Beschreiben von Replikation und logischer Decodierung
Mit dem Parameter wal_level können Sie festlegen, wie viele Informationen in das Protokoll geschrieben werden sollen. Es gibt zwei Optionen: LOGICAL oder REPLICA. REPLICA ist die Standardeinstellung. Dieser Parameter wird beim Start des Servers festgelegt.
Hochverfügbarkeit
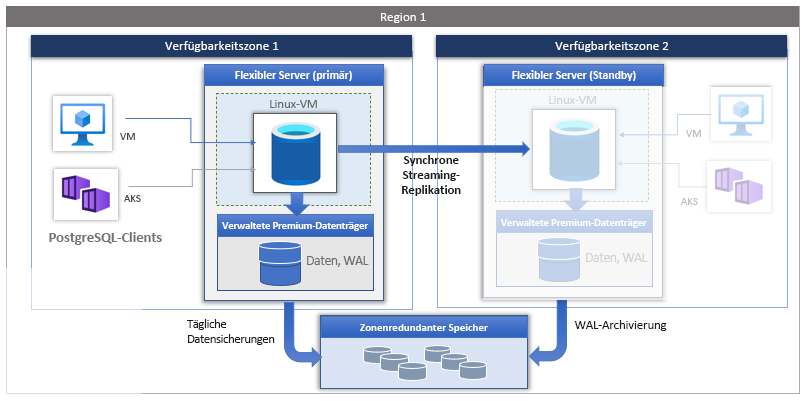
Hochverfügbarkeit ist ein Azure Database for PostgreSQL-Dienstmerkmal, das einen Standbyserver bereitstellt, der bei einem Ausfall Ihres Liveservers einspringt. Hochverfügbarkeit in Azure Database for PostgreSQL – Flexibler Server basiert auf Replikation, um den Standbyserver automatisch mit Datenänderungen zu aktualisieren.
Wenn Sie Hochverfügbarkeit für Azure Database for PostgreSQL – Flexibler Server konfigurieren, wird der primäre Server in einer Verfügbarkeitszone platziert, und ein Standbyserver wird in einer anderen Verfügbarkeitszone erstellt. Daten werden vom primären Server auf den Standbyserver mithilfe der PostgreSQL-Streamingreplikation im synchronen Modus repliziert.
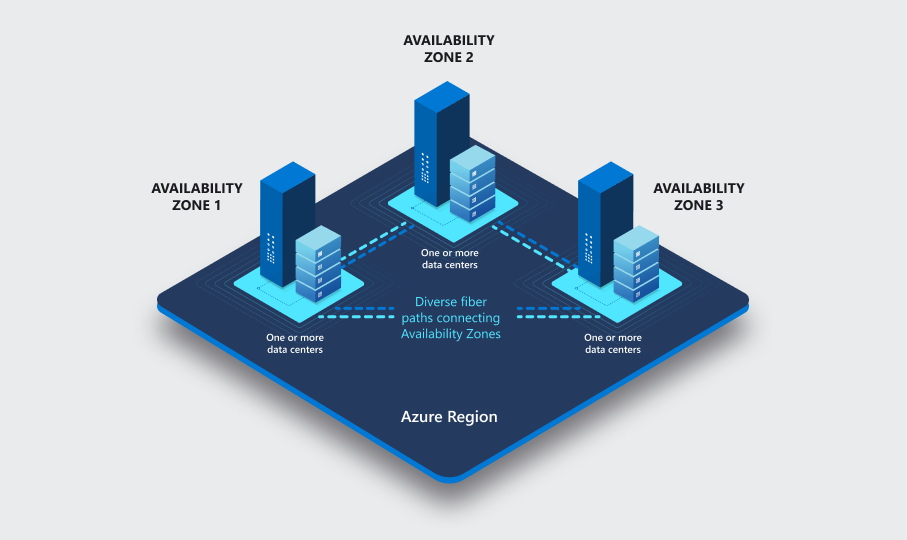
Zu jeder Verfügbarkeitszone gehören ein oder mehrere Rechenzentren. Verfügbarkeitszonen verfügen über eigene Stromversorgungen, Kühlsysteme, Netzwerkinfrastrukturen usw., sodass sie voneinander unabhängig sind. Drei Kopien von Datendateien und WAL-Protokolldateien (Write-Ahead Log) werden in lokal redundantem Speicher innerhalb jeder Verfügbarkeitszone gespeichert, wodurch eine physische Isolation zwischen Primär- und Standbyservern gewährleistet ist. Wenn eine Verfügbarkeitszone fehlschlägt, funktionieren die beiden anderen wahrscheinlich weiterhin. Verfügbarkeitszonen innerhalb einer Region sind durch schnelle Glasfasernetze mit einer Roundtriplatenz von weniger als 2 Millisekunden verbunden.
