Übung: Hochladen und Abfragen von Daten in HDInsight
Nachdem Sie ein Speicherkonto und einen Interactive Query-Cluster bereitgestellt haben, besteht Ihre nächste Aufgabe darin, Ihre Immobiliendaten hochzuladen und einige Abfragen auszuführen. Bei den Daten, die Sie hochladen, handelt es sich um Immobiliendaten zu New York City. Sie umfassen mehr als 28.000 Grundstücksdatensätze, einschließlich Adressen, Verkaufspreisen, Quadratmeterzahlen und Standortinformationen mit Geocodierung zur einfachen Kartierung. Ihr Immobilieninvestmentunternehmen verwendet diese Informationen, um richtige Preise nach der Quadratmeterzahl anhand der Verkaufspreise zuvor verkaufter Grundstücke für neue Grundstücke zu ermitteln, die auf dem Markt verfügbar werden.
Zum Hochladen und Abfragen von Daten wird Data Analytics Studio verwendet. Dabei handelt es sich um eine webbasierte Anwendung, die im Rahmen der Skriptaktion installiert wurde, als Sie den Interactive Query-Cluster erstellt haben. Sie können Data Analytics Studio verwenden, um Daten in Azure Storage hochzuladen, die Daten mithilfe der von Ihnen festgelegten Datentypen und Spaltennamen in Hive-Tabellen zu transformieren und dann die Daten in Ihrem Cluster mit HiveQL abzufragen. Zusätzlich zu Data Analytics Studio können Sie beliebige ODBC-/JDBC-konforme Tools verwenden, um über Hive mit Ihren Daten zu arbeiten, z. B. die Spark- und Hive-Tools für Visual Studio Code.
Als Nächstes verwenden Sie ein Zeppelin-Notebook, um Trends in den Daten in kürzester Zeit grafisch zu darzustellen. Mit Zeppelin-Notebooks können Sie Abfragen senden und die Ergebnisse in verschiedenen vordefinierten Diagrammen anzeigen. Die auf Interactive Query-Clustern installierten Zeppelin-Notebooks umfassen einen JDBC-Interpreter mit einem Hive-Treiber.
Herunterladen von Immobiliendaten
- Wechseln Sie zu https://github.com/Azure/hdinsight-mslearn/tree/master/Sample%20data, und laden Sie das Dataset herunter, um die Datei „propertysales.csv“ auf Ihrem Computer zu speichern.
Hochladen der Daten mit Data Analytics Studio
- Öffnen Sie nun Data Analytics Studio mithilfe der folgenden URL in Ihrem Browser, indem Sie servername durch den Clusternamen ersetzen, den Sie verwendet haben: https://servername.azurehdinsight.net/das/
Verwenden Sie für die Anmeldung den Benutzernamen „Administrator“ und das Kennwort, das Sie festgelegt haben.
Wenn ein Fehler auftritt, rufen Sie die Registerkarte „Übersicht“ des Clusters im Azure-Portal auf, und stellen Sie sicher, dass der Status Wird ausgeführt angezeigt wird und dass der Clustertyp und die HDI-Version auf Interactive Query 3.1 (HDI 4.0) festgelegt sind.
- Daraufhin wird Data Studio Analytics im Browser gestartet.
- Klicken Sie im linken Menü auf „Database“ (Datenbank), klicken Sie dann auf die Schaltfläche mit drei Punkten, und klicken Sie anschließend auf Create Database (Datenbank erstellen).
Geben Sie der Datenbank den Namen „newyorkrealestate“, und klicken Sie dann auf Erstellen.
Klicken Sie im Datenbank-Explorer auf das Datenbanknamensfeld, und wählen Sie die Datenbank newyorkrealestate aus.
- Klicken Sie im Datenbank-Explorer auf + und dann auf Tabelle erstellen.
- Geben Sie der neuen Tabelle den Namen „propertysales“, und klicken Sie dann auf Upload table (Tabelle hochladen). Tabellennamen dürfen nur Kleinbuchstaben und Zahlen enthalten. Sonderzeichen sind unzulässig.
