemeldet. Obwohl Redo Queue Size (KB) und Redo Rate (KB/Sec) nicht standardmäßig aufgeführt sind, können Sie sie dieser Ansicht hinzufügen, wie im Screenshot im nächsten Schritt gezeigt.
Wenn Sie diese Indikatoren hinzufügen möchten, klicken Sie mit der rechten Maustaste auf die Kopfzeile oberhalb der Datenbankberichte, und wählen Sie aus der Liste der verfügbaren Spalten aus.
Wenn Sie die Größe der Redo-Warteschlange (KB) und die Wiederholungsrate (KB/Sek.) hinzufügen möchten, klicken Sie mit der rechten Maustaste auf die Kopfzeile, die im folgenden Screenshot rot hervorgehoben ist.
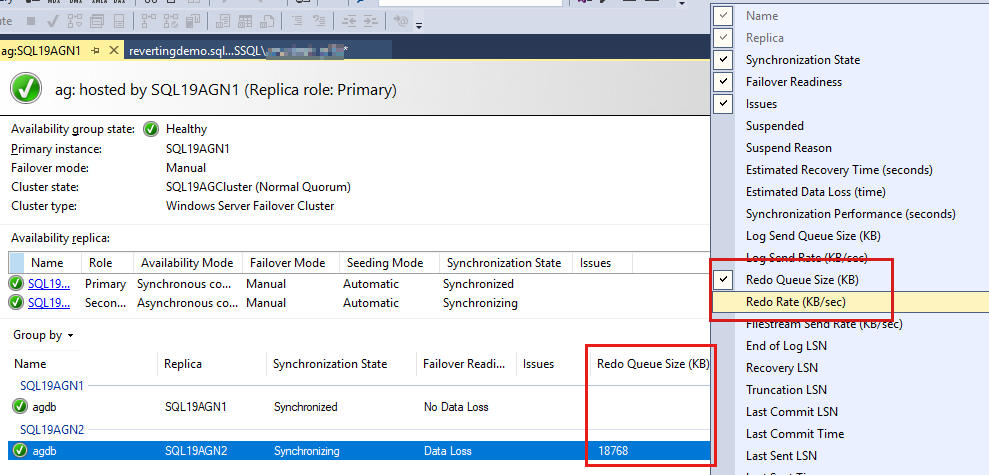
Standardmäßig aktualisiert das Always On-Dashboard die Redo Queue Size (KB) und die Wiederholungsrate (KB/Sek.) alle 60 Sekunden.
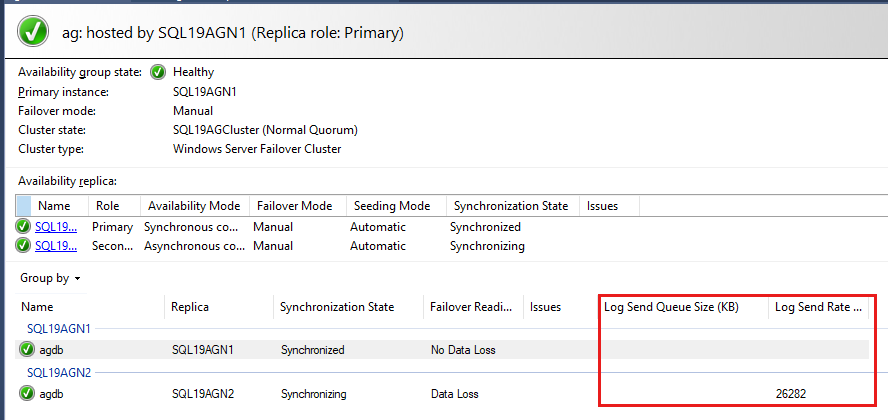


Überprüfen der Wiederherstellungswarteschlange in Leistungsmonitor
Die Größe der Wiederherstellungswarteschlange ist für jedes sekundäre Replikat und jede Datenbank eindeutig. Führen Sie daher die folgenden Schritte aus, um die Wiederherstellungswarteschlange einer Verfügbarkeitsgruppendatenbank zu überprüfen:
Öffnen Sie Leistungsmonitor für das sekundäre Replikat.
Wählen Sie die Schaltfläche "Hinzufügen " (Zähler) aus.
