Grundlegendes zu Dataflows Gen2 in Microsoft Fabric
In Microsoft Fabric können Sie einen Dataflow Gen2 in der Data Factory-Workload, im Power BI-Arbeitsbereich oder direkt im Lakehouse erstellen. Da der Schwerpunkt unseres Szenarios auf der Datenerfassung liegt, sehen wir uns die Data Factory-Workload an. Dataflows Gen2 verwenden Power Query Online, um Transformationen zu visualisieren. Übersicht über die Benutzeroberfläche:
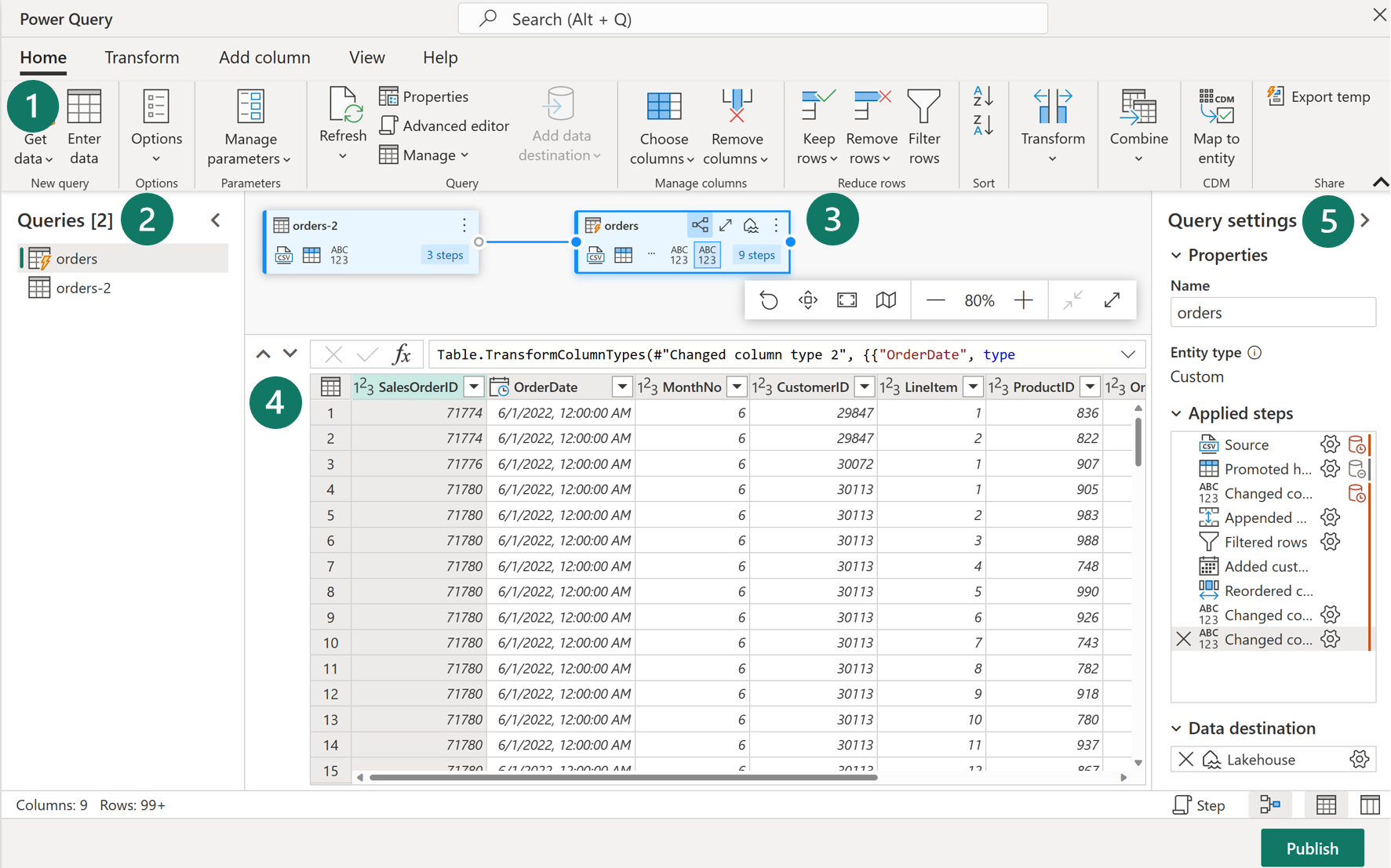
1. Power Query-Menüband
Dataflows Gen2 unterstützen viele verschiedene Datenquellenconnectors. Zu den gängigen Quellen gehören relationale Datenbanken (lokal und in der Cloud), Excel oder Flatfiles, SharePoint, SalesForce, Spark und Fabric-Lakehouses. Es gibt zahlreiche mögliche Datentransformationen, unter anderem:
- Zeilen filtern und sortieren
- Pivotieren und entpivotieren
- Abfragen zusammenführen und anfügen
- Teilen und bedingtes Teilen
- Werte ersetzen und Duplikate entfernen
- Spalten hinzufügen, umbenennen, neu anordnen oder löschen
- Rechner für Rang und Prozentwerte
- Auswählen von „Oberes N“ und „Unteres N“
Sie können in diesem Menüband außerdem Datenquellenverbindungen erstellen und verwalten, Parameter verwalten sowie das Standarddatenziel konfigurieren.
