Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel hilft Ihnen bei der Diagnose von intermittierenden Verbindungstimeouts, die zwischen Verfügbarkeitsgruppenreplikaten gemeldet werden.
Symptome und Auswirkungen von intermittierenden Verfügbarkeitsgruppen-Replikat-Verbindungstimeouts
Das Abfragen primärer und sekundärer Replikate gibt unterschiedliche Ergebnisse zurück.
Schreibgeschützte Workloads, die sekundäre Replikate abfragen, können veraltete Daten abfragen. Wenn zeitweilige Replikatverbindungstimeouts auftreten, werden Änderungen an Daten in der primären Replikatdatenbank noch nicht in der sekundären Datenbank widergespiegelt, wenn Sie dieselben Daten abfragen. Weitere Informationen finden Sie im Abschnitt " Datenlatenz" im Abschnitt "Sekundäres Replikat ".
Verfügbarkeitsgruppe für Diagnoseberichte nicht synchronisiert
Das Always On-Dashboard in SQL Server Management Studio meldet möglicherweise eine fehlerhafte Verfügbarkeitsgruppe mit Replikaten im Zustand "Nicht synchronisieren" . Möglicherweise beobachten Sie auch die Always On-Dashboard-Berichtsreplikate, die sich im Zustand "Nicht synchronisieren" befinden.

Wenn Sie die SQL Server-Fehlerprotokolle dieser Replikate überprüfen, können Sie Meldungen wie folgendes beobachten, die darauf hinweisen, dass zwischen den Replikaten in der Verfügbarkeitsgruppe ein Verbindungstimeout aufgetreten ist:
Fehlerprotokoll aus dem primären Replikat
2023-02-15 07:10:55.500 spid43s Always On availability groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Fehlerprotokoll aus dem sekundären Replikat
2023-02-15 07:11:03.100 spid31s A connection time-out has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Zeitweilige Verbindungsprobleme können sich auf die Failoverbereitschaft eines sekundären Replikats auswirken.
Wenn Sie die Verfügbarkeitsgruppe für automatisches Failover konfigurieren und der synchrone Commit-Failoverpartner zeitweise von der primären Verbindung getrennt wird, ist das automatische Failover möglicherweise nicht erfolgreich.
Sie können abfragen sys.dm_hadr_database_replia_cluster_states , ob die Verfügbarkeitsgruppendatenbank zu diesem Zeitpunkt failoverbereit ist. Hier ist ein Beispiel für die Ergebnisse, wenn der Spiegelungsendpunkt im sekundären Replikat beendet wurde:
SELECT drcs.database_name, drcs.is_failover_ready, ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ar.replica_id=drcs.replica_id
WHERE ars.role_desc='SECONDARY'

Automatisches Failover bringt die Verfügbarkeitsgruppe möglicherweise nicht online in der primären Rolle auf dem Failoverpartnercomputer, wenn failover mit einem Replikatverbindungstimeout übereinstimmt.
Was geben die Verbindung-Timeoutfehler an?
Der Standardwert ist 10 Sekunden für die Verfügbarkeitsgruppenreplikateinstellung. SESSION_TIMEOUT Diese Einstellung ist für jedes Replikat konfiguriert. Es bestimmt, wie lange das Replikat wartet, um eine Antwort von seinem Partnerreplikat zu erhalten, bevor ein Verbindungstimeout gemeldet wird. Wenn ein Replikat keine Antwort vom Partnerreplikat erhält, meldet es ein Verbindungstimeout im Microsoft SQL Server-Fehlerprotokoll und im Windows-Anwendungsprotokoll. Das Replikat, das das Timeout meldet, versucht sofort, eine erneute Verbindung herzustellen, und versucht weiterhin alle fünf Sekunden.