Wählen Sie unter "Verfügbare Leistungsindikatoren" die Option "SQLServer:Datenbankreplikat" und dann " Wiederherstellungswarteschlange " und "Bytes/Sek . erneut" aus.
Wählen Sie im Listenfeld "Instanz " die Verfügbarkeitsgruppendatenbank aus, die Sie für die Wiederherstellungswarteschlange überwachen möchten.
Klicken Sie auf Hinzufügen>OK.
So könnte die Erhöhung der Wiederherstellungswarteschlange aussehen.
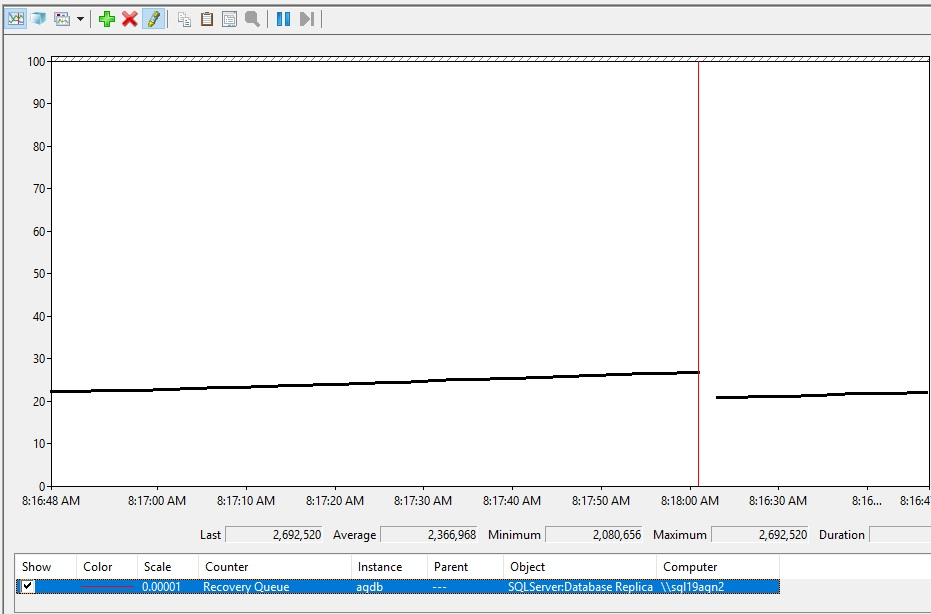

Interpretieren von Wiederherstellungswarteschlangenwerten
In diesem Abschnitt wird erläutert, wie Sie die Werte interpretieren können, die sich auf die Wiederherstellungswarteschlange beziehen, die Sie im vorherigen Abschnitt ermittelt haben.
Wann wird ein Problem in der Wiederherstellungswarteschlange in die Warteschlange gestellt? Wie viel Wiederherstellungswarteschlange sollten Sie tolerieren?
Wenn die Wiederherstellungswarteschlange den Wert 0 meldet, bedeutet dies, dass zum Zeitpunkt dieses Berichts keine Wiederherstellungswarteschlange auftritt. Wenn Ihre Produktionsumgebung jedoch ausgelastet ist, sollten Sie davon ausgehen, dass die Wiederherstellungswarteschlange häufig einen anderen Wert als Null meldet, auch in einer fehlerfreien AlwaysOn-Umgebung. Während der typischen Produktion sollten Sie davon ausgehen, dass dieser Wert zwischen 0 und einem Wert ungleich Null schwankt.
Wenn Sie beobachten, dass die Wiederherstellungswarteschlange im Laufe der Zeit erhöht wird, wird eine weitere Untersuchung garantiert. Diese zusätzliche Aktivität gibt an, dass sich etwas geändert hat. Wenn Sie ein plötzliches Wachstum in der Wiederherstellungswarteschlange beobachten, sind die folgenden Messungen für die Problembehandlung hilfreich:
- Protokoll-Wiederholungsrate (KB/Sek.) (AlwaysOn-Dashboard)
- Redo_rate im DMV-sys.dm_hadr_database_replica_states
Abrufen der Basissätze für die Wiederholungsrate
Überwachen Sie während der fehlerfreien AlwaysOn-Leistung die Wiederholungsrate ihrer Datenbank für die Beschäftigt-Verfügbarkeitsgruppe. Wie sehen sie während der üblicherweise ausgelasteten Geschäftszeiten aus? Was sind diese Raten während der Wartung, wenn große Transaktionen (Indexneuerstellungen, ETL-Prozesse) einen höheren Transaktionsdurchsatz auf dem System fördern? Sie können diese Werte vergleichen, wenn Sie das Wachstum der Wiederherstellungswarteschlange beobachten, um zu bestimmen, was sich geändert hat. Die Arbeitsauslastung ist möglicherweise größer als üblich. Wenn die Wiederholungsrate niedriger ist, kann eine weitere Untersuchung erforderlich sein, um zu ermitteln, warum.
