Erste Schritte mit Azure KI Vision
Die Fähigkeit von Computersystemen, geschriebenen und gedruckten Text zu verarbeiten, ist ein Bereich der KI, in dem sich maschinelles Sehen und die Verarbeitung natürlicher Sprache überschneiden. Zum „Lesen“ des Texts ist maschinelles Sehen notwendig und anschließend linguistische Datenverarbeitung, damit das Ganze einen Sinn ergibt.
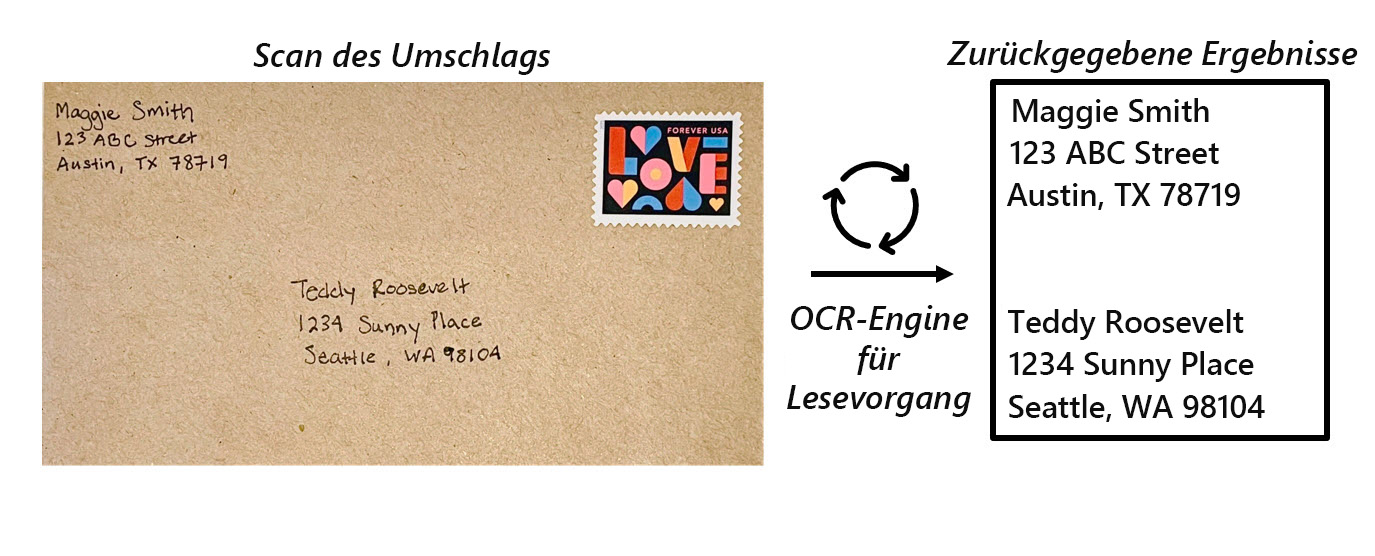
OCR ist die Grundlage für die Verarbeitung von Text in Bildern. Sie verwendet Machine Learning-Modelle, die darauf trainiert werden, einzelne Formen als Buchstaben, Ziffern, Interpunktion oder andere Textelemente zu erkennen. Ein Großteil der frühen Arbeiten zur Implementierung dieser Art von Funktionen wurde von Postdiensten durchgeführt, um die automatische Sortierung von Post anhand von Postleitzahlen zu unterstützen. Seitdem hat sich der Stand der Technik zum Lesen von Text weiterentwickelt. Inzwischen gibt es Modelle, die gedruckten oder handgeschriebenen Text in einem Bild erkennen und zeilen- und wortweise lesen können.
OCR-Engine von Azure KI Vision
Der Azure KI Vision-Dienst verfügt über die Möglichkeit, maschinenlesbaren Text aus Bildern zu extrahieren. Die Lese-API von Azure KI Vision ist das OCR-Modul, das die Textextraktion von Bildern, PDFs und TIFF-Dateien unterstützt. OCR für Bilder ist für allgemeine, nicht-dokumentarische Bilder optimiert, was die Einbettung von OCR in Ihre Benutzerszenarien erleichtert.
Die Lese-API, auch bekannt als Lese-OCR-Engine verwendet die neuesten Erkennungsmodelle und ist für Bilder optimiert, die große Textmengen oder hohes visuelles Rauschen aufweisen. Sie kann automatisch das richtige Erkennungsmodell ermitteln, das unter Berücksichtigung der Anzahl von Textzeilen, Bildern mit Text und Handschrift verwendet werden soll.
