Partitionieren von Datendateien
Die Partitionierung ist eine Optimierungsmethode, mit der Spark die Leistung auf den Workerknoten maximieren kann. Beim Filtern von Daten in Abfragen können weitere Leistungssteigerungen erzielt werden, indem unnötige Datenträger-E/A-Vorgänge eliminiert werden.
Partitionieren der Ausgabedatei
Um einen Dataframe als partitionierte Gruppe von Dateien zu speichern, verwenden Sie beim Schreiben der Daten die partitionBy-Methode.
Im folgenden Beispiel wird ein abgeleitetes Year-Feld erstellt. Anschließend wird es verwendet, um die Daten zu partitionieren.
from pyspark.sql.functions import year, col
# Load source data
df = spark.read.csv('/orders/*.csv', header=True, inferSchema=True)
# Add Year column
dated_df = df.withColumn("Year", year(col("OrderDate")))
# Partition by year
dated_df.write.partitionBy("Year").mode("overwrite").parquet("/data")
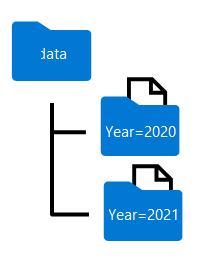
Die Ordnernamen, die beim Partitionieren eines Dataframes generiert werden, enthalten den Namen der Partitionierungsspalte und den Wert im Format Spalte=Wert, wie hier gezeigt:
Hinweis
Sie können die Daten nach mehreren Spalten partitionieren, wodurch eine Hierarchie von Ordnern für jeden Partitionsschlüssel entsteht. Beispielsweise könnten Sie die Reihenfolge im Beispiel nach Jahr und Monat partitionieren, sodass die Ordnerhierarchie einen Ordner für jeden Jahreswert enthält, der wiederum einen Unterordner für jeden Monatswert enthält.
Filtern von Parquet-Dateien in einer Abfrage
Beim Lesen von Daten aus Parquet-Dateien in einen Dataframe können Sie Daten aus jedem Ordner innerhalb der hierarchischen Ordner abrufen. Dieser Filtervorgang erfolgt unter Verwendung expliziter Werte und Platzhalter für die partitionierten Felder.
Im folgenden Beispiel pullt der folgende Code die Aufträge, die 2020 erstellt wurden.
orders_2020 = spark.read.parquet('/partitioned_data/Year=2020')
display(orders_2020.limit(5))
Hinweis
Die im Dateipfad angegebenen Partitionierungsspalten werden im resultierenden Dataframe nicht angegeben. Die von der Beispielabfrage zurückgegebenen Ergebnisse enthalten keine Year-Spalte. Alle Zeilen stammen aus dem Jahr 2020.