Diagnostizieren von Problemen durch Überprüfen von Konfigurationen und Metriken
Das Überwachen der Leistung von Azure Load Balancer kann dazu führen, dass frühzeitig vor möglichen Ausfällen gewarnt wird. Azure Monitor stellt viele wichtige Metriken zum Untersuchen von Trends in Bezug auf die Leistung von Load Balancer bereit. Sie können auch dafür sorgen, dass Warnungen ausgelöst werden, wenn bei einem oder mehreren virtuellen Computern (VMs) Fehler bei Integritätstestanforderungen auftreten.
Im Beispielszenario überwachen Sie die Leistung des Systems mit Lastenausgleich, um sicherzustellen, dass die Leistung den Anforderungen entspricht. Wenn die Leistung abfällt und Verbindungen mit VMs fehlschlagen, führen Sie eine Problembehandlung für das System durch, um den Grund für das Problem zu bestimmen und es zu beheben. Am Ende dieser Lerneinheit werden Sie zu Folgendem in der Lage sein:
- Beschreiben der verfügbaren Metriken für das Messen des Durchsatzes und der Leistung eines Systems mit Lastenausgleich
- Verwenden der Seite „Ressourcenintegrität“ im Azure-Portal zur Überwachung der Integrität Ihres Systems
- Erklären, wie häufig in Systemen mit Lastenausgleich auftretende Probleme behoben werden
Verwenden von Azure Monitor zur Problembehandlung in Load Balancer
Mit Azure Monitor können Sie Diagnoseprotokolle und Leistungsdaten für Load Balancer erfassen und untersuchen.
Überwachen der Konnektivität
Sie können Metriken für Load Balancer im Azure-Portal über den Bereich Metriken visualisieren. Für die Problembehandlung in Bezug auf die Konnektivität sind die wichtigsten Metriken Data Path Availability (Verfügbarkeit des Datenpfads) und Health Probe Status (Status des Integritätstests).

Load Balancer testet kontinuierlich die Verfügbarkeit des Pfads von der Front-End-IP-Adresse über die Lastenausgleichsregeln und den Back-End-Pool zu den Anwendungen, die auf Ihren VMs ausgeführt werden. Diese Informationen werden als die Metrik Data Path Availability (Verfügbarkeit des Datenpfads) gespeichert. Wenn die Metrik mit der Einstellung Durchschn. angewendet wird, wird die durchschnittliche Verfügbarkeit innerhalb eines bestimmten Zeitintervalls angezeigt. Bei dieser Aggregation handelt es sich um einen Wert zwischen 0 (keine Verfügbarkeit) und 100, wobei Letzteres bedeutet, dass mindestens ein erfolgreicher Pfad von der Front-End-IP-Adresse zu einer VM im Back-End-Pool verfügbar ist.
Die Metrik Health Probe Status (Status des Integritätstests) ist ähnlich, bezieht sich aber auf den Integritätstest für die VMs statt auf den gesamten Pfad durch Load Balancer. Auch hier liefert die Durchschn.-Aggregation für diese Metrik einen Wert zwischen 0 (alle VMs sind fehlerhaft und reagieren nicht) und 100, bei dem alle VMs auf den Integritätstest reagieren.
Die folgende Abbildung zeigt ein Diagramm für die durchschnittliche Verfügbarkeit des Datenpfads und den durchschnittlichen Status des Integritätstests bei einem Lastenausgleich mit zwei VMs im Back-End-Pool. Einer der Computer reagiert nicht auf den Integritätstest. Der durchschnittliche Wert für den Status des Integritätstests schwankt um die 50-Prozent-Marke herum.