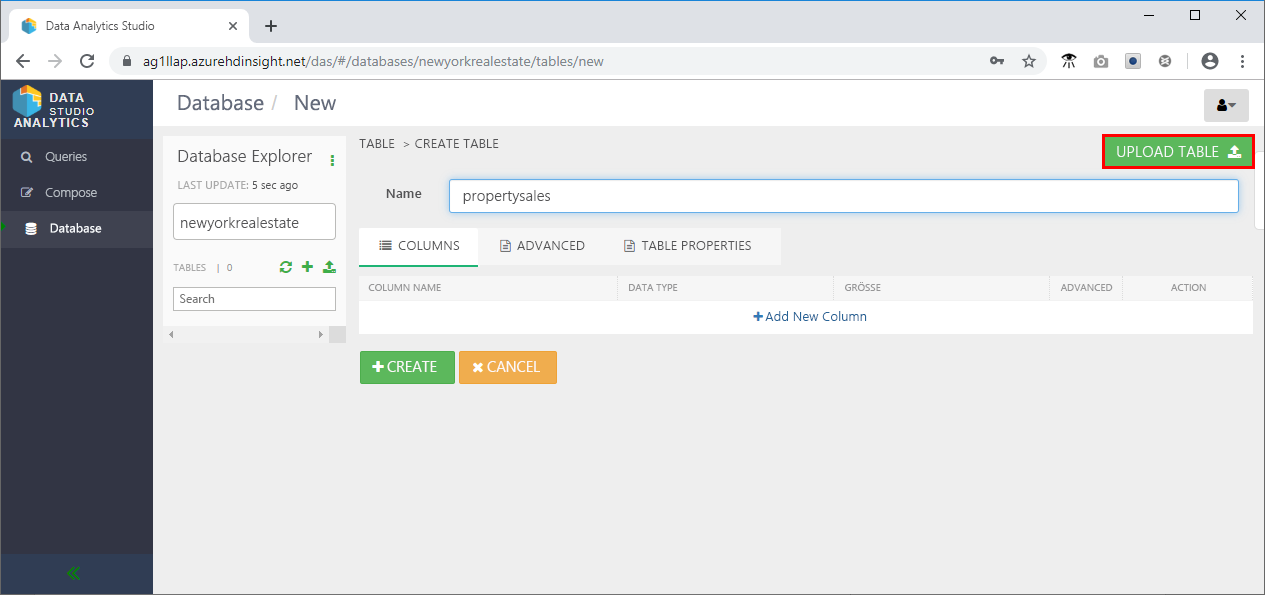
- Gehen Sie im Bereich „Select File Format“ (Dateiformat auswählen) der Seite wie folgt vor:
- Stellen Sie sicher, dass das CSV-Dateiformat festgelegt ist.
- Überprüfen Sie das Feld Is first row header? (Ist die erste Zeile die Kopfzeile?).
- Gehen Sie im Bereich „Select File Source“ (Dateiquelle auswählen) der Seite wie folgt vor:
- Klicken Sie auf Upload from Local (Aus lokalem Dateisystem hochladen).
- Klicken Sie auf Drag file to upload or click browse (Hochzuladende Datei ablegen oder zum Durchsuchen klicken), und navigieren Sie zur Datei „propertysales.csv“.
- Ändern Sie im Abschnitt „Columns“ (Spalten) den Datentyp von „Latitude“ und „Longitude“ (Breitengrad und Längengrad) in String (Zeichenfolge) und den Datentyp von „Sale date“ (Verkaufsdatum) in Date (Datum).

- Scrollen Sie nach oben, und überprüfen Sie im Abschnitt Table Preview (Tabellenvorschau), ob die Spaltenüberschriften richtig sind.