In der Regel wird das Verbindungstimeout erkannt und nur von einem Replikat gemeldet. Das Timeout der Verbindung kann jedoch von beiden Replikaten gleichzeitig gemeldet werden. Es gibt unterschiedliche Versionen dieser Nachricht, je nachdem, ob das Verbindungstimeout mit einer zuvor eingerichteten Verbindung oder einer neuen Verbindung aufgetreten ist:
Message 35206 A connection timeout has occurred on a previously established connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Message 35201 A connection timeout has occurred while attempting to establish a connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Das Partnerreplikat erkennt möglicherweise kein Timeout. Wenn dies der Fall ist, wird möglicherweise Nachricht 35201 oder 35206 angezeigt. Wenn dies nicht der Fall ist, meldet sie einen Verbindungsverlust an jede der Verfügbarkeitsgruppendatenbanken:
Message 35267 Always On Availability Groups connection with primary/secondary database terminated for primary/secondary database '<databasename>' on the availability replica '<replicaname>' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Hier ist ein Beispiel dafür, was SQL Server dem Fehlerprotokoll meldet: Wenn Sie den Spiegelungsendpunkt des primären Replikats beenden, erkennt das sekundäre Replikat ein Verbindungstimeout, und Nachrichten 35206 und 35267 werden im sekundären Replikatfehlerprotokoll gemeldet:
2023-02-15 07:11:03.100 spid31s A connection timeout has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID:[<replicaid>]. This is an informational message only. No user action is required.
In diesem Beispiel hat das primäre Replikat kein Verbindungstimeout erkannt, da es weiterhin mit der sekundären kommunizieren konnte und die Meldung 35267 für jede Verfügbarkeitsgruppendatenbank gemeldet wurde (in diesem Beispiel gibt es nur eine Datenbank, "agdb"):
2023-02-15 07:10:55.500 spid43s Always On Availability Groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
Ursachen von Replikatverbindungstimeouts
Anwendungsproblem
SQL Server ist aus mehreren Gründen möglicherweise ausgelastet und bedient die Spiegelungsendpunktverbindung nicht innerhalb des Verfügbarkeitsgruppenzeitraums SESSION_TIMEOUT . Dies führt zu einem Timeout der Verbindung. Einige dieser Gründe sind:
SQL Server hat eine CPU-Auslastung von 100 Prozent. Dies bedeutet, dass SQL Server oder eine andere Anwendung die CPU für Sekunden gleichzeitig fährt.
SQL Server führt zu Nichterreichung von Zeitplanereignissen.SQL Server experiences non-yielding scheduler events. SQL Server-Threads sind dafür verantwortlich, dass der Scheduler (CPU) für andere Threads zur Ausführung ihrer Arbeit verantwortlich ist, wenn ein Thread nicht rechtzeitig zur Folge hat.
SQL Server erlebt die Erschöpfung des Workerthreads, Probleme mit nicht genügend Arbeitsspeicher oder Anwendungsproblemen, die sich auf die Fähigkeit auswirken, die Spiegelungsendpunktverbindung zu verwenden.
Netzwerkproblem
Dies erfordert, dass Sie Netzwerkablaufverfolgungsprotokolle für die primären und sekundären Replikate sammeln, wenn der Fehler ausgelöst wird. Dazu können Sie die Netzwerklatenz und verworfene Pakete untersuchen.
So wird's gemacht: Diagnostizieren von Replikatverbindungstimeouts
Für das Problem von Anwendungsproblemen, die verhindern, dass SQL Server die Verbindung mit dem Partnerreplikat gewartet, wird in diesem Abschnitt erläutert, wie die SQL Server-Protokolle analysiert werden. Diese Tipps können Ihnen helfen, die Ursache für die Replikatverbindungstimeouts zu identifizieren. Dieser Abschnitt endet mit erweiterten Anleitungen zum Sammeln von Netzwerkablaufverfolgungen, wenn die Verbindungstimeouts auftreten, damit Sie den Netzwerkstatus überprüfen können.
Bewerten der Anzeigedauer und des Standorts von Replikatverbindungstimeouts
Überprüfen Sie den Verlauf, die Häufigkeit und Trends der Verbindungstimeouts. Die Verwendung der nachrichten, die Sie im SQL Server-Fehlerprotokoll finden, ist eine hervorragende Möglichkeit, dies zu tun. Wo werden die Verbindungstimeouts gemeldet? Werden sie konsistent über das primäre oder das sekundäre Replikat gemeldet? Wann sind die Fehler aufgetreten? Sind sie in einer bestimmten Woche des Monats, Wochentags oder Tageszeit aufgetreten? Entspricht andere geplante Wartung oder Batchverarbeitung den Zeiten, zu denen die Verbindungstimeouts beobachtet werden? Diese Bewertung kann Ihnen beim Bereich helfen und die Verbindungstimeouts korrelieren, um die Ursache zu identifizieren.
