Indizieren beliebiger Daten mithilfe der Push-API der Azure KI-Suche
Die REST-API ist die flexibelste Möglichkeit, Daten an einen Index der Azure KI-Suche zu pushen. Sie können jede Programmiersprache oder interaktiv jede App verwenden, die JSON-Anforderungen an einen Endpunkt posten kann.
Hier erfahren Sie, wie Sie die REST-API effektiv verwenden und die verfügbaren Vorgänge untersuchen. Anschließend sehen Sie sich .NET Core-Code an und erfahren, wie Sie das Hinzufügen großer Datenmengen über die API optimieren können.
Unterstützte REST-API-Vorgänge
Die KI-Suche stellt zwei unterstützte REST-APIs bereit. Such- und Verwaltungs-APIs. Dieses Modul konzentriert sich auf die Such-REST-APIs, die Vorgänge für fünf Suchfeatures bereitstellen:
| Feature | Operations |
|---|---|
| Index | Erstellen, Löschen, Aktualisieren und Konfigurieren |
| Dokument | Abrufen, Hinzufügen, Aktualisieren und Löschen |
| Indexerstellung | Konfigurieren von Datenquellen und Planen mit eingeschränkten Datenquellen |
| Fähigkeitengruppe | Abrufen, Erstellen, Löschen, Auflisten und Aktualisieren |
| Synonymzuordnung | Abrufen, Erstellen, Löschen, Auflisten und Aktualisieren |
Aufrufen der Such-REST-API
Wenn Sie eine der Such-APIs aufrufen möchten, müssen Sie Folgendes tun:
- Verwenden Sie den HTTPS-Endpunkt über den Standardport 443, der von Ihrem Suchdienst bereitgestellt wird. Sie müssen eine api-version in den URI einschließen.
- Der Anforderungsheader muss ein api-key-Attribut enthalten.
Um den Endpunkt zu finden, wechseln „api-version“ und „api-key“ zum Azure-Portal.

Navigieren Sie im Portal zu Ihrem Suchdienst, und wählen Sie dann den Such-Explorer aus. Der REST-API-Endpunkt befindet sich im Feld Anforderungs-URL. Der erste Teil der URL ist der Endpunkt (z. B. https://azsearchtest.search.windows.net) und die Abfragezeichenfolge zeigt die api-version (z. B. api-version=2023-07-01-Preview).

Um den api-key links zu suchen, wählen Sie Schlüssel aus. Der primäre oder sekundäre Administratorschlüssel kann verwendet werden, wenn Sie die REST-API nutzen, um mehr als nur die Abfrage des Indexes auszuführen. Wenn Sie nur einen Index durchsuchen müssen, können Sie Abfrageschlüssel erstellen und verwenden.
Um Daten in einem Index hinzuzufügen, zu aktualisieren oder zu löschen, müssen Sie einen Administratorschlüssel verwenden.
Hinzufügen von Daten zu einem Index
Verwenden Sie eine HTTP POST-Anforderung mithilfe des Indizesfeatures in diesem Format:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
Der Text ihrer Anforderung muss dem REST-Endpunkt mitteilen, welche Aktion für das Dokument ausgeführt werden soll, auf welches Dokument die Aktion angewendet werden soll und welche Daten verwendet werden sollen.
Der JSON-Code muss in diesem Format vorliegen:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Aktion | BESCHREIBUNG |
|---|---|
| upload | Ähnlich wie bei einem Upsert in SQL wird das Dokument erstellt oder ersetzt. |
| merge | „Merge“ aktualisiert ein bestehendes Dokument mit den angegebenen Feldern. „Merge“ schlägt fehl, wenn kein Dokument gefunden werden kann. |
| mergeOrUpload | „Merge“ aktualisiert ein vorhandenes Dokument mit den angegebenen Feldern, und lädt es hoch, wenn das Dokument nicht vorhanden ist. |
| delete | Löscht das gesamte Dokument. Sie müssen nur „key_field_name“ angeben. |
Wenn Ihre Anforderung erfolgreich ist, gibt die API einen Statuscode von 200 zurück.
Hinweis
Eine vollständige Liste aller Antwortcodes und Fehlermeldungen finden Sie unter Hinzufügen, Aktualisieren oder Löschen von Dokumenten (REST-API der Azure KI-Suche).
In diesem Beispiel-JSON wird der Kundendatensatz in der vorherigen Einheit hochgeladen:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
Sie können beliebig viele Dokumente im Wertarray hinzufügen. Für eine optimale Leistung sollten Sie jedoch das Batching der Dokumente in Ihren Anforderungen bis zu maximal 1.000 Dokumente oder 16 MB Gesamtgröße in Betracht ziehen.