Die OCR-Engine übernimmt eine Bilddatei und identifiziert begrenzungsgebundene Felder oder Koordinaten, in denen sich Elemente in einem Bild befinden. In OCR identifiziert das Modell Begrenzungsfelder um alle Elemente, die als Text im Bild erscheinen.
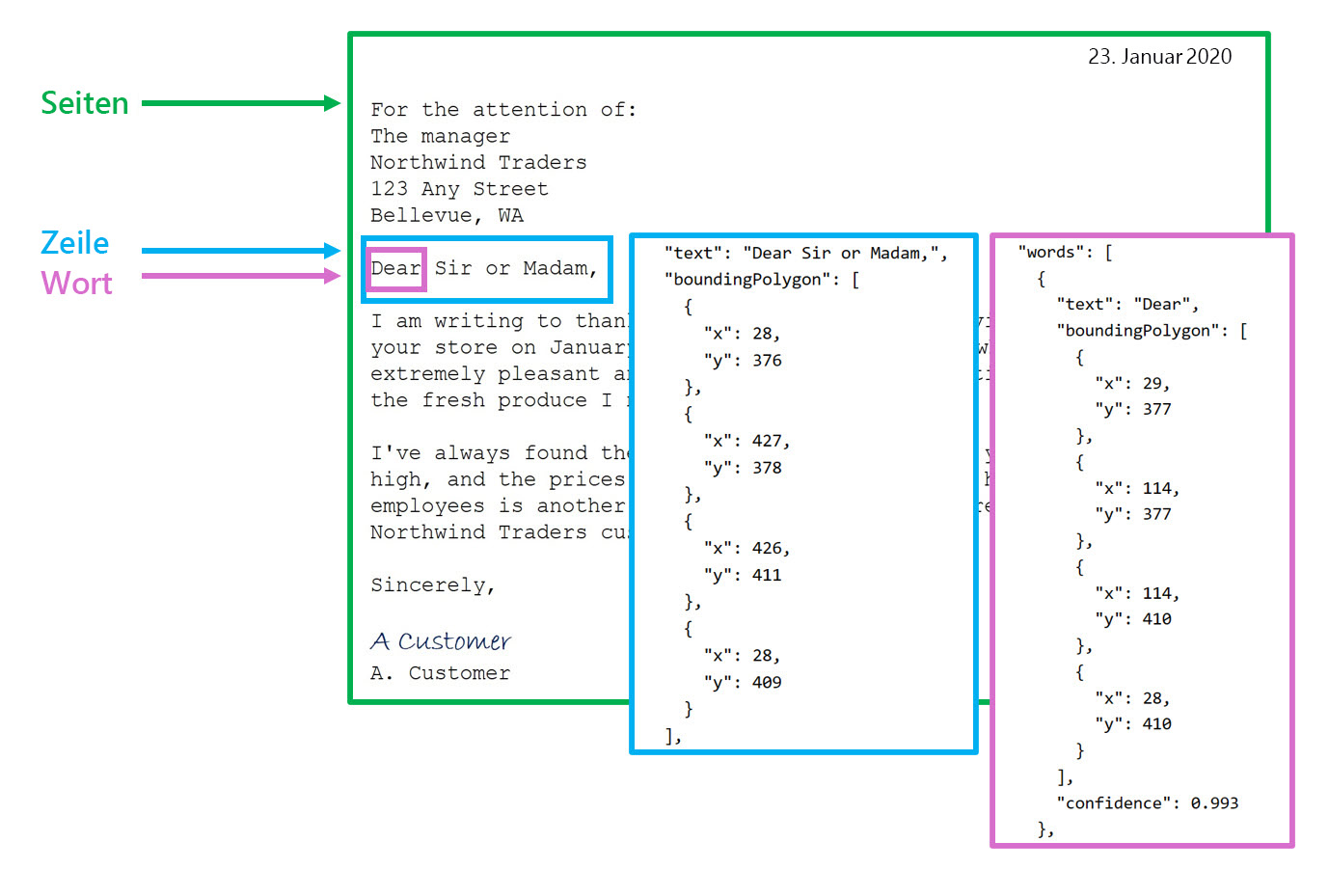
Das Aufrufen der Lese-API gibt die Ergebnisse angeordnet in der folgenden Hierarchie zurück:
- Seiten: Eine für jede Textseite, einschließlich Informationen zur Seitengröße und -ausrichtung
- Zeilen: Die Textzeilen auf einer Seite
- Wörter: Die Wörter in einer Textzeile, einschließlich der Begrenzungsfeldkoordinaten und des Texts selbst
Jede Zeile und jedes Wort enthält Begrenzungsrahmenkoordinaten, die die Position auf der Seite angeben.