Test- und Trainingsdatasets
Die zum Trainieren eines Modells verwendeten Daten werden häufig als Trainingsdataset bezeichnet. Das haben wir schon in Aktion gesehen. Wenn wir das Modell nach dem Training unter realen Bedingungen verwenden, wissen wir leider nicht genau, wie gut unser Modell funktioniert. Diese Unsicherheit ist darauf zurückzuführen, dass sich unser Trainingsdataset von den Daten in der realen Welt unterscheiden kann.
Was ist Überanpassung?
Ein Modell ist überangepasst, wenn es für die Trainingsdaten besser funktioniert als für andere Daten. Der Name bezieht sich auf die Tatsache, dass das Modell so gut angepasst wurde, dass es sich Details des Trainingsdatasets gemerkt hat, anstatt allgemeine Regeln zu finden, die auch auf andere Daten angewendet werden können. Eine Überanpassung ist üblich, aber nicht wünschenswert. Letzten Endes ist es nur wichtig, wie gut unser Modell bei realen Daten funktioniert.
Wie können wir eine Überanpassung vermeiden?
Eine Überanpassung kann auf verschiedene Arten vermieden werden. Die einfachste Möglichkeit besteht darin, ein einfacheres Modell einzusetzen oder ein Dataset zu verwenden, das die realen Gegebenheiten besser darstellt. Um diese Methoden zu verstehen, stellen Sie sich ein Szenario vor, in dem reale Daten wie folgt aussehen:
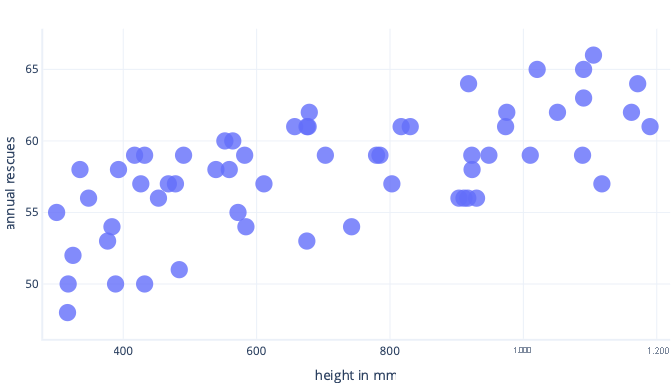
Angenommen, wir sammeln Informationen über nur fünf Hunde und verwenden diese als Trainingsdataset, um eine komplexe Kurve anzupassen. Wenn wir das so machen, können wir sie sehr gut anpassen:
Bei Verwendung unter realen Bedingungen werden wir jedoch feststellen, dass sich die getroffenen Vorhersagen als falsch erweisen:
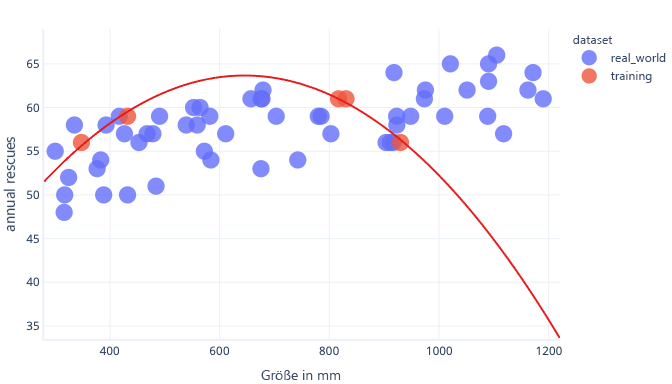
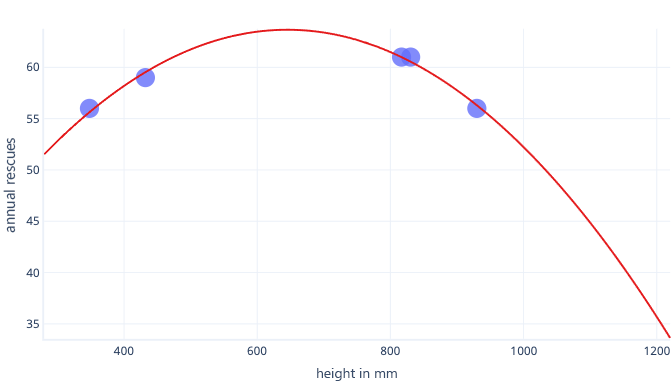
Hätten wir ein repräsentativeres Dataset und ein einfacheres Modell, würde die von uns angepasste Kurve bessere, wenn auch nicht perfekte, Vorhersagen liefern:
Eine weitere Möglichkeit zur Vermeidung einer Überanpassung besteht darin, das Training zu beenden, nachdem das Modell allgemeine Regeln gelernt hat, aber bevor das Modell überangepasst wurde. Dazu müssen wir jedoch erkennen, ab wann eine Überanpassung unseres Modell stattfindet. Dies ist mithilfe eines Testdatasets möglich.
