Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel hilft Ihnen beim Beheben von Problemen, die während des automatischen Failovers in Microsoft SQL Server auftreten.
Ursprüngliche Produktversion: SQL Server
Ursprüngliche KB-Nummer: 2833707
Zusammenfassung
SQL Server AlwaysOn-Verfügbarkeitsgruppen können für automatisches Failover konfiguriert werden. Wenn ein Integritätsproblem in der Instanz von SQL Server erkannt wird, die das primäre Replikat hostet, kann die primäre Rolle auf den automatischen Failoverpartner (sekundäres Replikat) übertragen werden. Das sekundäre Replikat kann jedoch nicht immer zur primären Rolle übertragen werden. In einigen Fällen kann sie nur auf die RESOLVING Rolle umgestellt werden. In diesem Fall verfügt kein Replikat über die primäre Rolle, es sei denn, das primäre Replikat kehrt in einen fehlerfreien Zustand zurück. Darüber hinaus kann auf die Verfügbarkeitsdatenbanken nicht zugegriffen werden.
In diesem Artikel werden einige häufige Ursachen eines erfolglosen automatischen Failovers aufgeführt, und es werden die Schritte erläutert, die Sie ausführen können, um die Ursache dieser Fehler zu diagnostizieren.
Symptome, wenn ein automatisches Failover erfolgreich ausgelöst wird
Wenn ein automatisches Failover auf der Instanz von SQL Server ausgelöst wird, die das primäre Replikat hostet, wechselt das sekundäre Replikat zu der RESOLVING Rolle und dann zur primären Rolle. Obwohl der Prozess erfolgreich ist, werden Fehlereinträge im SQL Server-Protokollbericht protokolliert, der dem folgenden Text ähnelt:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

Notiz
Das sekundäre Replikat wechselt erfolgreich von einem RESOLVING_NORMAL Zustand zu einem PRIMARY_NORMAL Zustand.
Symptome, wenn ein automatisches Failover nicht erfolgreich ist
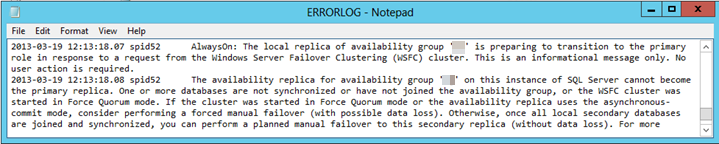
Wenn ein automatisches Failoverereignis nicht erfolgreich ist, wechselt das sekundäre Replikat nicht erfolgreich zur primären Rolle. Daher meldet das Verfügbarkeitsreplikat, dass sich dieses Replikat in einem RESOLVING Zustand befindet. Darüber hinaus melden die Verfügbarkeitsdatenbanken, dass sie sich in einem NOT SYNCHRONIZING Zustand befinden, und Anwendungen können nicht auf diese Datenbanken zugreifen.
In der folgenden Abbildung meldet SQL Server Management Studio beispielsweise, dass sich das sekundäre Replikat in einem RESOLVING Zustand befindet, da der automatische Failoverprozess das sekundäre Replikat nicht in die primäre Rolle übertragen konnte.
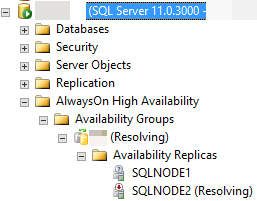
In den folgenden Abschnitten werden verschiedene mögliche Gründe erläutert, warum das automatische Failover möglicherweise nicht erfolgreich ist und wie sie jede Ursache diagnostizieren.
Fall 1: Der Wert "Maximale Fehler im angegebenen Zeitraum" ist erschöpft.
Die Verfügbarkeitsgruppe verfügt über Windows-Clusterressourceneigenschaften, z. B. die maximalen Fehler in der Eigenschaft "Angegebene Periode ". Diese Eigenschaft wird verwendet, um die unbestimmte Bewegung einer gruppierten Ressource zu vermeiden, wenn mehrere Knotenfehler auftreten.
Um zu untersuchen und zu diagnostizieren, ob dies die Ursache für ein erfolgloses Failover ist, überprüfen Sie das Windows-Clusterprotokoll (Cluster.log), und überprüfen Sie dann die Eigenschaft.