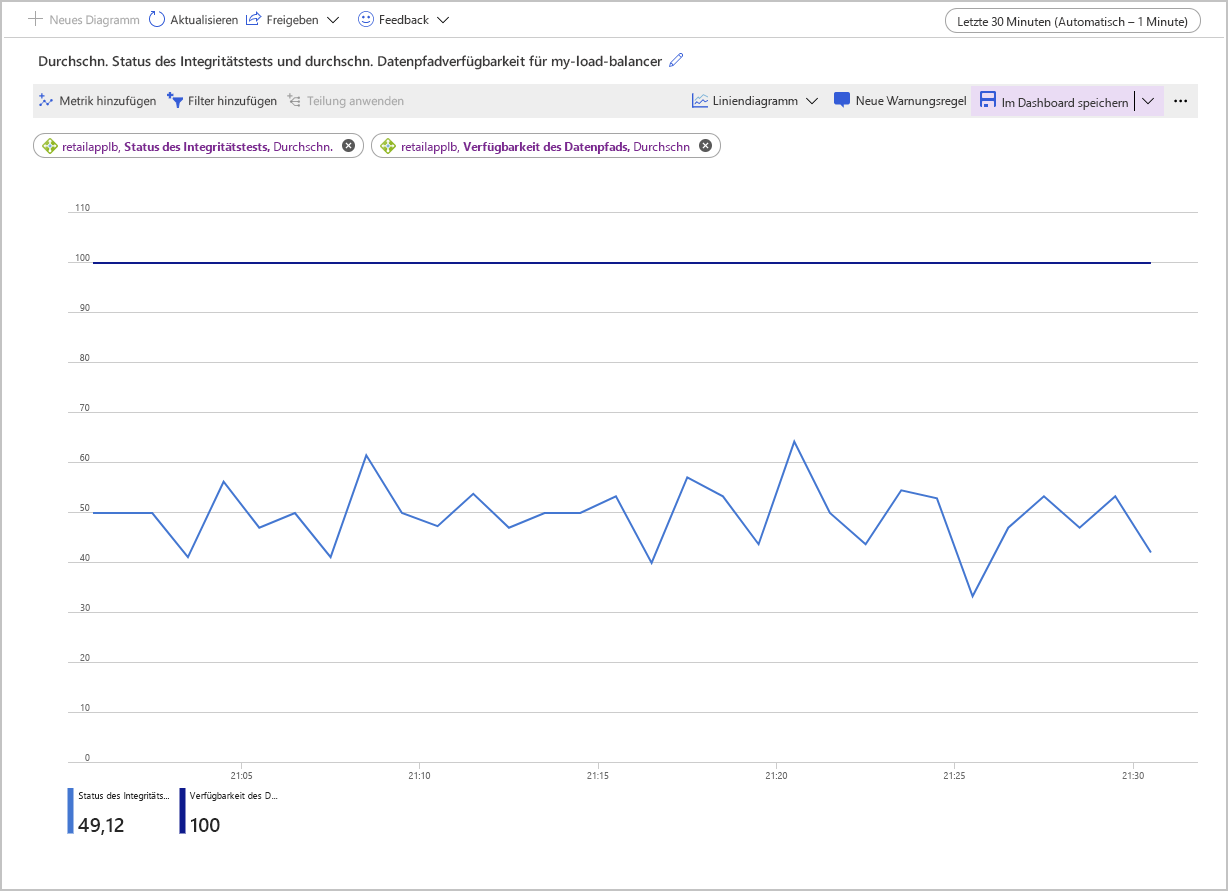
Eine weitere Möglichkeit der Untersuchung dieser Metriken ist die Verwendung der Anzahl-Aggregation. Dieser Ansatz kann andere Erkenntnissen in Bezug auf mögliche Probleme mit Ihrer Konfiguration bieten. Das folgende Beispiel zeigt die Graphen der Werte der Metriken für den Status des Integritätstests und die Verfügbarkeit des Datenpfads. Der Graph zeigt, wie viele erfolgreiche Tests im Laufe der Zeit durchgeführt wurden.
