Einführung
Clustering ist der Prozess der Gruppierung von Objekten mit ähnlichen Objekten. In der folgenden Abbildung finden Sie beispielsweise eine Sammlung von 2D-Koordinaten, die in drei Kategorien gruppiert wurden: oben links (gelb), unten (rot) und oben rechts (blau).
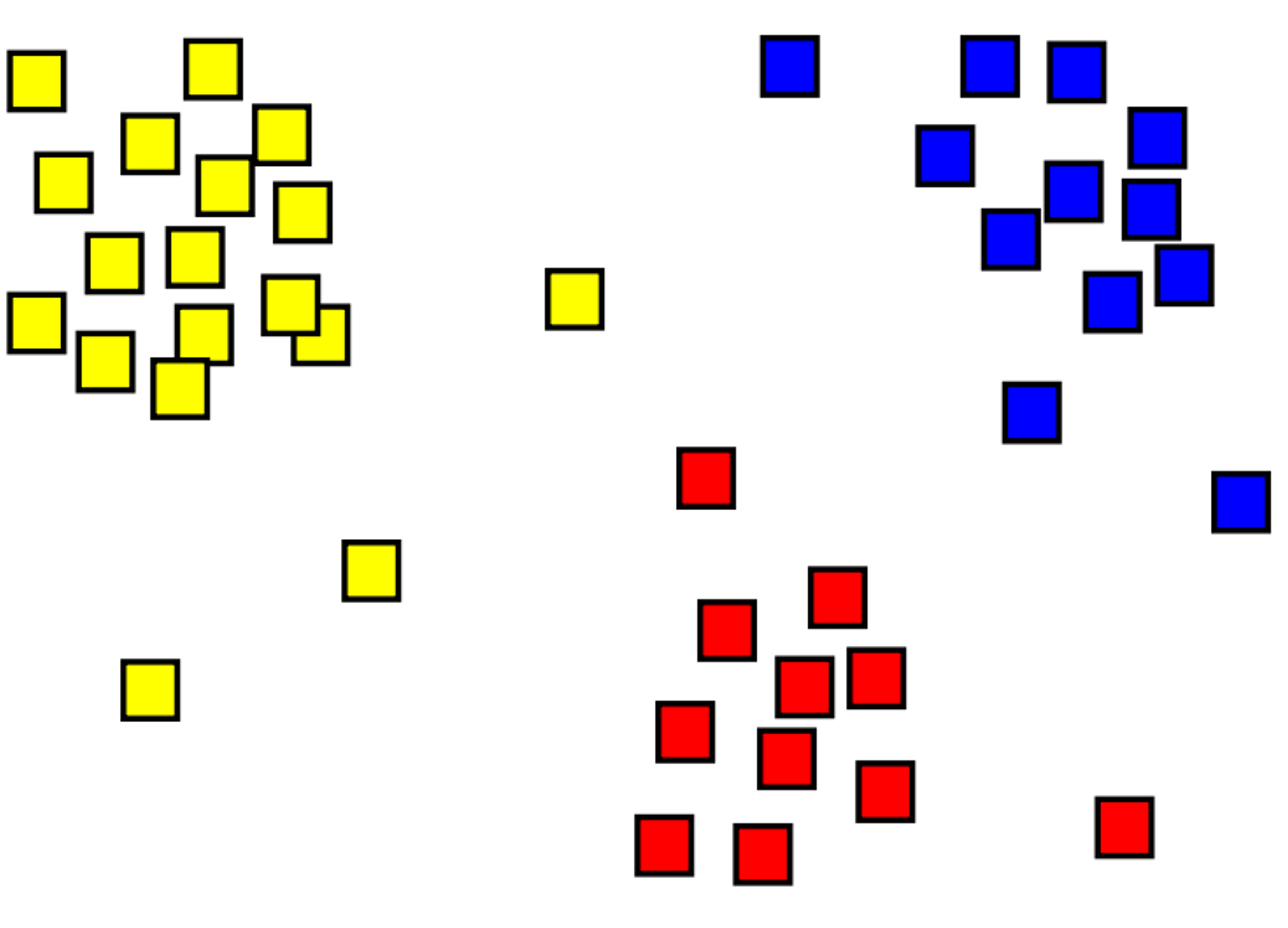
Ein Hauptunterschied zwischen Clustering- und Klassifizierungsmodellen besteht darin, dass Clustering eine nicht überwachte Methode ist, bei der das Training ohne Bezeichnungen erfolgt. Clusteringmodelle identifizieren Beispiele mit einer ähnlichen Sammlung von Features. In der Abbildung oben werden Beispiele gruppiert, die sich an einem ähnlichen Ort befinden.
Clustering wird üblicherweise eingesetzt, um neue Daten zu untersuchen, bei denen Muster zwischen Datenpunkten, z. B. allgemeinen Kategorien, noch nicht bekannt sind. Es wird in vielen Feldern verwendet, die komplexe Daten automatisch bezeichnen müssen, einschließlich Analyse sozialer Netzwerke, Gehirnkonnektivität, Spamfilterung usw.