Schritt 1: Überprüfen der Daten im Windows-Clusterprotokoll (Cluster.log)
Verwenden Sie Windows PowerShell, um das Windows-Clusterprotokoll auf dem Clusterknoten zu generieren, der das primäre Replikat hosten soll. Führen Sie dazu das folgende Cmdlet in einem PowerShell-Fenster mit erhöhten Rechten auf der Instanz von SQL Server aus, die das primäre Replikat hostet:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15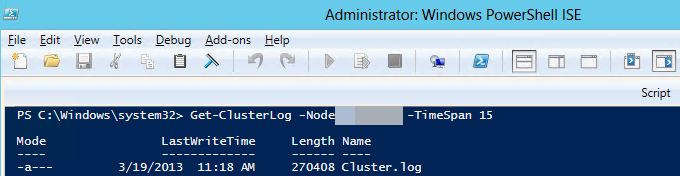
[!HINWEISE]
- Der
-TimeSpan 15Parameter in diesem Schritt geht davon aus, dass das Problem, das während der vorherigen 15 Minuten diagnostiziert wird, aufgetreten ist. - Standardmäßig wird die Protokolldatei in %WINDIR%\cluster\reports erstellt.
- Der
Öffnen Sie die Cluster.log Datei im Editor, um das Windows-Clusterprotokoll zu überprüfen.
Wählen Sie im Editor "Suchen bearbeiten>" aus, und suchen Sie dann am Ende der Datei nach der Zeichenfolge "failoverCount". In den Ergebnissen sollten Sie eine Nachricht finden, die der folgenden Meldung ähnelt:
Fehler beim Ausführen des Gruppenressourcennamens<>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2

Schritt 2: Überprüfen der maximalen Fehler in der angegebenen Period-Eigenschaft
Starten Sie den Failovercluster-Manager.
Wählen Sie im Navigationsbereich "Rollen" aus.
Klicken Sie im Rollenbereich mit der rechten Maustaste auf die gruppierte Ressource, und wählen Sie dann "Eigenschaften" aus.
Wählen Sie die Registerkarte "Failover " und dann den Wert für " Maximale Fehler" im angegebenen Zeitraum aus.
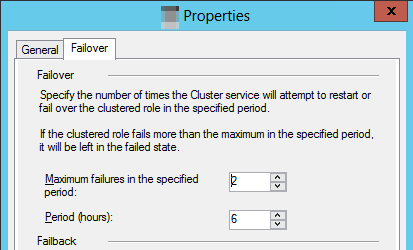
Notiz
Das Standardverhalten gibt an, dass, wenn die gruppierte Ressource dreimal innerhalb von sechs Stunden fehlschlägt, sie im fehlerhaften Zustand verbleiben sollte. Bei einer Verfügbarkeitsgruppe bedeutet dies, dass das Replikat im
RESOLVINGZustand verbleibt.
Fazit
Nachdem Sie das Protokoll analysiert haben, stellen Sie fest, dass der FailoverCount-Wert von 3 größer als der berechneteFailoverThreshold-Wert von 2 ist. Daher kann der Windows-Cluster den Failovervorgang der Verfügbarkeitsgruppenressource für den Failoverpartner nicht abschließen.
Lösung
Um dieses Problem zu beheben, erhöhen Sie die maximalen Fehler im angegebenen Punktwert .
Notiz
Wenn Sie diesen Wert erhöhen, kann das Problem möglicherweise nicht behoben werden. Es kann ein kritischeres Problem geben, das dazu führt, dass die Verfügbarkeitsgruppe innerhalb eines kurzen Zeitraums mehrmals fehlschlägt. Dieser Zeitraum beträgt standardmäßig 15 Minuten. Das Erhöhen dieses Werts kann dazu führen, dass die Verfügbarkeitsgruppe mehr Mal fehlschlägt und in einem fehlgeschlagenen Zustand verbleibt. Es wird empfohlen, die aggressive Problembehandlung zu verwenden, um zu ermitteln, warum das automatische Failover weiterhin auftritt.
