Erstellen eines Spark-Clusters
Sie können mindestens einen Cluster in Ihrem Azure Databricks-Arbeitsbereich erstellen, indem Sie das Azure Databricks-Portal verwenden.
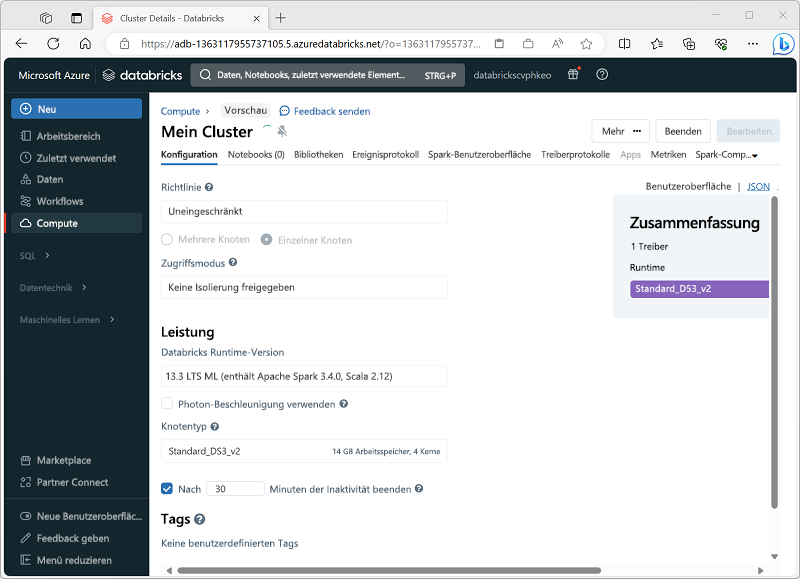
Beim Erstellen des Clusters können Sie Konfigurationseinstellungen angeben, darunter:
- Einen Namen für den Cluster.
- Einen der folgenden Clustermodi:
- Standard: Geeignet für Einzelbenutzerworkloads, die mehrere Workerknoten erfordern.
- Hohe Parallelität: Geeignet für Workloads, in denen mehrere Benutzer den Cluster gleichzeitig verwenden.
- Einzelner Knoten: Geeignet für kleine Workloads oder Tests, wobei nur ein einzelner Workerknoten erforderlich ist.
- Die Version der Databricks Runtime, die im Cluster verwendet werden soll. Sie bestimmt die Version von Spark und der einzelnen Komponenten wie Python, Scala und andere, die installiert werden.
- Der Typ der VM, die für die Workerknoten im Cluster verwendet wird.
- Die Mindest- und maximale Anzahl von Workerknoten im Cluster.
- Der für den Treiberknoten im Cluster verwendete VM-Typ.
- Ob der Cluster die automatische Skalierung unterstützt, um die Größe des Clusters dynamisch zu ändern.
- Wie lange der Cluster im Leerlauf bleiben kann, bevor er automatisch heruntergefahren wird.
Verwaltung von Clusterressourcen durch Azure
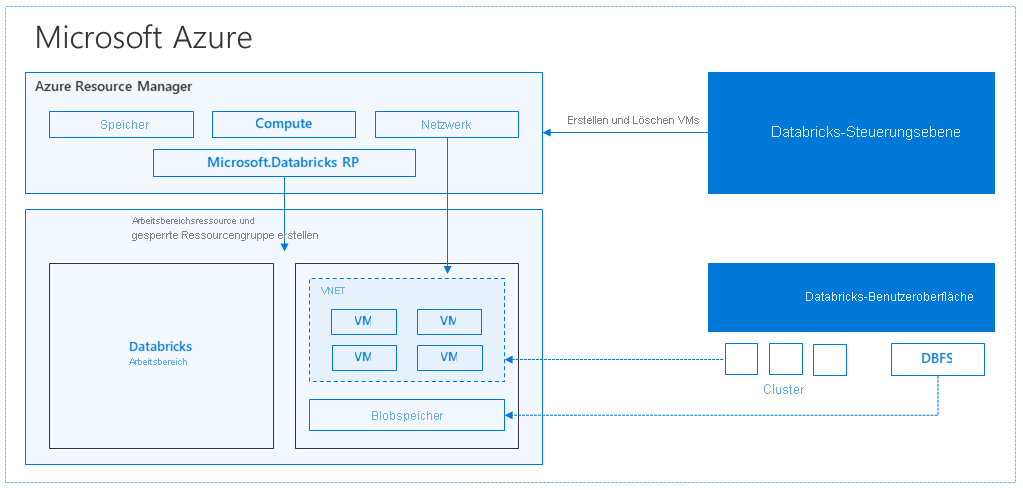
Wenn Sie einen Azure Databricks-Arbeitsbereich erstellen, wird eine Databricks-Appliance als Azure-Ressource in Ihrem Abonnement bereitgestellt. Wenn Sie einen Cluster im Arbeitsbereich erstellen, geben Sie die Typen und Größen der VMs an, die sowohl für die Treiber- als auch für Workerknoten verwendet werden sollen, sowie einige weitere Konfigurationsoptionen, aber Azure Databricks verwaltet alle anderen Aspekte des Clusters.
Die Databricks-Appliance wird in Azure als eine verwaltete Ressourcengruppe in Ihrem Abonnement bereitgestellt. Diese Ressourcengruppe enthält die Treiber- und Worker-VMs für Ihre Cluster sowie weitere erforderliche Ressourcen, z. B. ein virtuelles Netzwerk, eine Sicherheitsgruppe und ein Speicherkonto. Alle Metadaten für Ihren Cluster (beispielsweise geplante Aufträge) werden aus Gründen der Fehlertoleranz in einer Azure-Datenbank mit Georeplikation gespeichert.
Intern wird Azure Kubernetes Service (AKS) verwendet, um die Azure Databricks-Steuerungsebene sowie die Datenebenen über Container auszuführen, die auf der neuesten Generation von Azure-Hardware (Dv3-VMs) mit NvMe-SSDs ausgeführt werden, die eine Latenzzeit von 100 RU/s für Azure-Hochleistungs-VMs mit beschleunigtem Netzwerkbetrieb bieten. Azure Databricks nutzt diese Features von Azure, um die Leistung von Spark weiter zu optimieren. Sobald die Dienste in der verwalteten Ressourcengruppe bereit sind, können Sie den Databricks-Cluster über die Azure Databricks-Benutzeroberfläche und über Features wie automatische Skalierung und die automatische Beendigung verwalten.
Hinweis
Sie haben auch die Möglichkeit, Ihren Cluster an einen Pool von Knoten im Leerlauf anzufügen, um die Startzeit des Clusters zu verringern. Weitere Informationen finden Sie unter Pools in der Dokumentation zu Azure Databricks.