Workloadvolumes sind wichtig
Wenn Sie große Arbeitslasten haben (z. B. eine UPDATE-Anweisung für eine Million Zeilen, eine Indexneuerstellung auf einer 1 Terabyte-Tabelle oder sogar einen ETL-Batch, der Millionen von Zeilen einfügt), sollten Sie davon ausgehen, dass das Wachstum der Wiederherstellungswarteschlange sofort oder im Laufe der Zeit zu sehen ist. Dies wird erwartet, wenn in der Verfügbarkeitsgruppendatenbank plötzlich eine große Anzahl von Änderungen vorgenommen wird.
So diagnostizieren Sie die Wiederherstellungswarteschlange (redo)
Nachdem Sie die Wiederherstellungswarteschlange für eine bestimmte sekundäre Replikatverfügbarkeitsgruppendatenbank identifiziert haben, stellen Sie eine Verbindung mit dem sekundären Replikat her, und fragen sys.dm_exec_requests Sie dann ab, um die wait_type wait_time Wiederherstellungsthreads zu ermitteln. Hier ist eine Abfrage, die in einer Schleife ausgeführt werden kann. Sie suchen nach einer hohen Häufigkeit von einem oder mehreren Wartetypen und sogar Wartezeiten für diese Wartetypen. Hier ist eine Beispielabfrage, die jede Sekunde ausgeführt wird und die Wartezeiten für die Verfügbarkeitsgruppe "agdb" meldet:
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Wichtig
Bei sinnvoller Ausgabe des Wartetyps sollte die Wiederherstellungswarteschlange beobachtet werden, wenn Sie eine der zuvor beschriebenen Methoden verwenden, um diese Bedingung zu überwachen.
In diesem Beispiel werden einige E/A-bezogene Wartetypen gemeldet (PAGEIOLATCH_UP, PAGEIOATCH_EX). Überwachen Sie, ob diese Wartetypen weiterhin die größten wait_times Werte aufweisen, wie in der nächsten Spalte angegeben.

SQL Server-Wiederholungs-Wartetypen
Wenn ein Wartetyp identifiziert wird, lesen Sie den folgenden Artikel SQL Server 2016/2017: Sekundäres Replikatreplikat-Redo-Modell und Leistung der Verfügbarkeitsgruppe – Microsoft Tech Community als Querverweis für allgemeine Wartetypen, die eine Wiederherstellungswarteschlange verursachen, und hilfe zum Beheben des Problems.
Blockierte Wiederholungsthreads auf sekundären Berichtsservern
Wenn Ihre Lösung die Berichterstellung (Abfrage) anhand von Verfügbarkeitsgruppendatenbanken im sekundären Replikat leitet, erhalten diese schreibgeschützten Abfragen Schemastabilitätssperren (Sch-S). Diese Sch-S-Sperren können verhindern, dass Redo-Threads Schemaänderungssperren (Sch-M)-Sperren (auch als "Schemaänderungssperren" bezeichnet) oder LCK_M_SCH_M), um Änderungen der Datendefinitionssprache (Data Definition Language, DDL) vorzunehmen, z ALTER TABLE . B. oder ALTER INDEX. Ein blockierter Redo-Thread kann keine Protokolldatensätze anwenden, bis die Blockierung aufgehoben wird. Dies kann zu einer Wiederherstellungswarteschlange führen.
Öffnen Sie die AlwaysOn_health Xevent-Ablaufverfolgungsdateien im sekundären Replikat mithilfe von SSMS, um nach historischen Nachweisen eines blockierten Wiederholens zu suchen. Suchen Sie nach lock_redo_blocked Ereignissen.