Fall 2: Unzureichende NT Authority\SYSTEM-Kontoberechtigungen
Die SQL Server-Datenbank-Engine Ressourcen-DLL stellt eine Verbindung mit der Instanz von SQL Server, die das primäre Replikat hosten, mithilfe von ODBC zum Überwachen des Zustands in Verbindung. Die Anmeldeinformationen, die für diese Verbindung verwendet werden, sind das lokale SQL Server-Anmeldekonto NT AUTHORITY\SYSTEM . Standardmäßig erhält dieses lokale Anmeldekonto die folgenden Berechtigungen:
- Ändern einer beliebigen Verfügbarkeitsgruppe
- Verbinden von SQL
- Serverstatus anzeigen
Wenn für das NT AUTHORITY\SYSTEM Anmeldekonto keine dieser Berechtigungen für den automatischen Failoverpartner (das sekundäre Replikat) vorhanden ist, kann SQL Server die Integritätserkennung nicht starten, wenn ein automatisches Failover auftritt. Daher kann das sekundäre Replikat nicht zur primären Rolle wechseln. Um zu untersuchen und zu diagnostizieren, ob dies die Ursache ist, überprüfen Sie das Windows-Clusterprotokoll. Gehen Sie dazu wie folgt vor:
Verwenden Sie Windows PowerShell, um das Windows-Clusterprotokoll auf dem Clusterknoten zu generieren. Führen Sie dazu das folgende Cmdlet in einem PowerShell-Fenster mit erhöhten Rechten auf der Instanz von SQL Server aus, die das sekundäre Replikat hostet, das nicht in die primäre Rolle übergeht:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
Öffnen Sie die Cluster.log Datei im Editor, um das Windows-Clusterprotokoll zu überprüfen.
Suchen Sie den Fehlereintrag, der dem folgenden Text ähnelt:
Fehler beim Ausführen des Diagnosebefehls. Der Benutzer besitzt keine Berechtigung zum Ausführen dieser Aktion.
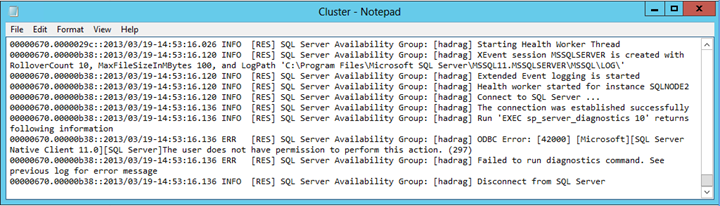
Fazit
Die Cluster.log Datei meldet, dass ein Berechtigungsproblem vorliegt, wenn SQL Server den Diagnosebefehl ausführt. In diesem Beispiel wurde der Fehler durch Entfernen der Berechtigung "View server state" aus dem NT AUTHORITY\SYSTEM Anmeldekonto in der Instanz von SQL Server verursacht, die das sekundäre Replikat eines automatischen Failoverpaars hosten.
Lösung
Um dieses Problem zu beheben, erteilen Sie dem NT AUTHORITY\SYSTEM Anmeldekonto ausreichende Berechtigungen für die Integritätserkennung der SQL Server-Datenbank-Engine Ressourcen-DLL.
Fall 3: Die Verfügbarkeitsdatenbanken befinden sich nicht in einem SYNCHRONIZED-Zustand
Um automatisch fehlschlagen zu können, müssen alle Verfügbarkeitsdatenbanken, die in der Verfügbarkeitsgruppe definiert sind, in einem SYNCHRONIZED Zustand zwischen dem primären Replikat und dem sekundären Replikat liegen. Wenn ein automatisches Failover auftritt, muss diese Synchronisierungsbedingung erfüllt sein, um sicherzustellen, dass kein Datenverlust auftritt. Wenn sich daher eine Verfügbarkeitsdatenbank in der Verfügbarkeitsgruppe im Synchronisierungs- oder NOT SYNCHRONIZED Zustand befindet, übergibt das automatische Failover das sekundäre Replikat nicht erfolgreich in die primäre Rolle.