Was ist ein Testdataset?
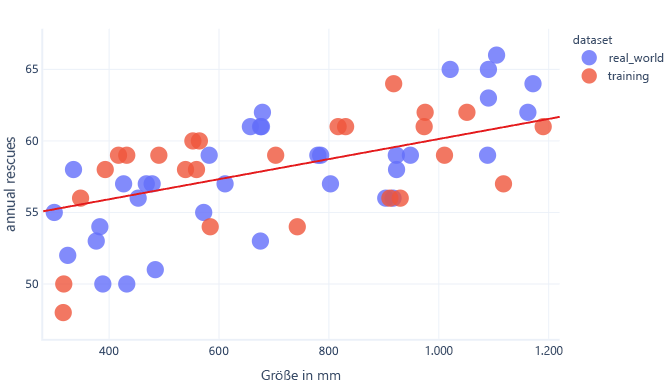
Ein Testdataset (auch als Validierungsdataset bezeichnet) ist ein Satz von Daten, der dem Trainingsdataset ähnlich ist. Tatsächlich werden Testdatasets in der Regel erstellt, indem ein großes Dataset verwendet und aufgeteilt wird. Ein Teil wird als Trainingsdataset und der andere als Testdataset bezeichnet.
Die Aufgabe des Trainingsdatasets besteht im Trainieren des Modells, der zugehörige Trainingsprozess wurde bereits erörtert. Das Testdataset soll überprüfen, wie gut das Modell funktioniert. Es trägt nicht direkt zum Training bei.
Okay, aber wo liegt der Sinn?
Ein Testdataset hat einen zweifachen Sinn.
Erstens: Wenn sich die Testleistung während des Trainings nicht mehr verbessert, können wir das Training beenden – eine weitere Fortsetzung hat keinen Nutzen. Wenn wir das Training fortsetzen, kann es passieren, dass das Modell Details über das Trainingsdataset lernt, die nicht im Testdataset enthalten sind, was eine Überanpassung darstellt.
Zweitens: Wir können nach dem Training ein Testdataset verwenden. Dies gibt uns einen Hinweis darauf, wie gut das endgültige Modell funktioniert, wenn „reale“ Daten verwendet werden, die zuvor unbekannt waren.
Was bedeutet das für Kostenfunktionen?
Wenn wir sowohl ein Trainings- als auch ein Testdataset verwenden, berechnen wir am Ende zwei Kostenfunktionen.
Die erste Kostenfunktion verwendet das Trainingsdataset, wie wir es zuvor gesehen haben. Diese Kostenfunktion wird an den Optimierer übergeben und zum Trainieren des Modells verwendet.
Die zweite Kostenfunktion wird mithilfe des Testdatasets berechnet. Auf diese Weise können wir überprüfen, wie gut das Modell unter realen Bedingungen funktionieren kann. Das Ergebnis der Kostenfunktion wird nicht zum Trainieren des Modells verwendet. Um dies zu berechnen, unterbrechen wir das Training, sehen uns an, wie gut das Modell mit einem Testdataset funktioniert, und setzen dann das Training fort.