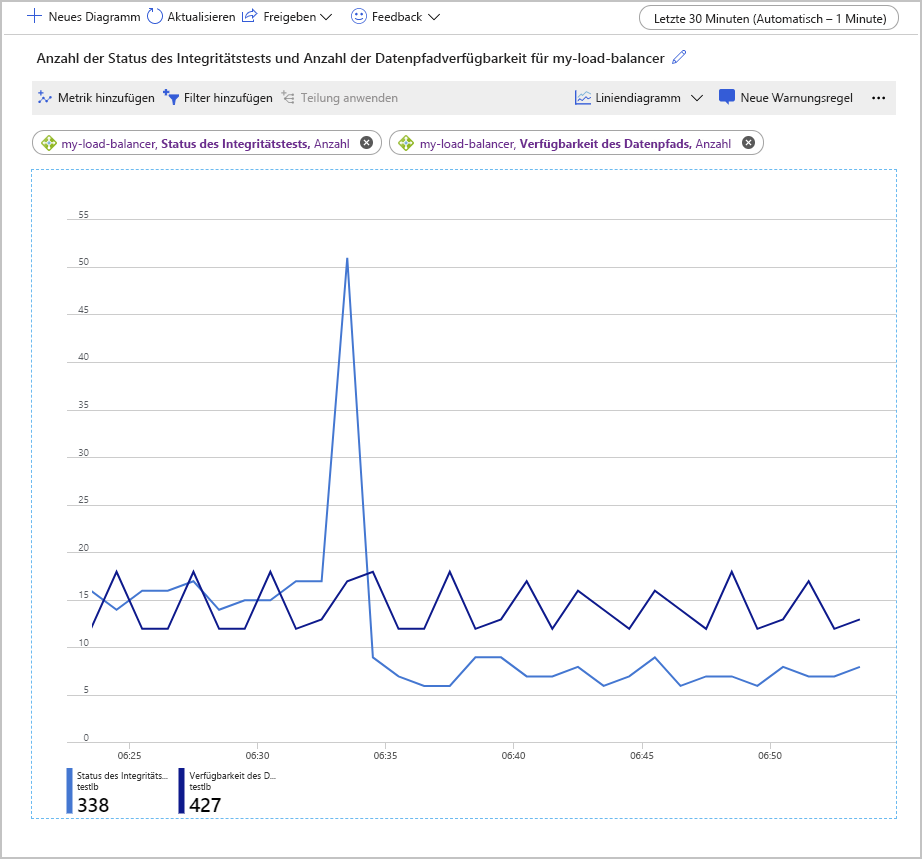
Ein interessanter Aspekt dieses Diagramms ist, dass die Anzahl der erfolgreichen Verfügbarkeitstest des Datenpfads innerhalb eines konstanten Bereichs blieb. Die Anzahl erfolgreicher Tests in Bezug auf den Status des Integritätstests ist allerdings kurz stark angestiegen und dann auf etwa die Hälfte des Werts vor diesem Anstieg gesunken.
In dem Aufbau, mit dem dieser Graph generiert wurde, enthielt der Back-End-Pool nur zwei VMs. Einer dieser Computer wurde beendet, um einen Ausfall zu simulieren. Die Metrik Data Path Availability (Verfügbarkeit des Datenpfads) zeigt, dass Clientanwendungen immer noch eine Verbindung mit der Anwendung herstellen können, die auf der verbleibenden, funktionierenden VM ausgeführt wird. Die Metrik Health Probe Status (Status des Integritätstests) zeigt allerdings, dass die Integrität des Back-End-Pools insgesamt nur bei der Hälfte des vorherigen Werts liegt.