Weitere Informationen zu den erforderlichen Bedingungen für ein automatisches Failover finden Sie unter den Bedingungen, die für ein automatisches Failover erforderlich sind, und die Synchron-Commit-Replikate unterstützen zwei Einstellungsabschnitte von Failover- und Failovermodi (Always On Availability Groups).
Um zu untersuchen und zu diagnostizieren, ob dies die Ursache eines nicht erfolgreichen Failovers ist, überprüfen Sie das SQL Server-Fehlerprotokoll. Sie sollten einen Fehlereintrag finden, der dem folgenden Text ähnelt:
Mindestens eine Datenbank wird nicht synchronisiert oder ist der Verfügbarkeitsgruppe nicht beigetreten.
Führen Sie die folgenden Schritte aus, um zu überprüfen, ob sich die Verfügbarkeitsdatenbanken im SYNCHRONIZED Zustand befinden:
Stellen Sie eine Verbindung mit dem sekundären Replikat her.
Führen Sie das folgende SQL-Skript aus, um den
is_failover_readyWert für alle Verfügbarkeitsdatenbanken in der Verfügbarkeitsgruppe zu überprüfen, die nicht erfolgreich war.Notiz
Ein Wert von Null für eine der Verfügbarkeitsdatenbanken kann ein automatisches Failover verhindern. Dieser Wert gibt an, dass die Verfügbarkeitsdatenbank nicht
SYNCHRONIZEDvorhanden war.SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)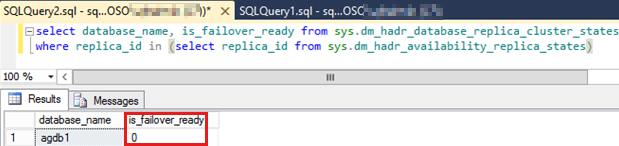
Fazit
Ein erfolgreiches automatisches Failover der Verfügbarkeitsgruppe erfordert, dass alle Verfügbarkeitsdatenbanken im SYNCHRONIZED Zustand sind. Weitere Informationen zu Verfügbarkeitsmodi finden Sie unter Verfügbarkeitsmodi in AlwaysOn-Verfügbarkeitsgruppen.
Fall 4: Die Konfiguration "Protokollverschlüsselung erzwingen" wird für die Clientprotokolle für sekundäres Replikat (primäres Ziel) ausgewählt, obwohl das Replikat nicht für die Verschlüsselung konfiguriert ist.
Wenn der primäre Server während des Failovers ein Integritätsproblem erkennt, versucht die Cluster-DLL für Failoverpartner (sekundäres Replikat), eine Verbindung mit dem lokalen Replikat herzustellen, um die Integritätsüberwachung zu initiieren. Dies ist Teil des Übergangs zur primären Rolle. Wenn das sekundäre Replikat nicht für die Verschlüsselung konfiguriert ist, die Einstellung " Protokollverschlüsselung erzwingen" jedoch versehentlich in der Clientkonfiguration festgelegt ist, schlägt die Verbindung fehl, und das Failover kann nicht auftreten.
So überprüfen Sie diese Konfiguration:
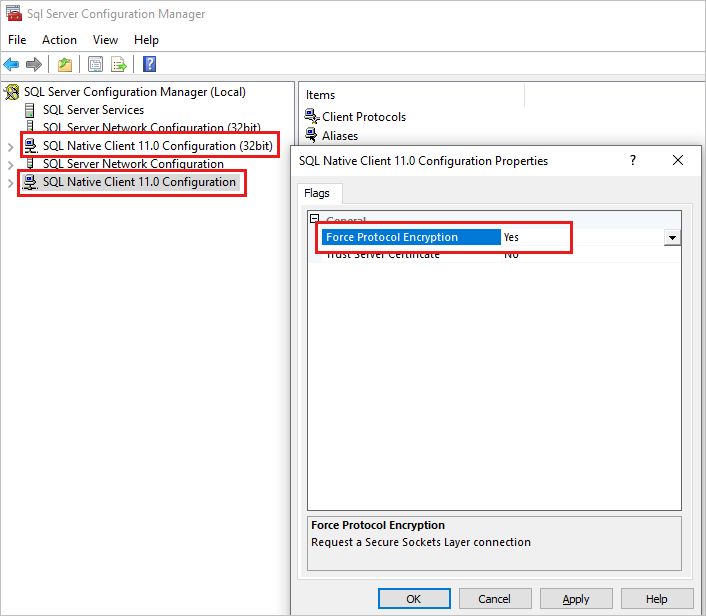
- Starten Sie den SQL Server-Konfigurations-Manager.