2. Bereich „Abfragen“
Im Bereich „Abfragen“ werden die verschiedenen Datenquellen angezeigt, die jetzt als Abfragen bezeichnet werden. Diese Abfragen werden als Tabellen bezeichnet, wenn sie in Ihren Datenspeicher geladen werden. Sie können eine Abfrage duplizieren oder referenzieren, wenn Sie mehrere Kopien derselben Daten benötigen, z. B. beim Erstellen eines Sternschemas und beim Aufteilen von Daten in separate kleinere Tabellen. Sie können auch das Laden einer Abfrage deaktivieren, falls Sie nur einen einmaligen Import benötigen.
3. Diagrammansicht
In der Diagrammansicht wird visuell dargestellt, wie die Datenquellen verbunden sind und welche verschiedenen Transformationen angewendet werden. Ihr Dataflow stellt beispielsweise eine Verbindung mit einer Datenquelle her, dupliziert die Abfrage, entfernt Spalten aus der Quellabfrage und entpivotiert dann die doppelte Abfrage. Jede Abfrage wird als Form mit allen angewendeten Transformationen dargestellt und durch eine Zeile für die doppelte Abfrage verbunden. Sie können diese Ansicht aktivieren oder deaktivieren.
4. Bereich „Datenvorschau“
Im Bereich „Datenvorschau“ wird nur eine Teilmenge der Daten angezeigt, damit Sie sehen können, welche Transformationen Sie vornehmen sollten und wie diese sich auf die Daten auswirken. Sie können im Vorschaubereich auch sehen, was geschieht, wenn sie Spalten ziehen und ablegen, um die Anordnung zu ändern, oder mit der rechten Maustaste auf Spalten klicken, um zu filtern oder Änderungen vorzunehmen. In der Datenvorschau werden alle Ihre Transformationen für die ausgewählte Abfrage angezeigt.
5. Bereich „Abfrageeinstellungen“
Der Bereich „Abfrageeinstellungen“ enthält die Angewendeten Schritte. Jede Transformation wird als Schritt dargestellt. Manche davon werden automatisch angewendet, wenn Sie eine Datenquelle verbinden. Abhängig von der Komplexität der Transformationen sind möglicherweise mehrere angewendete Schritte für jede Abfrage vorhanden. Die meisten Schritte verfügen über ein Zahnradsymbol, mit dem Sie den Schritt ändern können. Andernfalls müssen Sie die Transformation löschen und wiederholen.
Jeder Schritt verfügt außerdem über ein Kontextmenü, das Sie mit einem Rechtsklick öffnen können. Mit seiner Hilfe können Sie die Schritte umbenennen, neu anordnen oder löschen. Sie können außerdem die Datenquellenabfrage anzeigen, wenn Sie eine Verbindung mit einer Datenquelle herstellen, die das Query Folding unterstützt.
Diese visuelle Benutzeroberfläche ist zwar praktisch, aber Sie können den M-Code auch über den erweiterten Editor anzeigen.