Anzeigen der Dienstintegrität
Auf der Seite Ressourcenintegrität für Load Balancer finden Sie Berichte über den allgemeinen Zustand Ihres Systems. Auf diese Seite greifen Sie im Portal über Azure Monitor zu. Wählen Sie Service Health, Resource Health und dann Load Balancer als Ressourcentyp aus.
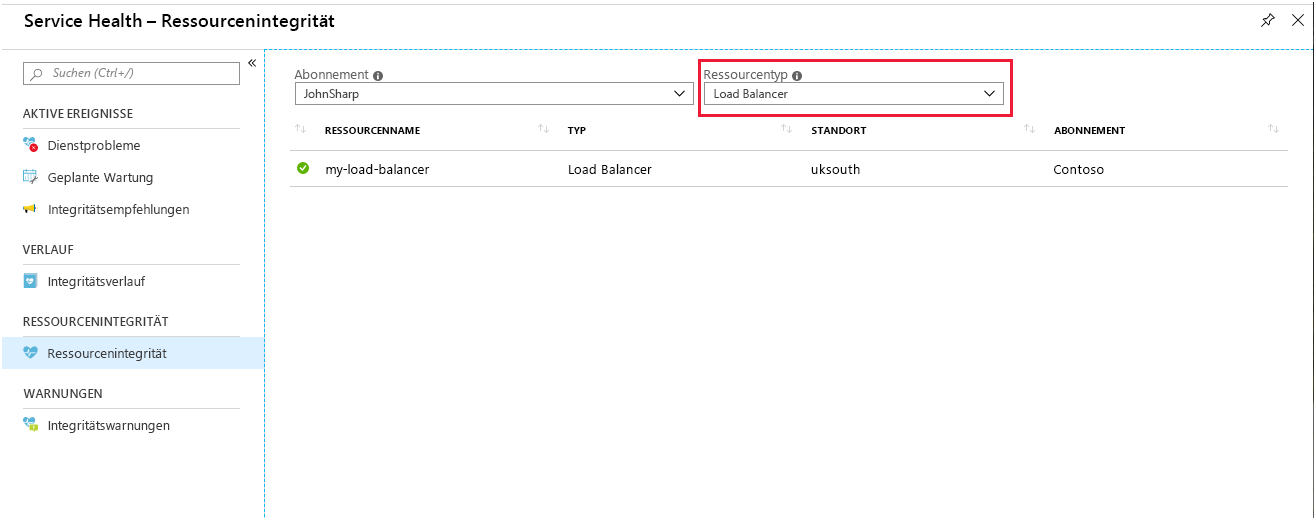
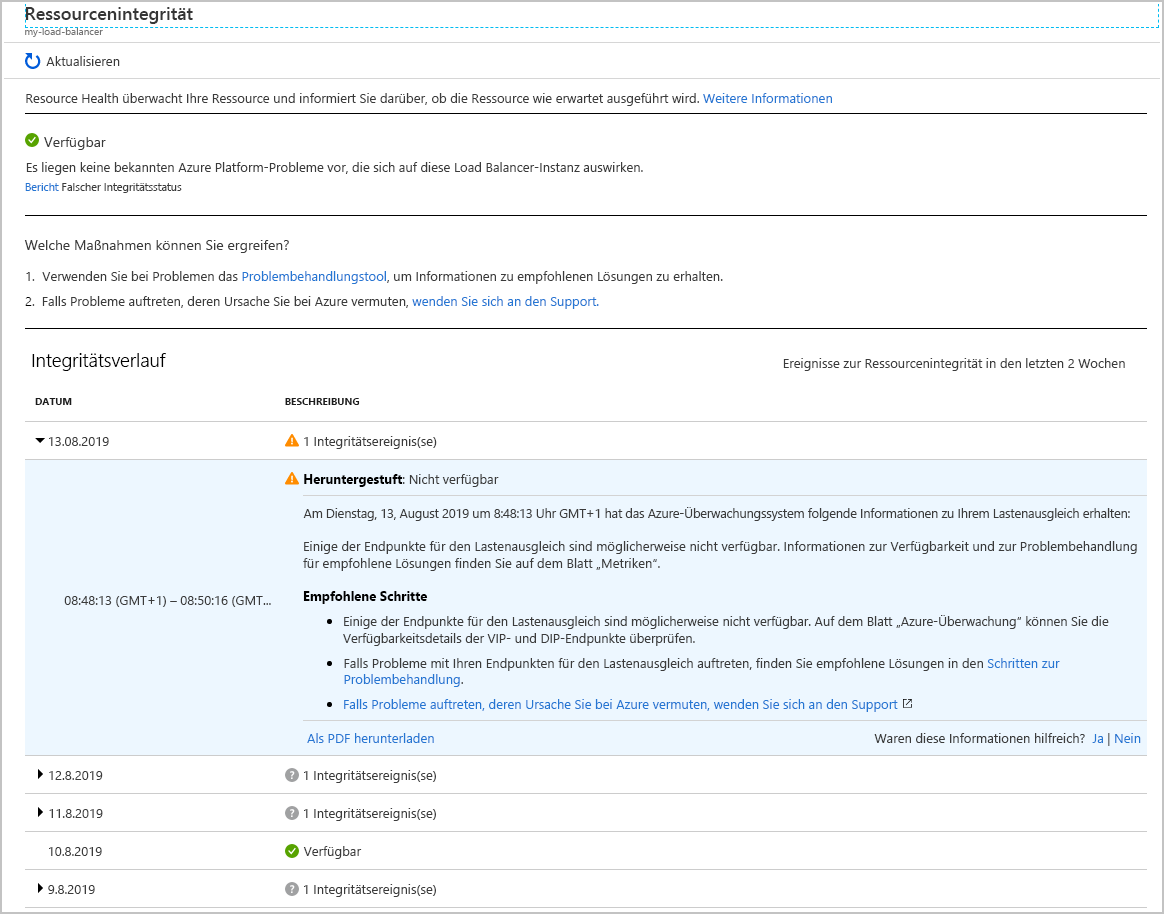
Wählen Sie Ihren Lastenausgleich aus. Sie sehen einen Bericht mit Details zum Integritätsverlauf für Ihren Dienst. Sie können jedes der Elemente dieses Berichts aufklappen, um Details anzuzeigen. In der folgenden Abbildung ist die Zusammenfassung zu sehen, die generiert wird, wenn eine der VMs im Back-End-Pool offline geschaltet wurde.