- Klicken Sie im linken Bereich mit der rechten Maustaste auf die SQL Native Client 11.0-Konfiguration, und wählen Sie dann "Eigenschaften" aus.
- Aktivieren Sie im Dialogfeld die Einstellung " Protokollverschlüsselung erzwingen ". Wenn sie auf "Ja" festgelegt ist, ändern Sie den Wert in "Nein".
- Testen Sie das Failover erneut.
Fazit
Sql Server Always On-Integritätsüberwachung verwendet eine lokale ODBC-Verbindung, um die SQL Server-Integrität zu überwachen. Die Erzwingungsprotokollverschlüsselung sollte im Abschnitt "Clientkonfiguration" von SQL Server-Konfigurations-Manager nur aktiviert werden, wenn SQL Server selbst so konfiguriert wurde, dass Verschlüsselungen in SQL Server-Konfigurations-Manager im Abschnitt "SQL Server-Netzwerkkonfiguration" erzwungen wurden. Weitere Informationen finden Sie unter Aktivieren von verschlüsselten Verbindungen mit der Datenbank-Engine.
Fall 5: Leistungsprobleme bei sekundären Replikaten oder Knoten führen dazu, dass Always On-Integritätsprüfungen fehlschlagen
Bevor sie vom primären Replikat zum sekundären Replikat fehlschlagen, stellt SQL Server Datenbank-Engine Ressourcen-DLL eine Verbindung mit dem sekundären Replikat her, um die Integrität des Replikats zu ermitteln. Wenn diese Verbindung aufgrund von Leistungsproblemen im sekundären Replikat fehlschlägt, tritt kein automatisches Failover auf.
Führen Sie die folgenden Schritte aus, um zu untersuchen und zu diagnostizieren, ob dies die Ursache ist:
Überprüfen Sie das Clusterprotokoll im sekundären Replikat, um nach der Fehlermeldung zu suchen: "Der Anmeldevorgang kann aufgrund der Verzögerung beim Öffnen der Serververbindung nicht abgeschlossen werden".
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.Diese Situation kann auftreten, wenn das Failover zu einem sekundären SQL Server-Replikat erfolgt, das über eine ausgelastete Workload verfügt. Dies könnte die Antwort von SQL Server auf den HADR-Verbindungsanforderungsversuch verzögern und einen erfolgreichen Failoverversuch verhindern.
Um festzustellen, ob der Druck auf Systemplaner besteht, verwenden Sie SQL Server Management Studio, um das folgende Skript für das sekundäre Replikat auszuführen:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' ENDEs folgt eine Beispielausgabe der vorherigen Abfrage:
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 26- 21 185 2020-10-06 01:27:29.343 1216 13:46 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 13:46 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 Hohe Werte, die für die Terminplanung gemeldet
WorkersWaitingForCpuwurden undRequestWaitingForThreadsangeben, dass die Terminplanung auftritt und sql Server die aktuelle Arbeitsauslastung nicht rechtzeitig verarbeiten kann.
Lösung
Wenn dieses Problem auftritt, sollten Sie die Arbeitsauslastung auf dem sekundären Replikat neu ausgleichen oder die Verarbeitungsleistung (Prozessoren hinzufügen) auf den Computern erhöhen, auf denen diese Workloads ausgeführt werden.
Problembehandlung bei anderen fehlgeschlagenen Failoverereignissen
Um die Integrität des neuen primären Replikats während des Failovers zu überwachen, müssen Sie die AlwaysOn-Integritätsüberwachung lokal mit der SQL Server-Instanz verbinden, die zur primären Rolle wechselt.