Überprüfen der AlwaysOn_health erweiterten Ereignissitzung
Die AlwaysOn_health erweiterte Ereignissitzung wurde erweitert, um das ucs_connection_setup Ereignis einzuschließen, das ausgelöst wird, wenn ein Replikat eine Verbindung mit seinem Partnerreplikat aufbaut. Dies kann hilfreich sein, wenn Probleme mit dem Verbindungstimeout behoben werden.
Notiz
Das ucs_connection_setup erweiterte Ereignis wurde den neuesten kumulativen SQL Server-Updates hinzugefügt. Sie müssen die neuesten kumulativen Updates ausführen, um dieses erweiterte Ereignis zu beobachten.
Abfrage immer auf verteilten Verwaltungsansichten (DISTRIBUTED Management Views, DMVs)
Sie können Always On DMVs nach weiteren Informationen zum verbundenen Zustand des Replikats abfragen. Diese Abfrage meldet nur den verbundenen Zustand und alle Fehler, die dem Verbindungstimeout beim Auftreten der Probleme zugeordnet sind. Wenn die Verbindungsprobleme zeitweise auftreten, erfasst die Abfrage möglicherweise nicht einfach den getrennten Zustand.
SELECT ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
Das folgende Beispiel zeigt einen dauerhaften getrennten Zustand, da der Spiegelungsendpunkt des primären Replikats beendet wurde. Durch Abfragen des primären Replikats kann always On DMV die primären und alle sekundären Replikate melden (der Endpunkt ist im primären Replikat deaktiviert).

Durch Abfragen des sekundären Replikats meldet die Always On DMVs nur das sekundäre Replikat.

Überprüfen der erweiterten Ereignissitzung "Always On"
Stellen Sie eine Verbindung mit jedem Replikat mithilfe von SQL Server Management Studio (SSMS) Objekt-Explorer her, und öffnen Sie die
AlwaysOn_healtherweiterten Ereignisdateien.Wechseln Sie in SSMS zu "Datei>öffnen", und wählen Sie dann "Erweiterte Ereignisdateien zusammenführen" aus.
Wählen Sie die Schaltfläche Hinzufügen aus.
Navigieren Sie im Dialogfeld "Datei öffnen " zu den Dateien im SQL Server \LOG-Verzeichnis .
Drücken Sie CTRL, und wählen Sie dann die Dateien aus, deren Name mit "AlwaysOn_healthxxx.xel" beginnt.
Wählen Sie "Öffnen" und dann "OK" aus.
In SSMS sollte ein neues Fenster mit Registerkartenformat angezeigt werden, in dem die AlwaysOn-Ereignisse angezeigt werden.
Der folgende Screenshot zeigt die
AlwaysOn_healthDaten aus dem sekundären Replikat. Das erste umrissene Feld zeigt den Verbindungsverlust an, nachdem der Endpunkt des primären Replikats beendet wurde. Das zweite umrissene Feld zeigt den Verbindungsfehler an, der auftritt, wenn das sekundäre Replikat das nächste Mal versucht, eine Verbindung mit dem primären Replikat herzustellen.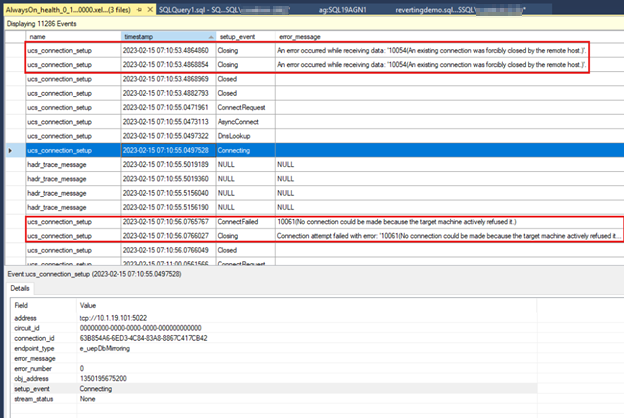

Überprüfen Sie, ob ereignisse, die keine Erträge verursachen, Verbindungstimeouts verursachen
Einer der häufigsten Gründe dafür, dass ein Verfügbarkeitsreplikat die Partnerreplikatverbindung nicht bedienen kann, ist ein nicht ertragsorientierter Scheduler. Weitere Informationen zu nicht ertragfreien Zeitplänen finden Sie unter Problembehandlung bei der SQL Server-Planung und -Rendite.