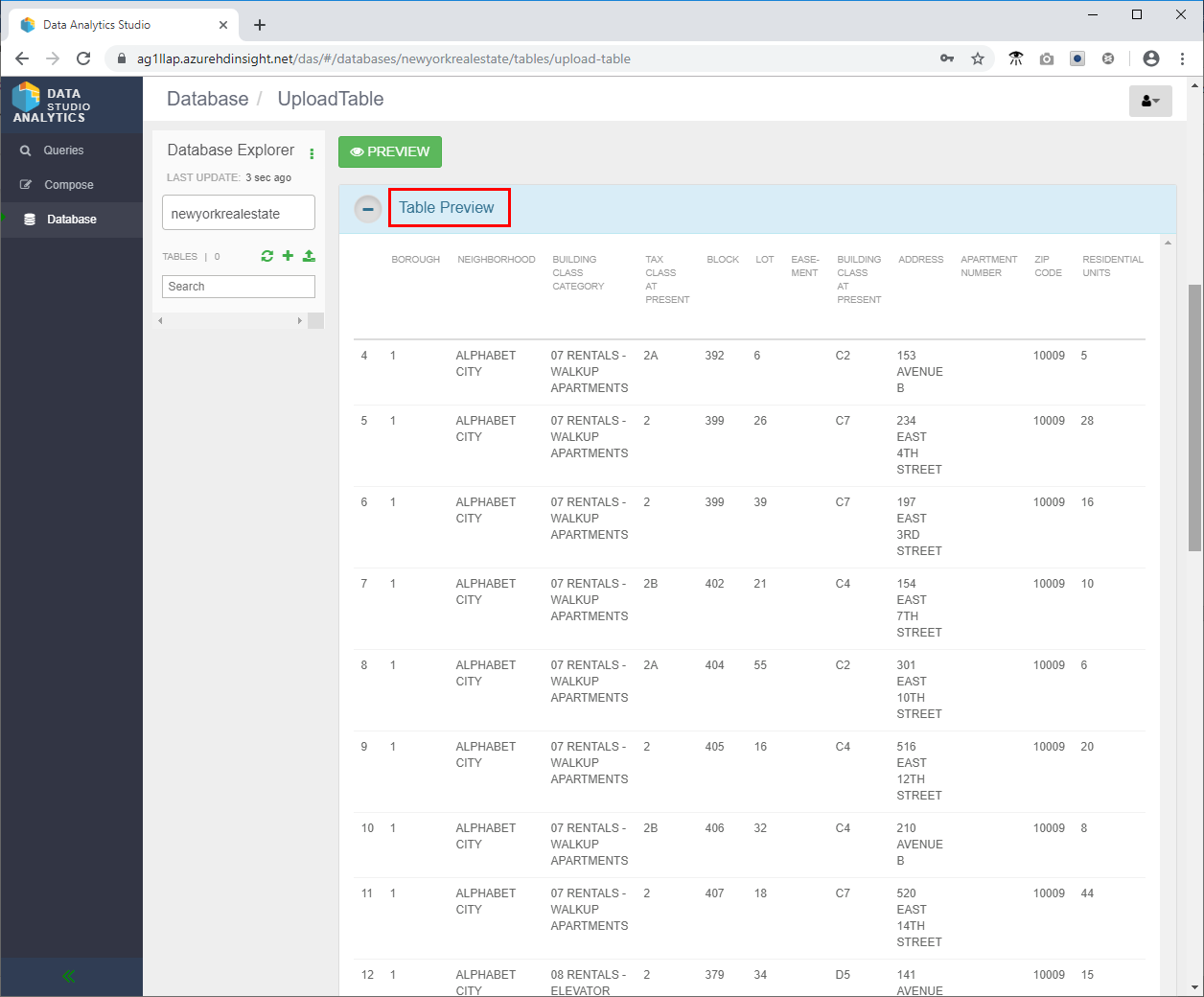
- Scrollen Sie nach ganz unten, und klicken Sie auf Create (Erstellen), um die Hive-Tabelle in der Datenbank „newyorkrealestate“ zu erstellen.

- Klicken Sie im linken Menü auf Compose (Zusammenstellen).