Überwachen der Workload für die einzelnen VMs
Die anderen für Load Balancer verfügbaren Metriken ermöglichen es Ihnen, die Anzahl von Bytes und Netzwerkpaketen, die über das Front-End durch Load Balancer geleitet werden, zu verfolgen. Ein Front-End ist eine Kombination aus der IP-Adresse von Load Balancer, dem Protokoll, mit dem eingehende Anforderungen akzeptiert werden, und der Portnummer, die von der Lastenausgleichsregel zum Herstellen einer Verbindung mit VMs verwendet wird. Mit diesen Metriken können Sie den Durchsatz Ihres Systems pro aktive VM messen.
Im folgenden Graph ist die durchschnittliche Anzahl von Paketen zu sehen, die Load Balancer beim Ausführen einer zweiminütigen Testworkload mit 500 gleichzeitigen Benutzern durchlaufen. Die Workload wurde zweimal ausgeführt. Beim ersten Mal bestand der Back-End-Pool aus zwei VM-Instanzen. Für den zweiten Durchlauf wurde eine der VMs heruntergefahren (um einen Ausfall zu simulieren).
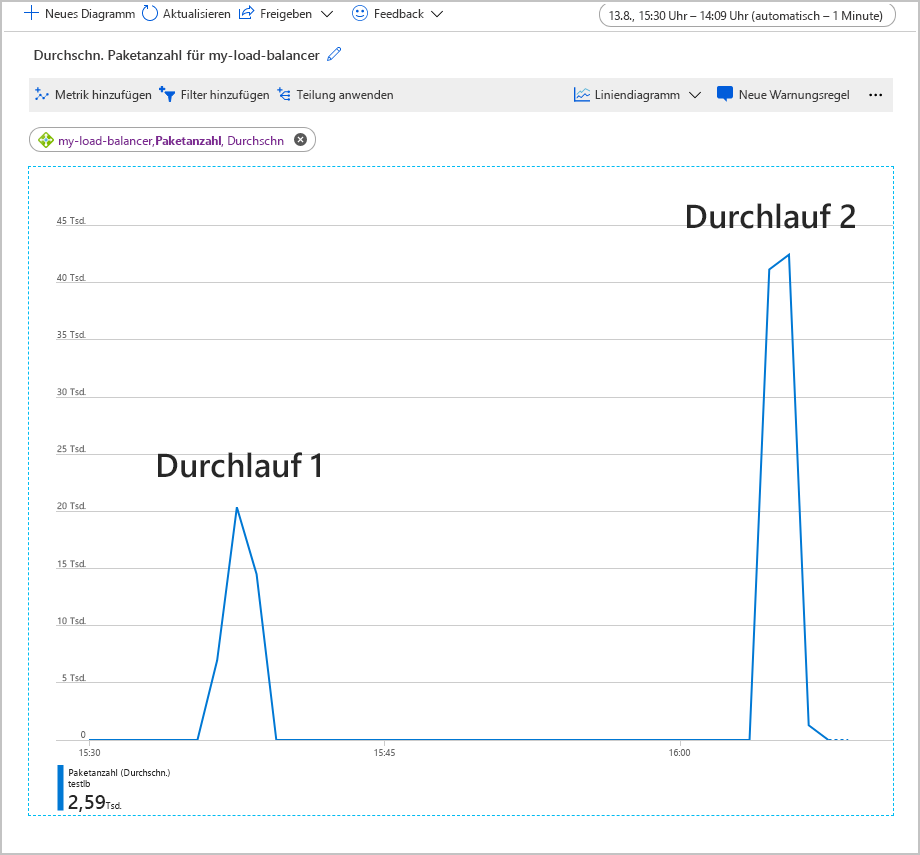
In diesem Diagramm hat sich die durchschnittliche Paketanzahl pro Front-End verdoppelt, als die VM heruntergefahren wurde. Dieses Arbeitsvolumen könnte die verbleibende VM überlasten, was zu längeren Antwortzeiten und möglicherweise zu Timeouts führen kann.