SQL Server verfolgt nicht ertragende Zeitplanereignisse, die so kurz wie 5 bis 10 Sekunden sind. Sie meldet diese Ereignisse im TrackingNonYieldingScheduler Datenpunkt in der sp_server_diagnostics query_processing Komponentenausgabe.
Führen Sie die folgenden Schritte aus, um nach Nichtertragungsereignissen zu suchen, die zu Zeitüberschreitungen der Replikatverbindung führen können:
Erstellen Sie einen SQL-Agent-Auftrag, der alle fünf Sekunden aufgezeichnet
sp_server_diagnosticswird.Planen Sie diesen Auftrag auf dem Server, der das Verbindungstimeout nicht meldet. Wenn Server A-Replikat das Timeout der Replikatverbindung in seinem Fehlerprotokoll meldet, richten Sie den SQL-Agent-Auftrag für das Partnerreplikat, Server B, ein. Wenn verbindungstimeouts auf beiden Replikaten angezeigt werden, erstellen Sie den Auftrag für beide Replikate.
Führen Sie die folgende Batchdatei aus, um einen Auftrag zu erstellen, der alle fünf Sekunden ausgeführt wird
sp_server_diagnostics, fügt die Ausgabe an eine Textdatei an und startet dann den Auftrag. Der Befehl im folgenden Beispielsp_server_diagnostics 5wird alle fünf Sekunden ausgeführt. Daher ist es nicht erforderlich, diesen Auftrag alle fünf Sekunden auszuführen, einfach den Auftrag zu starten, und er wird bis alle fünf Sekunden ausgeführt:USE [msdb] GO DECLARE @ReturnCode INT SELECT @ReturnCode = 0 DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Run sp_server_diagnostics', @owner_login_name=N'sa', @job_id = @jobId OUTPUT /****** Object: Step [Run SP_SERVER_DIAGNOSTICS] Script Date: 2/15/2023 4:20:41 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Run SP_SERVER_DIAGNOSTICS', @subsystem=N'TSQL', @command=N'sp_server_diagnostics 5', @database_name=N'master', @output_file_name=N'D:\cases\2423\sp_server_diagnostics_output.out', @flags=2 EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' EXEC sp_start_job 'Run sp_server_diagnostics'Notiz
Ändern Sie
@output_file_namein diesen Befehlen einen gültigen Pfad, und geben Sie einen Dateinamen an.
Analysieren der Ergebnisse
Wenn ein Verbindungstimeout gemeldet wird, notieren Sie sich den Zeitstempel des Timeoutereignisses, das im SQL Server-Fehlerprotokoll angezeigt wird. Für die Replikate im folgenden Beispiel SQL19AGN1 wurde das Timeout der Replikatverbindung gemeldet. Daher wurde ein SQL-Agent-Auftrag auf SQL19AGN2dem Partnerreplikat erstellt. Anschließend wurde im Fehlerprotokoll am 07:24:31 ein Verbindungstimeout gemeldet SQL19AGN1 .

Als Nächstes wird die Ausgabe des SQL-Agent-Auftrags, der ausgeführt wird, sp_server_diagnostics um die gemeldete Zeit überprüft, insbesondere die Überprüfung des TrackingNonYieldingScheduler Datenpunkts in der query_processing Komponentenausgabe. Die Ausgabe meldet, dass ein nicht ertragfreier Zeitplan (als hexadezimaler Wert ungleich Null) auf dem Server SQL19AGN2 (bei 07:24:33) um die Zeit nachverfolgt wurde, zu der das Zeitlimit für die Replikatverbindung an SQL19AGN1 gemeldet wurde (bei 07:24:31).
Notiz
Die folgende sp_server_diagnostics Ausgabe wird verkettet, um sowohl den (Zeitstempel) als query_processing TrackingNonYieldingScheduler auch die create_time Ergebnisse anzuzeigen.

Untersuchen eines nicht ertragenden Zeitplanereignisses
Wenn Sie anhand der früheren Diagnoseschritte überprüft haben, dass ein Nichtertragungsereignis das Zeitlimit für die Replikatverbindung verursacht hat:
Identifizieren Sie die Workloads, die zum Zeitpunkt der Ausführung der nicht ertragenden Ereignisse in SQL Server ausgeführt werden.