Verwenden Sie Leistungsmonitor, um die Auswirkungen blockierter Wiederholungen aktiv auf die Wiederherstellungswarteschlange zu überwachen. Fügen Sie das SQL Server::D atabase Replica::Redo blocked/sec und SQL Server::D atabase Replica::Recovery Queue counters hinzu. Der folgende Screenshot zeigt einen ALTER TABLE ALTER COLUMN Befehl, der für das primäre Replikat ausgeführt wird, während eine lange ausgeführte Abfrage für dieselbe Tabelle im sekundären Replikat ausgeführt wird. Der Indikator "Wiederholen blockiert/sek " gibt an, dass der ALTER TABLE ALTER COLUMN Befehl ausgeführt wird. Während die lange ausgeführte Abfrage in derselben Tabelle des sekundären Replikats ausgeführt wird, führt jede nachfolgende Änderung der primären Abfrage zu einer Erhöhung der Wiederherstellungswarteschlange.

Überwachen Sie den Wartetyp der Schemaänderungssperre, den der Redo-Thread abzurufen versucht. Verwenden Sie dazu die zuvor beschriebene Abfrage, um die Wartetypen zu überprüfen, die für Wiederholungsvorgänge sys.dm_exec_requestsgemeldet werden. Sie können die zunehmende Wartezeit für die LCK_M_SCH_M fortlaufende Wiederholungsblockierung beobachten.

Einzelthread-Wiederholen
SQL Server führte parallele Wiederherstellung für sekundäre Replikatdatenbanken in Microsoft SQL Server 2016 ein. Wenn beim Ausführen von SQL Microsoft Server 2012 oder Microsoft SQL Server 2014 die Wiederherstellungswarteschlange auftritt, können Sie ein Upgrade auf eine höhere Version des Programms durchführen, um die Leistung der Wiederholen in Ihrer Produktionsumgebung zu verbessern.
In späteren, komplexeren SQL Server-Versionen, in denen parallele Wiederherstellungsarchitektur verwendet wird, kann ein Singlethread-Redo auftreten. In diesen Versionen kann eine SQL Server-Instanz bis zu 100 Threads für eine parallele Wiederholung verwenden. Je nach Anzahl der Prozessoren und Verfügbarkeitsgruppendatenbanken werden parallele Wiederholungsthreads bis zu maximal 100 Gesamtthreads zugeordnet. Wenn die 100-Thread-Wiederholungsgrenze erreicht ist, werden einigen Datenbanken in der Verfügbarkeitsgruppe ein einzelner Wiederholungsthread zugewiesen.
Um zu ermitteln, ob ihre Verfügbarkeitsgruppendatenbank parallele Wiederherstellung verwendet, stellen Sie eine Verbindung mit dem sekundären Replikat her, und verwenden Sie die folgende Abfrage, um die Anzahl der Zeilen (Threads) zu ermitteln, die die Wiederherstellung für die Verfügbarkeitsgruppendatenbank anwenden. Im folgenden Beispiel kann die Wiederherstellungsworkload von paralleler Wiederherstellung profitieren, wenn die "agdb"-Datenbank ein einzelner Thread ist und ihr Befehl lautet DB STARTUP.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Wenn Sie überprüfen, ob Ihre Datenbank einen Einzelthread-Redo verwendet, überprüfen Sie den zuvor beschriebenen Algorithmus, um zu ermitteln, ob SQL Server die Anzahl von 100 Arbeitsthreads überschreitet, die für die parallele Wiederherstellung reserviert sind. Eine solche Bedingung kann der Grund dafür sein, dass die "agdb"-Datenbank nur einen einzelnen Thread für die Wiederherstellung verwendet.
SQL Server 2022 verwendet jetzt einen neuen parallelen Wiederherstellungsalgorithmus, sodass Arbeitsthreads für die parallele Wiederherstellung basierend auf der Workload zugewiesen werden. Dadurch wird die Chance vermieden, dass eine ausgelastete Datenbank in einer Singlethread-Wiederherstellung verbleibt. Weitere Informationen finden Sie im Abschnitt "Voraussetzungen, Einschränkungen und Empfehlungen für AlwaysOn-Verfügbarkeitsgruppen" im Abschnitt "Threadverwendung nach Verfügbarkeitsgruppen ".