Verwenden von Spark in Notebooks
Sie können viele verschiedene Arten von Anwendungen unter Spark ausführen, darunter Code in Python- oder Scala-Skripts, Java-Code, der als Java-Archiv (JAR) kompiliert wurde, und andere. Spark wird in der Regel für zwei Arten von Workloads verwendet:
- Batch- oder Streamverarbeitungsaufträge zur Erfassung, Bereinigung und Transformation von Daten, die oft als Teil einer automatisierten Pipeline ausgeführt werden.
- Interaktive Analysesitzungen zum Erkunden, Analysieren und Visualisieren von Daten.
Ausführen von Spark-Code in Notebooks
Azure Databricks enthält eine integrierte Notebookschnittstelle für die Arbeit mit Spark. Notebooks bieten eine intuitive Möglichkeit, Code mit Markdown-Hinweisen zu kombinieren, die üblicherweise von wissenschaftlichen Fachkräften für Daten und Datenanalysten verwendet werden. Aussehen und Handhabung der in Azure Databricks integrierten Notebooks ähneln denen von Jupyter-Notebooks - einer beliebten Open Source-Notebookplattform.
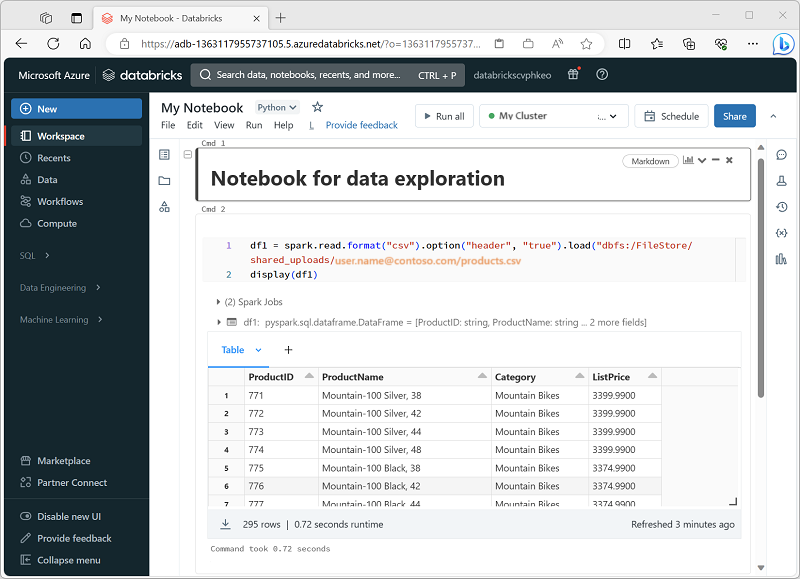
Notebooks bestehen aus einer oder mehreren Zellen, die jeweils entweder Code oder Markdown enthalten. Codezellen in Notebooks verfügen über einige Features, die Ihnen helfen können, produktiver zu sein. Beispiel:
- Syntaxhervorhebung und Fehlerunterstützung
- Automatische Vervollständigung von Code
- Interaktive Datenvisualisierungen
- Möglichkeit zum Exportieren von Ergebnissen
Tipp
Weitere Informationen zum Arbeiten mit Notebooks in Azure Databricks finden Sie in der Azure Databricks-Dokumentation im Artikel Notebooks.