Wählen Sie das entsprechende Computeziel aus
In Azure Machine Learning sind Computeziele physische oder virtuelle Computer (VMs), auf denen Experimente ausgeführt werden.
Grundlegendes zu den verfügbaren Computetypen
Azure Machine Learning unterstützt verschiedene Computetypen für Experimente, Training und Bereitstellung. Wenn Sie über mehrere Computetypen verfügen, können Sie den am besten geeigneten Computezieltyp für Ihre Anforderungen auswählen.
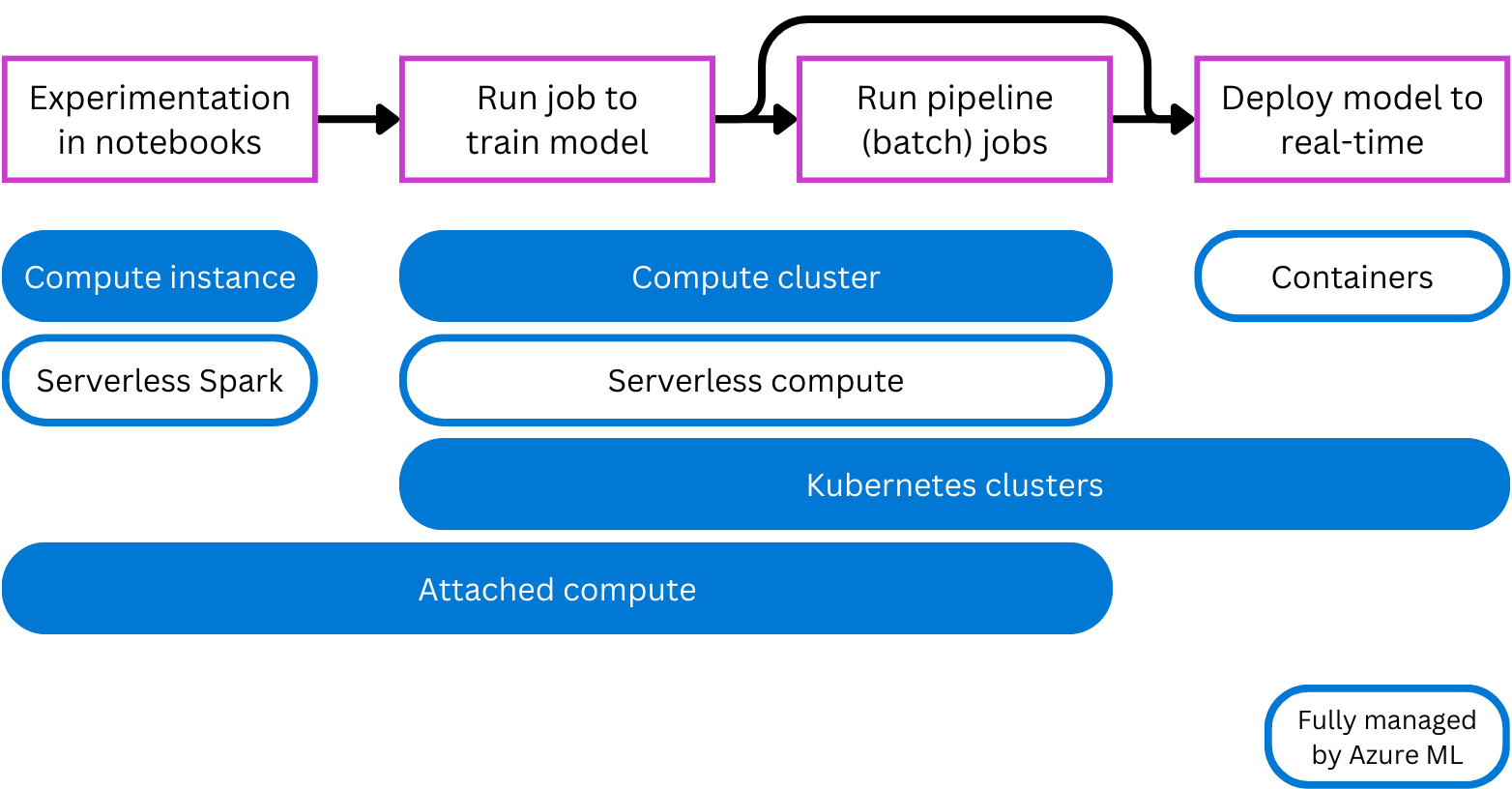
- Compute-Instanz: Verhält sich ähnlich wie ein virtueller Computer und wird hauptsächlich zum Ausführen von Notebooks verwendet. Eignet sich ideal für Experimente.
- Computecluster: Cluster virtueller Computer mit mehreren Knoten, die automatisch hoch- oder herunterskaliert werden, um den Bedarf zu decken. Eine kostengünstige Möglichkeit zum Ausführen von Skripts, die große Datenmengen verarbeiten müssen. Mit Clustern können Sie auch die parallele Verarbeitung verwenden, um den Workload zu verteilen und die Zeit zu verkürzen, die zum Ausführen eines Skripts benötigt wird.
