Erkunden der Lösungsarchitektur
Sehen wir uns die Architektur an, die Sie für den Machine Learning Operations-Workflow (MLOps) ausgewählt haben, um nachzuvollziehen, wo und wann der Code überprüft werden sollte.
Hinweis
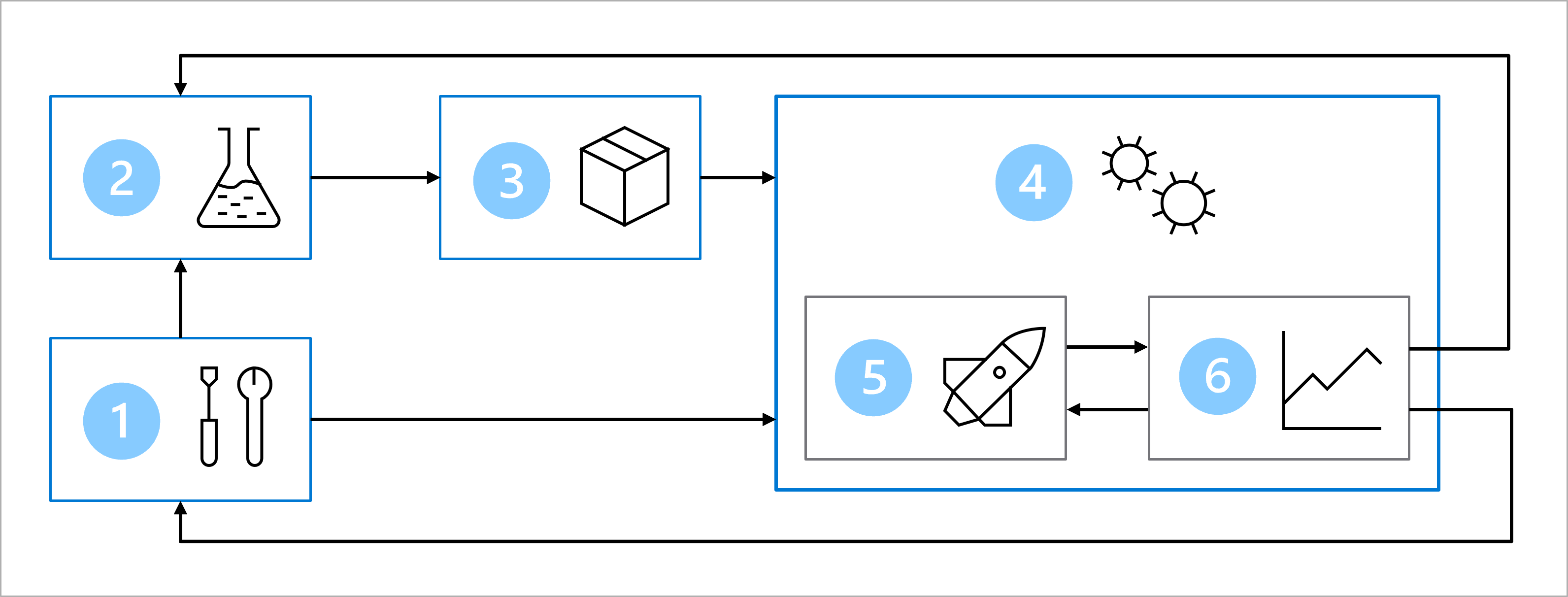
Das Diagramm zeigt eine vereinfachte Darstellung einer MLOps-Architektur. Eine detailliertere Beschreibung der Architektur finden Sie in den Anwendungsfällen im Solution Accelerator für MLOps (v2).
Das Hauptziel der MLOps-Architektur besteht in der Erstellung einer stabilen und reproduzierbaren Lösung. Zu diesem Zweck umfasst die Architektur folgende Elemente:
- Setup: Erstellen aller erforderlichen Azure-Ressourcen für die Lösung.
- Modellentwicklung (innere Schleife): Untersuchen und Verarbeiten der Daten zum Trainieren und Auswerten des Modells.
- Continuous Integration: Packen und Registrieren des Modells.
- Modellbereitstellung (äußere Schleife): Bereitstellen des Modells.
- Continuous Deployment: Testen des Modells und Höherstufen in die Produktionsumgebung.