Verwenden von .NET Core zum Indizieren von Daten
Für optimale Leistung verwenden Sie die neueste Azure.Search.Document-Clientbibliothek, derzeit Version 11. Sie können die Clientbibliothek mit NuGet installieren:
dotnet add package Azure.Search.Documents --version 11.4.0
Die Leistung Ihres Index basiert auf sechs wichtigen Faktoren:
- Der Suchdienstebene und wie viele Replikate und Partitionen Sie aktiviert haben
- Der Komplexität des Indexschemas. Verringern Sie die Anzahl der Eigenschaften in jedem Feld (durchsuchbar, facettenreich, sortierbar).
- Der Anzahl der Dokumente in jedem Batch. Die passende Größe hängt vom Indexschema und der Größe der Dokumente ab.
- Wie viele Threads Ihr Ansatz umfasst
- Handhaben von Fehlern und Drosselung. Verwenden Sie eine Wiederholungsstrategie mit exponentiellem Backoff.
- Wo sich Ihre Daten befinden. Versuchen Sie, Ihre Daten so nah wie möglich an Ihrem Suchindex zu indizieren. Führen Sie beispielsweise Uploads aus der Azure-Umgebung aus.
Ermitteln der optimalen Batchgröße
Da die beste Batchgröße ein wichtiger Faktor für die Verbesserung der Leistung ist, sehen Sie sich einen Ansatz im Code an.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Der Ansatz besteht darin, die Batchgröße zu erhöhen und die Zeit zu überwachen, die zum Erreichen einer gültigen Antwort benötigt wird. Der Code wird von 100 bis 1.000 in 100 Dokumentschritten durchlaufen. Für jede Batchgröße gibt er die Dokumentgröße, die Zeit bis zum Erhalten einer Antwort und die durchschnittliche Zeit pro MB aus. Wenn Sie diesen Code ausführen, werden Ergebnisse wie das folgende angezeigt:
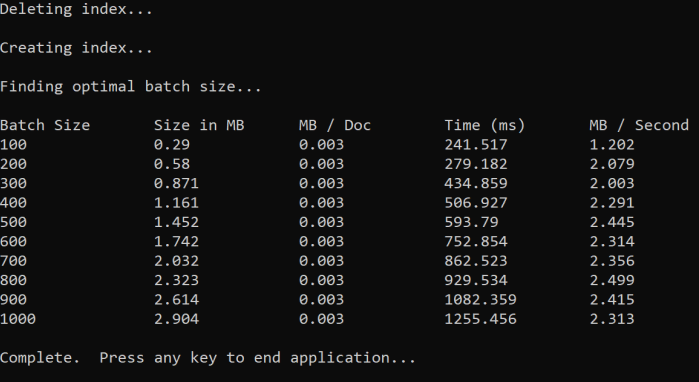
Im obigen Beispiel beträgt die beste Batchgröße für den Durchsatz 2,499 MB pro Sekunde und 800 Dokumente pro Batch.
Implementieren einer Wiederholungsstrategie mit exponentiellem Backoff
Wenn Ihr Index aufgrund von Überladen Anforderungen drosselt, erhalten Sie den Status 503 (Anforderung abgelehnt aufgrund hoher Auslastung) oder 207 (einige Dokumente im Batch fehlgeschlagen). Sie müssen auf diese Antworten reagieren, und eine gute Strategie besteht darin, ein Backoff durchzuführen. Das bedeutet, einige Zeit zu warten, bevor Sie Ihre Anforderung wiederholen. Wenn Sie diese Zeit für jeden Fehler erhöhen, führen Sie ein exponentielles Backoff durch.
Sehen Sie sich diesen Code an:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Der Code verfolgt fehlerhafte Dokumente in einem Batch nach. Wenn ein Fehler auftritt, wartet er auf eine Verzögerung und verdoppelt dann die Verzögerung für den nächsten Fehler.
Außerdem gibt es eine maximale Anzahl von Wiederholungen, und wenn diese maximale Anzahl erreicht ist, ist das Programm vorhanden.
Verwenden von Threading zum Verbessern der Leistung
Sie können Ihre Dokumentupload-App abschließen, indem Sie die oben genannte Backoff-Strategie mit einem Threadingansatz kombinieren. Der folgende Code enthält ein Beispiel hierzu:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Dieser Code verwendet asynchrone Aufrufe einer ExponentialBackoffAsync-Funktion, die die Backoffstrategie implementiert. Sie rufen die Funktion mithilfe von Threads auf, z. B. der Anzahl der Kerne, über die Ihr Prozessor verfügt. Wenn die maximale Anzahl von Threads verwendet wurde, wartet der Code, bis ein Thread abgeschlossen wurde. Anschließend wird ein neuer Thread erstellt, bis alle Dokumente hochgeladen wurden.