Untersuchen und Beheben häufig auftretender Probleme mit Load Balancer
In diesem Abschnitt werden ein paar häufige Fehlerszenarios behandelt, die Ihnen möglicherweise mit Load Balancer begegnen. Für jedes dieser Szenarios werden die Symptome eines Fehlers zusammengefasst, und es wird erläutert, wie Sie das Problem möglicherweise beheben können.
VMs hinter Load Balancer reagieren nicht auf Datenverkehr am Testport
Dieses Problem kann folgende Ursachen haben:
Die VMs im Back-End-Pool lauschen nicht auf den richtigen Testport.
Überprüfen Sie, ob die Einstellungen für den Integritätstest in Load Balancer korrekt sind. Überprüfen Sie, ob der Anwendungscode, der auf den VMs ausgeführt wird, ordnungsgemäß auf Testanforderungen reagiert. Es sollte eine HTTP 200-Antwortnachricht (OK) zurückgeben werden.
Die Netzwerksicherheitsgruppe für das Subnetz des virtuellen Netzwerks, das die VMs hostet, blockiert den Testport.
Überprüfen Sie die Konfiguration der Netzwerksicherheitsgruppe für das Subnetz des virtuellen Netzwerks, das die VMs enthält. Sorgen Sie dafür, dass die Netzwerksicherheitsgruppe erlaubt, dass Netzwerkdatenverkehr vom Lastenausgleich über den Integritätstestport weitergeleitet werden darf.
Sie versuchen, auf die Load Balancer-Instanz über dieselbe VM und Karte des virtuellen Netzwerks zuzugreifen. Dieses Problem ist unabhängig von den Tests. Es handelt sich um das Szenario eines nicht unterstützten Datenpfads.
Sie versuchen, über eine VM im Back-End-Pool auf das Front-End der Load Balancer-Instanz zuzugreifen.
Bei diesen beiden handelt es sich um Probleme beim Anwendungsdesign. Vermeiden Sie es, von einer VM im Back-End-Pool aus Anforderungen an dieselbe Load Balancer-Instanz zu senden.
Eine VM im Back-End-Pool ist fehlerhaft.
In diesem Fall reagieren die meisten VMs normal. Bei einer oder zweien ist dies jedoch nicht der Fall. Da einige VMs den Datenverkehr akzeptieren, ist der Integritätstest wahrscheinlich richtig konfiguriert. Die Netzwerksicherheitsgruppe für das Subnetz blockiert nicht den Port, der vom Integritätstest verwendet wird. Das Problem hat vermutlich mit den fehlerhaften VMs zu tun. Dieses Problem könnte daran liegen, dass auf die VMs nicht zugegriffen werden kann oder dass sie ausgefallen sind, oder auf diesen VMs besteht ein Anwendungsproblem.
Befolgen Sie die folgenden Schritte, um die Ursache des Problems bei einer fehlerhaften VM festzustellen:
- Melden Sie sich bei einer fehlerhaften VM an, um zu überprüfen, ob sie einsatzbereit ist. Überprüfen Sie, ob die VM auf einfache Tests wie ping-, rdp- oder ssh-Anforderungen von einer anderen VM im Back-End-Pool reagiert.
- Wenn die VM einsatzbereit ist und auf sie zugegriffen werden kann, überprüfen Sie, ob die Anwendung ausgeführt wird.
- Führen Sie den Befehl
netstat -anaus, und überprüfen Sie, ob die vom Integritätstest und der Anwendung verwendeten Ports als LISTENING (LAUSCHT) aufgeführt werden.
Fehlkonfigurationen der Load Balancer-Instanz
Sie müssen die Routingregeln in der Load Balancer-Instanz korrekt konfigurieren, die eingehenden Datenverkehr vom Front-End in den Back-End-Pool weiterleiten. Wenn eine Routingregel fehlt oder nicht ordnungsgemäß konfiguriert ist, wird der Datenverkehr, der am Front-End eingeht, verworfen. Sobald der Datenverkehr verworfen wurde, wird die Anwendung an Clients als unzugänglich gemeldet.
Überprüfen Sie die Weiterleitung über die Load Balancer-Instanz vom Front-End zum Back-End-Pool. Sie können dafür Tools wie Ping, TCPing und netsh verwenden, die unter Windows und Linux zur Verfügung stehen. Sie können auch psping unter Windows verwenden. Die folgenden Abschnitte beschreiben die Verwendung dieser Tools.