- Überwachung: Überwachen der Modell- und Endpunktleistung
Sie benötigen Continuous Integration, um ein Modell aus der Entwicklungsphase in die Bereitstellungsphase zu überführen. Während des Continuous Integration-Prozesses packen und registrieren Sie das Modell. Jedoch müssen Sie vor dem Packen eines Modells den Code überprüfen, der zum Trainieren des Modells verwendet wird.
Gemeinsam mit dem Data Science-Team haben Sie entschieden, die trunk-basierte Entwicklung anzuwenden. Branches schützen dabei nicht nur den Produktionscode, sondern ermöglichen es auch, alle vorgeschlagenen Änderungen zu überprüfen, bevor Sie sie mit dem Produktionscode zusammenführen.
Sehen wir uns den Workflow eines bzw. einer Data Scientist an:
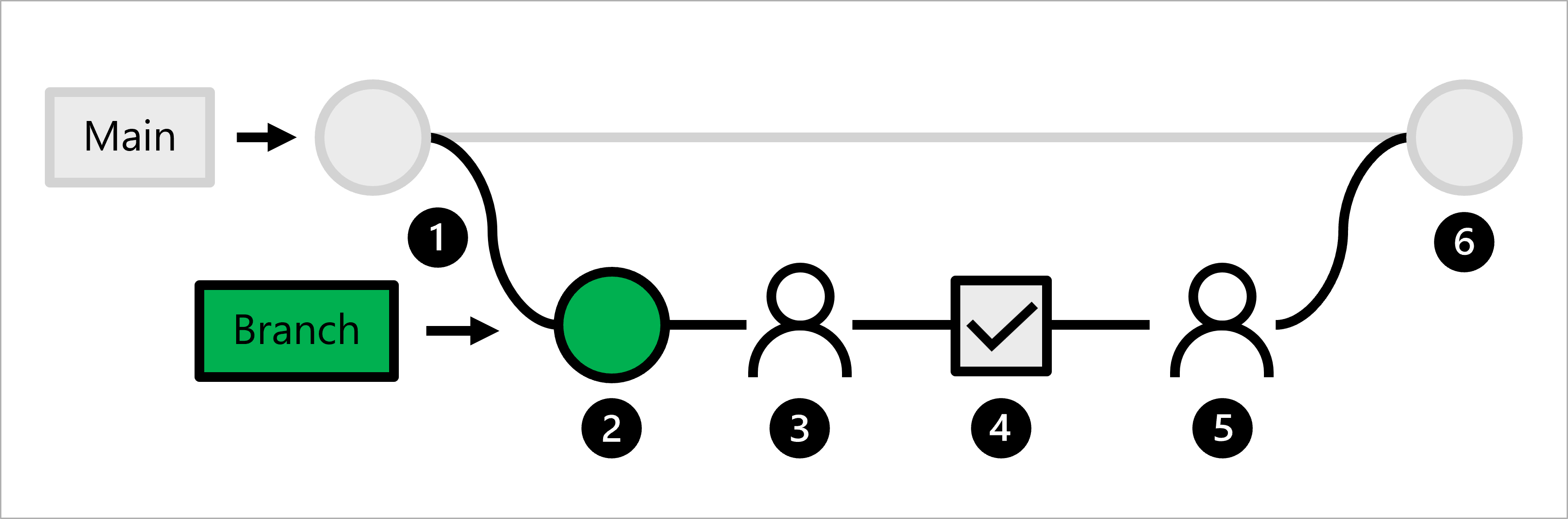
- Der Produktionscode wird im Mainbranch gehostet.
- Ein*e Data Scientist erstellt einen Featurebranch für die Modellentwicklung.
- Diese*r Data Scientist erstellt einen Pull Request, um das Pushen von Änderungen an den Mainbranch vorzuschlagen.
- Wenn ein Pull Request erstellt wird, wird ein GitHub Actions-Workflow ausgelöst, um den Code zu überprüfen.
- Wenn der Code das Linting und den Unittest durchlaufen hat, muss der*die verantwortliche Data Scientist die vorgeschlagenen Änderungen genehmigen.
- Nachdem der*die verantwortliche Data Scientist die Änderungen genehmigt hat, wird der Pull Request zusammengeführt, und der Mainbranch wird entsprechend aktualisiert.
Als Fachkraft für maschinelles Lernen müssen Sie einen GitHub Actions-Workflow erstellen, der den Code überprüft, indem ein Linter und Komponententests ausgeführt werden, wenn ein Pull Request erstellt wird.