Hinweis
Nicht alle Regionen verfügen über Verfügbarkeitszonen.
Für Hochverfügbarkeit werden Daten während der gesamten Nutzungsdauer der Datenbank dupliziert, sodass eine aktuelle Kopie des Originals vorliegt. Bei einem Absturz kann das Replikat anstelle des Originals verwendet werden. Für die Replikation gibt es einen primären Server und einen Standbyserver. Der primäre Server sendet WAL-Protokolldateien an den Standbyserver, der die WAL-Protokolldateien empfängt.
Der Standbyserver meldet Informationen wie das letzte schreibgeschützte Protokoll, das er geschrieben hat, und die letzte Position, die auf den Datenträger geleert wurde usw. zurück an den primären Server. Um die Mindesthäufigkeit für den WAL-Empfänger zum Senden eines Berichts zu definieren, legen Sie den Parameter wal_receiver_status_interval fest. Der max_replication_slots-Parameter definiert die maximale Anzahl von Replikationsslots, die der Server unterstützen kann. Wenn wal_level auf REPLICA festgelegt ist, muss max_replication_slots mindestens 1 sein. Der zulässige Wertebereich liegt jedoch zwischen 0 und 262.143.
Der Parameter max_wal_senders legt die maximale Anzahl der WAL-Absenderprozesse fest.
Der primäre und der Standbyserver werden überwacht, und es werden geeignete Maßnahmen ergriffen, um Probleme zu beheben, einschließlich des Auslösens eines Failover auf den Standbyserver. Im Folgenden werden die redundanten Hochverfügbarkeitsstaten der Zone aufgelistet:
- Initialisierung wird ausgeführt: Der Prozess zum Erstellen eines neuen Standbyservers läuft.
- Replikation wird ausgeführt: Die Datenreplikation erfolgt stabil und fehlerfrei.
- Fehlerfrei: Der Standbyserver wird vom primären Server aktualisiert.
- Failover: Der primäre Datenbankserver befindet sich im Prozess des Failovers auf den Standbyserver.
- Standby wird aufgehoben: Der Standbyserver wird gerade gelöscht.
- Nicht aktiviert: Zonenredundante Hochverfügbarkeit ist nicht aktiviert.
Sie können einem vorhandenen Datenbankserver Hochverfügbarkeit hinzufügen. Wenn Sie Hochverfügbarkeit auf einem Liveserver aktivieren oder deaktivieren, führen Sie diesen Vorgang durch, wenn wenig Aktivität herrscht.
Gehen Sie im Azure-Portal so vor:
- Navigieren Sie zu Ihrem Azure Database for PostgreSQL-Server.
- Wählen Sie im Abschnitt Übersicht Ihre aktuelle Konfiguration aus. Der Abschnitt Compute + Speicher wird angezeigt.
- Aktivieren Sie unter „Hochverfügbarkeit“ das Kontrollkästchen Hochverfügbarkeit" (zonenredundant), um Hochverfügbarkeit zu aktivieren. Hochverfügbarkeit wird im Computetarif „Burstfähig“ nicht unterstützt.
