Integrieren von Apache Spark- und Hive LLAP-Abfragen
In der vorherigen Lerneinheit wurden zwei Möglichkeiten zum Abfragen statischer Daten vorgestellt, die in einem Interactive Query-Cluster gespeichert werden: Data Analytics Studio und Zeppelin-Notebooks. Wie können Sie jedoch vorgehen, wenn Sie neue Immobiliendaten mit Spark an Ihre Cluster streamen und dann mit Hive abfragen möchten? Da Hive und Spark über zwei unterschiedliche Metastores verfügen, erfordern sie einen Connector, der als Brücke fungiert: den Apache Hive Warehouse Connector (HWC). Mit der HWC-Bibliothek können Sie einfacher mit Apache Spark und Apache Hive arbeiten, da Aufgaben wie das Verschieben von Daten zwischen Spark-Dataframes und Hive-Tabellen oder das Einspeisen von Spark-Streamingdaten in Hive-Tabellen unterstützt werden. Im Rahmen des Beispielszenarios wird der Connector nicht eingerichtet, allerdings ist es wichtig, dass Sie über diese Option informiert sind.
Apache Spark verfügt über eine Structured Streaming-API, die Streamingfunktionen bereitstellt, die in Apache Hive nicht verfügbar sind. Ab HDInsight 4.0 verfügen Apache Spark 2.3.1 und Apache Hive 3.1.0 über separate Metastores, was die Interoperabilität erschwert. Der Hive Warehouse-Connector vereinfacht die gemeinsame Nutzung von Spark und Hive. Die HWC-Bibliothek lädt Daten aus LLAP-Daemons parallel in Spark-Executors, sodass eine höhere Effizienz und Skalierbarkeit als bei der Verwendung einer JDBC-Standardverbindung zwischen Spark und Hive gewährleistet wird.
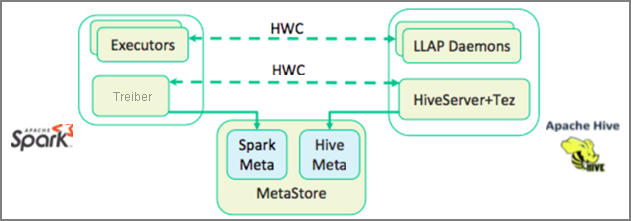
Einige Vorgänge, die von Hive Warehouse Connector unterstützt werden, sind:
- Beschreiben einer Tabelle
- Erstellen einer Tabelle für Daten im ORC-Format (Optimized Row Columnar)
- Auswählen von Hive-Daten und Abrufen eines Datenrahmens
- Schreiben eines Datenrahmens in Hive als Batchvorgang
- Ausführen einer Hive-Aktualisierungsanweisung
- Lesen von Tabellendaten aus Hive, Durchführen der Transformation für Spark und Schreiben der Daten in eine neue Hive-Tabelle
- Schreiben eines Datenrahmens oder Spark-Streams in Hive per HiveStreaming
Sobald Sie über einen Spark-Cluster verfügen und einen Interactive Query-Cluster bereitgestellt haben, konfigurieren Sie die Spark-Clustereinstellungen in Ambari, einem webbasierten Tool, das in allen HDInsight-Clustern enthalten ist. Navigieren Sie im Browser zu https://servername.azurehdinsight.net, und ersetzen Sie servername dabei durch den Namen Ihres Interactive Query-Clusters.
Zum Schreiben von Spark-Streamingdaten in die Tabellen erstellen Sie dann eine Hive-Tabelle, in die Sie Daten schreiben. Führen Sie anschließend Abfragen für Ihre Streamingdaten aus. Hierzu können Sie eine der folgenden Optionen verwenden.
- Spark-Shell
- PySpark
- spark-submit
- Zeppelin
- Livy