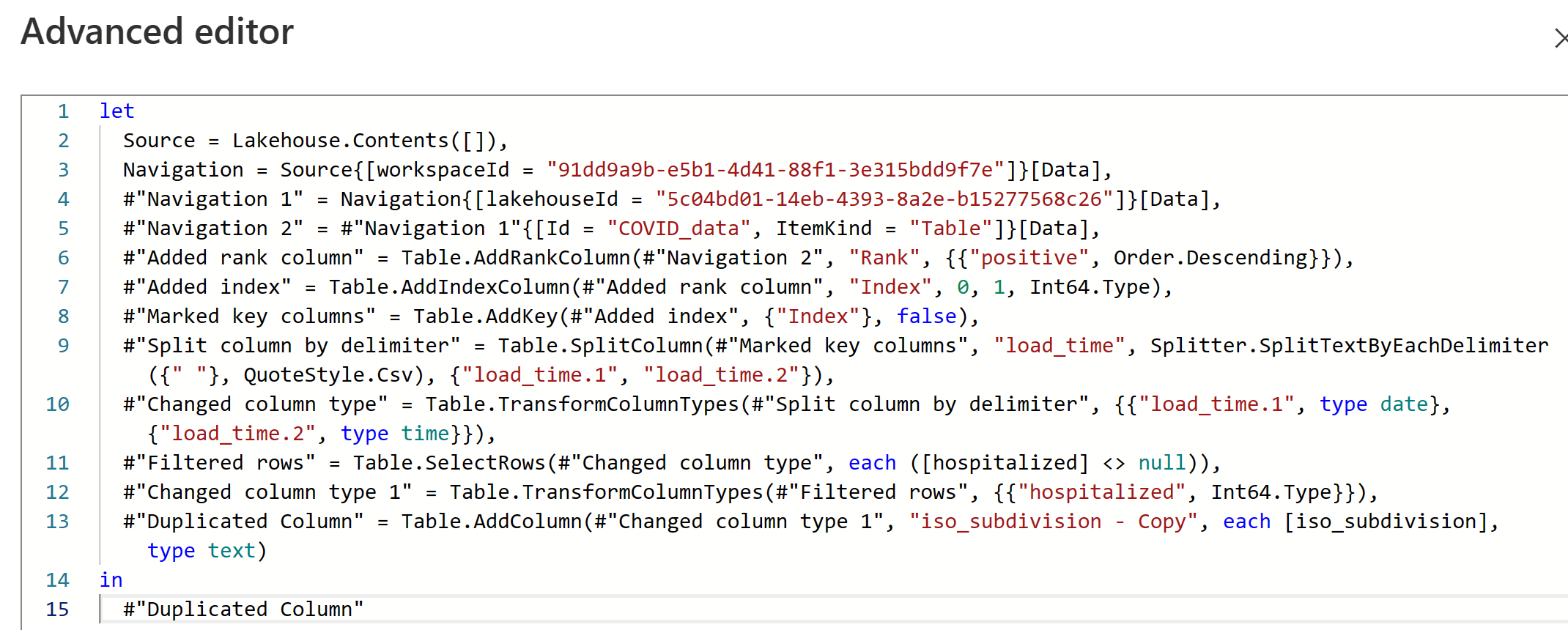
Im Bereich „Abfrageeinstellungen“ wird die Datenziel angezeigt, um Ihre Daten an einem der folgenden Speicherorte in Ihrer Fabric-Umgebung zu speichern:
- Lakehouse
- Warehouse
- SQL-Datenbank
Sie können Ihren Dataflow auch in die Azure SQL-Datenbank, in Azure Data Explorer oder in Azure Synapse Analytics laden.
Dataflows Gen2 bietet eine Low-to-No-Code-Lösung zum Erfassen, Transformieren und Laden von Daten in Ihre Fabric-Datenspeicher. Power BI-Entwickler sind mit dieser Lösung vertraut und können rasch damit beginnen, Upstream-Transformationen durchzuführen, um die Leistung für ihre Berichte zu verbessern.
Hinweis
Weitere Informationen finden Sie in der Power Query-Dokumentation zur Optimierung Ihrer Dataflows.