Verwenden von ping
Der ping-Befehl testet die ping-Konnektivität über einen Endpunkt mithilfe des ICMP-Protokolls. Führen Sie den folgenden Befehl aus, um zu überprüfen, ob die Weiterleitung von Ihrem Client zu einer VM über die Load Balancer-Instanz möglich ist. Ersetzen Sie <ip address> durch die IP-Adresse der Load Balancer-Instanz.
ping -n 10 <ip address>
| Schalter | Beschreibung |
|---|---|
| -n | Dieser Schalter gibt die Anzahl der zu sendenden Pinganforderungen an. |
Die typische Ausgabe sieht folgendermaßen aus:
ping -n 10 nn.nn.nn.nn
Pinging nn.nn.nn.nn with 32 bytes of data:
Reply from nn.nn.nn.nn: bytes=32 time=34ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=29ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=31ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Reply from nn.nn.nn.nn: bytes=32 time=30ms TTL=114
Ping statistics for nn.nn.nn.nn:
Packets: Sent = 10, Received = 10, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 29ms, Maximum = 34ms, Average = 30ms
Verwenden von „PsPing“
Der PsPing-Befehl testet die ping-Konnektivität über einen Endpunkt. Dieser Befehl misst außerdem die Latenz und die Verfügbarkeit der Bandbreite für einen Dienst. Führen Sie den folgenden Befehl aus, um zu überprüfen, ob die Weiterleitung von Ihrem Client zu einer VM über die Load Balancer-Instanz möglich ist. Ersetzen Sie <ip address> und <port> durch die IP-Adresse und den Front-End-Port der Load Balancer-Instanz.
psping -n 100 -i 0 -q -h <ip address>:<port>
| Flag | Beschreibung |
|---|---|
| -n | Gibt die Anzahl an Pings an, die ausgeführt werden sollen. |
| -i | Gibt das Intervall in Sekunden dann, das zwischen einzelnen Iterationen angewendet werden soll. |
| -q | Unterdrückt die Ausgabe während den Pingiterationen. Am Ende wird nur eine Zusammenfassung angezeigt. |
| -h | Druckt ein Histogramm, in dem die Latenz der Anforderungen angezeigt wird. |
Die typische Ausgabe sieht folgendermaßen aus:
TCP connect to nn.nn.nn.nn:nn:
101 iterations (warmup 1) ping test: 100%
TCP connect statistics for nn.nn.nn.nn:nn:
Sent = 100, Received = 100, Lost = 0 (0% loss),
Minimum = 7.48ms, Maximum = 9.08ms, Average = 8.30ms
Latency Count
7.48 3
7.56 2
7.65 2
7.73 2
7.82 7
7.90 4
7.98 4
8.07 6
8.15 9
8.24 9
8.32 11
8.40 7
8.49 11
8.57 12
8.66 3
8.74 2
8.82 2
8.91 1
8.99 2
9.08 1
Verwenden von „tcping“
Das tcping-Hilfsprogramm ähnelt dem ping, mit der Ausnahme, dass es über eine TCP-Verbindung anstelle von ICMP ausgeführt wird. Verwenden Sie tcping folgendermaßen:
tcping <ip address> <port>
Die typische Ausgabe sieht folgendermaßen aus:
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.042ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.810ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.266ms
Probing nn.nn.nn.nn:nn/tcp - Port is open - time=9.181ms
Ping statistics for nn.nn.nn.nn:nn
4 probes sent.
4 successful, 0 failed. (0.00% fail)
Approximate trip times in milli-seconds:
Minimum = 9.042ms, Maximum = 9.810ms, Average = 9.325ms
Verwenden von „Netsh“
Das netsh-Hilfsprogramm ist ein universelles Netzwerkkonfigurationstool. Verwenden Sie den Befehl trace in netsh, um den Netzwerkdatenverkehr zu erfassen. Analysieren Sie sie dann mithilfe eines Tools wie Wireshark. Verwenden Sie netsh trace beim Testen der Konnektivität über die Load Balancer-Instanz folgendermaßen, um die Netzwerkpakete zu untersuchen, die von psping gesendet und empfangen werden:
Starten Sie über eine Eingabeaufforderung als Administrator eine Netzwerkablaufverfolgung. Im folgenden Beispiel wird Datenverkehr eines Internetclients überwacht (HTTP-Anforderungen), der an eine bestimmte IP-Adresse gesendet und von ihr empfangen wird. Ersetzen Sie <ip address> durch die Adresse der Load Balancer-Instanz. Die Ablaufverfolgungsdaten werden in die Datei trace.etl geschrieben.
netsh trace start ipv4.address=<ip address> capture=yes scenario=internetclient tracefile=trace.etlFühren Sie psping aus, um die Konnektivität über die Load Balancer-Instanz zu testen.
psping -n 100 -i 0 -q <ip address>:<port>Stoppen Sie die Ablaufverfolgung.
netsh trace stopDie Ausführung dieses Befehls dauert einige Minuten, da Informationen korreliert und zusammengeführt werden, während die Ausgabedatei der Ablaufverfolgung erstellt wird.