- Kubernetes-Cluster: Cluster, der auf Kubernetes-Technologie basiert und Ihnen mehr Kontrolle darüber bietet, wie die Compute-Instanz konfiguriert und verwaltet wird. Sie können Ihren selbstverwalteten Azure Kubernetes-Cluster (AKS) für Cloudcompute oder einen Arc Kubernetes-Cluster für lokale Workloads anfügen.
- Angefügte Computeressourcen: Ermöglicht Ihnen das Anfügen vorhandener Computeressourcen wie Azure-VMs oder Azure Databricks-Cluster an Ihren Arbeitsbereich.
- Serverloses Computing: Dies ist eine vollständig verwaltete, bedarfsgesteuerte Computinglösung, die Sie für Trainingsaufträge verwenden können.
Hinweis
Azure Machine Learning bietet Ihnen die Möglichkeit, Ihre eigene Computeressource zu erstellen und zu verwalten oder Computeressourcen zu verwenden, die vollständig von Azure Machine Learning verwaltet werden.
Wann sollte welcher Computetyp verwendet werden?
Im Allgemeinen gibt es einige bewährte Methoden, die Sie bei der Arbeit mit Computezielen befolgen können. Um zu verstehen, wie Sie den geeigneten Computetyp auswählen, werden mehrere Beispiele angeführt. Denken Sie daran, dass der verwendete Computetyp immer von Ihrer spezifischen Situation abhängt.
Auswählen eines Computeziels für Experimente
Stellen Sie sich vor, Sie sind wissenschaftliche Fachkraft für Daten und sollen ein neues Machine Learning-Modell entwickeln. Wahrscheinlich verfügen Sie über eine kleine Teilmenge der Trainingsdaten, mit denen Sie experimentieren können.
Während des Experimentierens und der Entwicklung ziehen Sie es vor, in einem Jupyter Notebook zu arbeiten. Ein Notebook profitiert am meisten von einem Compute, das kontinuierlich ausgeführt wird.
Viele wissenschaftliche Fachkräfte für Daten sind mit der Ausführung von Notebooks auf ihrem lokalen Gerät vertraut. Eine cloudbasierte Alternative, die von Azure Machine Learning verwaltet wird, ist eine Compute-Instanz. Alternativ können Sie auch ein serverloses Spark Computing verwenden, um Spark-Code in Notebooks auszuführen, wenn Sie die verteilte Computeleistung von Spark nutzen möchten.
Auswählen eines Computeziels für die Produktion
Nach dem Experimentieren können Sie Ihre Modelle trainieren, indem Sie Python-Skripts ausführen, um sich auf die Produktion vorzubereiten. Skripts lassen sich einfacher automatisieren und es lässt sich leichter planen, wann Sie Ihr Modell im Laufe der Zeit kontinuierlich erneut trainieren möchten. Skripts können als (Pipeline-)Aufträge ausgeführt werden.
Beim Wechsel in die Produktion soll das Computeziel bereit sein, große Datenmengen zu verarbeiten. Je mehr Daten Sie verwenden, umso besser wird das Machine Learning-Modell wahrscheinlich sein.
Wenn Sie Modelle mit Skripts trainieren, benötigen Sie ein bedarfsgesteuertes Computeziel. Ein Computecluster wird automatisch hochskaliert, wenn die Skripts ausgeführt werden müssen, und herunterskaliert, wenn die Ausführung des Skripts abgeschlossen ist. Sollten Sie sich eine Alternative wünschen, die Sie nicht erstellen und verwalten müssen, können Sie das serverlose Computing von Azure Machine Learning verwenden.
Auswählen eines Computeziels für die Bereitstellung
Die Art von Compute, die Sie benötigen, wenn Sie Ihr Modell zum Generieren von Vorhersagen verwenden, hängt davon ab, ob Sie Batch- oder Echtzeitvorhersagen brauchen.
Für Batchvorhersagen können Sie einen Pipelineauftrag in Azure Machine Learning ausführen. Computeziele wie Computecluster und serverloses Computing von Azure Machine Learning eignen sich ideal für Pipelineaufträge, da sie bedarfsgesteuert und skalierbar sind.
Wenn Sie Echtzeitvorhersagen möchten, benötigen Sie eine Art von Compute, die kontinuierlich ausgeführt wird. Echtzeitbereitstellungen profitieren daher von einem einfacheren (und damit kosteneffizienteren) Compute. Container eignen sich ideal für Echtzeitbereitstellungen. Wenn Sie Ihr Modell auf einem verwalteten Onlineendpunkt bereitstellen, erstellt und verwaltet Azure Machine Learning Container, mit denen Sie Ihr Modell ausführen können. Alternativ können Sie Kubernetes-Cluster zur Vewaltung des erforderlichen Computes anfügen, um Echtzeitvorhersagen zu generieren.