Zusätzlich zu den häufigeren Gründen, die in diesem Artikel erläutert werden, gibt es viele andere Gründe, warum dieser Verbindungsversuch fehlschlägt. Um einen fehlgeschlagenen Failoverversuch weiter zu untersuchen, überprüfen Sie das Clusterprotokoll auf dem Failoverpartner (das Replikat, zu dem Sie nicht übergehen konnten):
Verwenden Sie Windows PowerShell, um das Windows-Clusterprotokoll auf dem Clusterknoten zu generieren. Führen Sie dazu das folgende Cmdlet in einem PowerShell-Fenster mit erhöhten Rechten auf der Instanz von SQL Server aus, die das sekundäre Replikat hostet, das nicht in die primäre Rolle übergeht. Für die letzten 60 Minuten der Aktivität wird ein Clusterprotokoll generiert.
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60Um das Windows Cluster-Protokoll zu überprüfen, öffnen Sie die Cluster.log Datei im Editor.
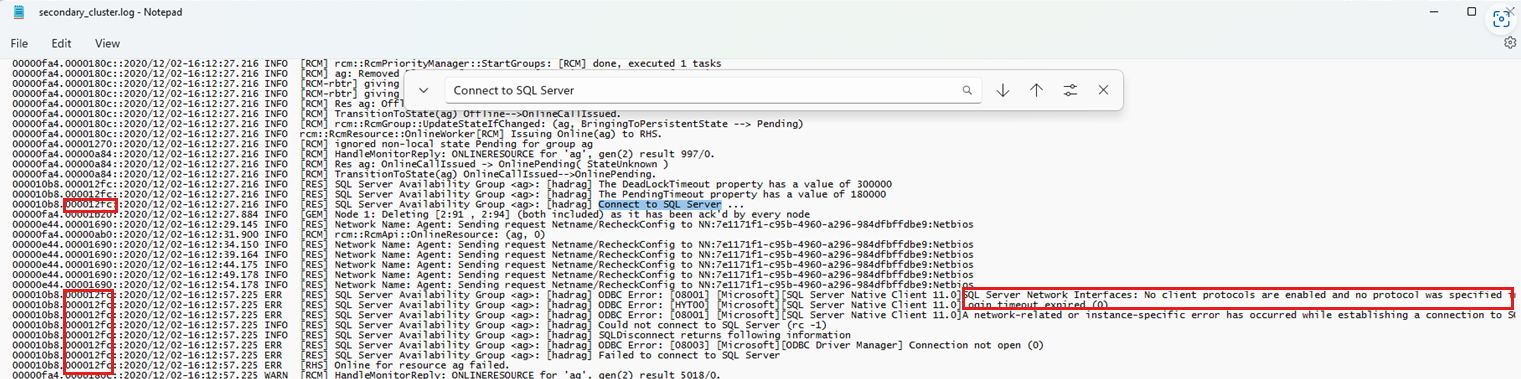
Suchen Sie nach der Zeichenfolge "Mit SQL Server verbinden", die während des nicht erfolgreichen Failoverereignisses fällt.
Überprüfen Sie die nachfolgenden Anmeldemeldungen mithilfe der Thread-ID (siehe folgenden Screenshot), um die Ereignisse zu korrelieren, die sich auf das Anmeldeereignis beziehen. Das folgende Beispiel zeigt eine Suche nach "Herstellen einer Verbindung mit SQL Server". Außerdem wird die Verwendung der Thread-ID (links) angezeigt, um die andere Diagnose zu finden, die beschreibt, warum der Verbindungsversuch fehlgeschlagen ist.

Die folgenden Beispiele zeigen Verbindungsfehler mit dem neuen primären Replikat.
Beispielsatz 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
Lösung
Starten Sie SQL Server-Konfigurations-Manager, und stellen Sie dann sicher, dass der freigegebene Speicher oder TCP/IP unter Clientprotokolle für die SQL Native Client-Konfiguration aktiviert ist.
Beispielsatz 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
Lösung
Starten Sie SQL Server-Konfigurations-Manager, und stellen Sie dann sicher, dass der freigegebene Speicher oder TCP/IP unter Clientprotokolle für die SQL Native Client-Konfiguration aktiviert ist.
Beispielsatz 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
Lösung
Überprüfen Sie den Fall 2: Unzureichende NT Authority\SYSTEM-Kontoberechtigungen.