Starten Sie Wireshark, und öffnen Sie die Ablaufverfolgungsdatei.
Fügen Sie der Ablaufverfolgung den folgenden Filter hinzu. Ersetzen Sie <nn> durch die Front-End-Portnummer der Load Balancer-Instanz.
TCP.Port==80 or TCP.Port==<nn>Fügen Sie die Quelle und das Ziel der HTTP-Anforderung in der Ablaufverfolgungsausgabe als Felder hinzu.
Sehen Sie sich die Ablaufverfolgungsmeldungen an:
- Wenn es keine eingehenden Pakete für die Load Balancer-Instanz gibt, liegt vermutlich ein Netzwerksicherheitsproblem oder ein benutzerdefiniertes Routingproblem vor.
- Wenn an den Client keine ausgehenden Pakete zurückgegeben werden, besteht vermutlich ein Problem bei der Anwendungskonfiguration oder ein benutzerdefiniertes Routingproblem.
Blockierung des Ports durch VM-Firewall oder Netzwerksicherheitsgruppe
Wenn das Netzwerk und der Load Balancer ordnungsgemäß konfiguriert sind, die VM aktiv ist und die Anwendung ausgeführt wird, könnte die Firewall- oder NSG-Konfiguration für die VMs den vom Integritätstest oder der Anwendung verwendeten Port blockieren. Führen Sie die folgenden Schritte aus, um festzustellen, ob dies der Fall ist:
Wenn auf der VM eine Firewall vorhanden ist, könnte diese Anforderungen auf den Ports blockieren, die vom Integritätstest und der Anwendung verwendet werden. Überprüfen Sie die Firewallkonfiguration auf dem Host, um sicherzustellen, dass Datenverkehr auf den Ports zulässig ist, die vom Integritätstest und der Anwendung verwendet werden.
Stellen Sie sicher, dass alle Netzwerksicherheitsgruppen für die NIC der VM ausgehenden und eingehenden Datenverkehr auf den erforderlichen Ports zulassen. Überprüfen Sie, ob es in der Netzwerksicherheitsgruppe eine Alle ablehnen-Regel auf der NIC der VM gibt, die eine höhere Priorität hat als die Standardregel.
Wichtig
Sie können eine Netzwerksicherheitsgruppe einem Subnetz und den einzelnen NICs von VMs im Subnetz zuordnen. Möglicherweise haben Sie die Netzwerksicherheitsgruppe für ein Subnetz konfiguriert, sodass erlaubt wird, dass Datenverkehr über einen Port weitergeleitet wird. Wenn die Netzwerksicherheitsgruppe einer VM jedoch denselben Port schließt, können Anforderungen nicht zu dieser VM weitergeleitet werden.
Einschränkungen von Load Balancer
Load Balancer wird in Schicht 4 im ISO-Netzwerkstapel betrieben und untersucht die Inhalte von Netzwerkpaketen nicht oder verändert sie auf andere Weise. Sie können Load Balancer nicht verwenden, um inhaltsbasierte Weiterleitung zu implementieren.
Alle Clientanforderungen werden von einer VM im Back-End-Pool beendet. Load Balancer ist nicht sichtbar für Clients. Wenn keine VMs verfügbar sind, schlägt die Clientanforderung fehl. Clientanwendungen können nicht mit Load Balancer oder einer der Komponenten des Diensts kommunizieren oder den Status des Diensts auf andere Art und Weise abrufen.
Wenn Sie einen auf den Inhalten von Nachrichten basierenden Lastenausgleich implementieren möchten, sollten Sie die Verwendung von Azure Application Gateway in Erwägung ziehen. Alternativ können Sie einen Proxywebserver konfigurieren, der eingehende Clientanforderungen verarbeitet und sie an bestimmte VMs weiterleitet.