Ähnlich wie bei den Replikatverbindungstimeouts suchen Sie nach Trends in diesen Ereignissen während des Monats, des Tages oder der Woche, die sie auftreten.
Erfassen Sie die Ablaufverfolgung des Leistungsmonitors auf dem System, auf dem das ereignis nicht ertragende Ereignis erkannt wurde.
Sammeln Sie Schlüsselleistungsindikatoren für Systemressourcen, einschließlich Prozessor::% Prozessorzeit, Arbeitsspeicher::Verfügbare MBytes, logischer Datenträger::Avg Disk Queue Length, and Logical Disk::Avg Disk sec/Transfer.
Wenn dies erforderlich ist, öffnen Sie einen SQL Server-Supportvorfall, um weitere Unterstützung bei der Suche nach der Ursache für diese ereignisse ohne Ertrag zu erhalten. Teilen Sie die Protokolle, die Sie zur weiteren Analyse gesammelt haben.
Erweiterte Datensammlung: Sammeln der Netzwerkablaufverfolgung während des Verbindungstimeouts
Wenn die vorherige Diagnose der SQL Server-Anwendung keine Ursache lieferte, sollten Sie das Netzwerk überprüfen. Eine erfolgreiche Analyse des Netzwerks erfordert, dass Sie eine Netzwerkablaufverfolgung sammeln, die die Zeit des Verbindungstimeouts abdeckt.
Das folgende Verfahren startet eine Windows-Netzwerkablaufverfolgung netsh für die Replikate, für die die Verbindungstimeouts in den SQL Server-Fehlerprotokollen gemeldet werden. Eine geplante Windows-Ereignisaufgabe wird ausgelöst, wenn eine der SQL Server-Verbindungsfehler im Anwendungsprotokoll aufgezeichnet wird. Die geplante Aufgabe führt einen Befehl aus, um die netsh Netzwerkablaufverfolgung zu beenden, sodass die wichtigsten Netzwerkablaufverfolgungsdaten nicht überschrieben werden. Bei diesen Schritten wird auch ein Pfad von *F:* für die Batch- und Ablaufverfolgungsprotokolle vorausgesetzt. Passen Sie diesen Pfad an Ihre Umgebung an.
Starten Sie eine Netzwerkablaufverfolgung, wie im folgenden Codeausschnitt gezeigt, in den beiden Replikaten, auf denen die Verbindungstimeouts auftreten:
netsh trace start capture=yes persistent=yes overwrite=yes maxsize=500 tracefile=f:\trace.etlErstellen Sie geplante Windows-Aufgaben, die die
netshAblaufverfolgung für Ereignisse 35206 oder 35267 beenden. Sie können diese Aufgaben in einer Administrativen Befehlszeile erstellen:schtasks /Create /tn Event35206Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35206] /f /RL HIGHEST schtasks /Create /tn Event35267Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35267] /f /RL HIGHESTNachdem das Ereignis auftritt und die Netzwerkablaufverfolgungen beendet und erfasst werden, können Sie die
ONEVENTAufgaben löschen:PS C:\Users\sqladmin> Schtasks /Delete /tn Event35206Task /F PS C:\Users\sqladmin> Schtasks /Delete /tn Event35267Task /F
Die Analyse der Netzwerkablaufverfolgung liegt außerhalb des Bereichs dieser Problembehandlung. Wenn Sie die Netzwerkablaufverfolgung nicht interpretieren können, wenden Sie sich an das Microsoft SQL Server-Supportteam, und stellen Sie die Ablaufverfolgung zusammen mit anderen angeforderten Protokolldateien für die Ursachenanalyse bereit.
Was kann ich sonst tun, um die Verbindungstimeouts zu verringern?
Die Standardverfügbarkeitsgruppe ist SESSION_TIMEOUT10 Sekunden lang konfiguriert. Möglicherweise können Sie die Verbindungstimeouts verringern, indem Sie die Verfügbarkeitsgruppenreplikateigenschaft SESSION_TIMEOUT anpassen. Diese Einstellung ist pro Replikat. Passen Sie sie für das primäre und jedes betroffene sekundäre Replikat an. Hier ist ein Beispiel für die Syntax. Der Standardwert SESSION_TIMEOUT ist 10. Daher könnten Sie 15 als nächsten Wert verwenden.
ALTER AVAILABILITY GROUP ag
MODIFY REPLICA ON 'SQL19AGN1' WITH (SESSION_TIMEOUT = 15);