Es ist wichtig zu beachten, dass Hochverfügbarkeit eine Notfallwiederherstellungsoption ist. Sie können den Standbyserver nicht für andere Zwecke verwenden, z. B. um Zugriff auf schreibgeschützte Datenbanken zu ermöglichen. Sie können jedoch die Replikation zwischen zwei Azure Database for PostgreSQL-Servern mithilfe eines Verleger- und Abonnentenmodells konfigurieren. Diese Konfiguration verwaltet zwei Server, auf denen Daten repliziert werden. Sie haben dann vollen Zugriff auf den Abonnentenserver und können die Datenbanken für beliebige Zwecke nutzen. Sie üben diese Konfiguration in der Übung am Ende dieses Moduls.
Logische Decodierung
Die logische Decodierung verwendet auch Daten, die in das Write-Ahead-Protokoll geschrieben wurden. Wie der Name schon sagt, werden die Einträge im Write-Ahead-Protokoll decodiert, um sie verständlich zu machen. Alle Änderungen durch die Befehle INSERT, UPDATE und DELETE sind für logische Decodierung verfügbar.
Logische Decodierung kann für Überprüfungen, Analysen oder aus anderen Gründen verwendet werden, wenn Sie wissen möchten, was sich wann geändert hat.
Logische Decodierung extrahiert Änderungen aus allen Tabellen der Datenbank. Sie unterscheidet sich von der Replikation dadurch, dass sie diese Änderungen nicht an andere PostgreSQL-Instanzen senden kann. Stattdessen stellt eine PostgreSQL-Erweiterung ein Ausgabe-Plug-In bereit, um die Änderungen zu streamen.
Logische Decodierung ermöglicht es, den Inhalt des Write-Ahead-Protokolls in ein leicht verständliches Format zu decodieren, das ohne Kenntnis der Datenbankstruktur interpretiert werden kann. Azure Database for PostgreSQL unterstützt die logische Decodierung mit der wal2json-Erweiterung, die auf Azure Database for Postgres-Servern installiert ist.
Es können auch andere Erweiterungen verwendet werden, wie z. B. pglogical, die eine logische Streamingreplikation ermöglicht.
Um logische Decodierung in Serverparametern zu verwenden, legen Sie Folgendes fest:
- wal_level auf LOGICAL
- max_replication_slots = 10
- max_wal_senders = 10
Nach diesen Änderungen muss der Server neu gestartet werden.
So verwenden Sie die Erweiterung pglogical im Azure-Portal
- Navigieren Sie zu Ihrem Azure Database for PostgreSQL-Server.
- Wählen Sie Serverparameter aus, und suchen Sie nach shared_preload_libraries. Wählen Sie im Dropdownfeld die Option pglogical aus.
- Suchen Sie nach azure.extensions. Wählen Sie im Dropdownfeld die Option pglogical aus.
- Starten Sie den Server neu, um die Änderung zu übernehmen.
Sie müssen auch den Administratorbenutzerberechtigungen für die Replikation erteilen:
ALTER ROLE <adminname> WITH REPLICATION;
Weitere Informationen hierzu können Sie in der Onlinedokumentation pglogical Erweiterungsdokumentation lesen.
Logische Decodierung gibt Datenänderungen als Datenstrom mit der Bezeichnung logischer Replikationsslot aus.
- Jeder Slot verfügt über ein Ausgabe-Plug-In, das Sie bestimmen können.
- Jeder Slot liefert Änderungen aus nur einer Datenbank, aber eine Datenbank kann mehrere Slots haben.
- Jede Datenänderung wird normalerweise einmal pro Slot ausgegeben.
- Wenn PostgreSQL neu gestartet wird, kann ein Slot erneut Änderungen ausgeben, die der Client verarbeiten muss.
- Slots müssen überwacht werden. Nicht genutzte Slots behalten alle WAL-Dateien für diese nicht genutzten Änderungen bei. Diese Situation kann zu einem vollen Speicher oder einem Umbruch von Transaktions-IDs führen.