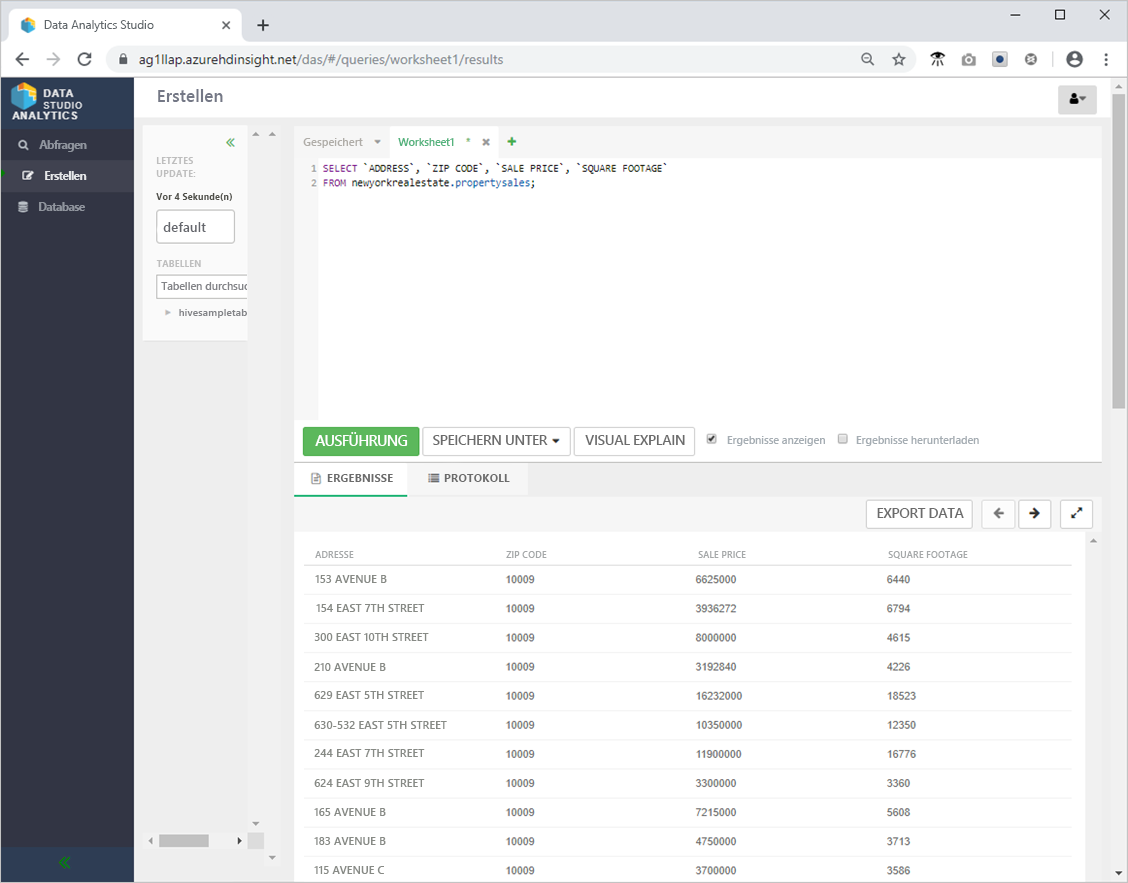
- Führen Sie die folgende Hive-Abfrage aus, um sicherzustellen, dass alles erwartungsgemäß funktioniert.
SELECT `ADDRESS`, `ZIP CODE`, `SALE PRICE`, `SQUARE FOOTAGE`
FROM newyorkrealestate.propertysales;
- Die Ausgabe sollte in etwa wie folgt aussehen:
- Überprüfen Sie die Leistung Ihrer Abfrage, indem Sie im linken Menü auf „Queries“ (Abfragen) klicken und dann die soeben ausgeführte Abfrage „SELECT
ADDRESS,ZIP CODE,SALE PRICE,SQUARE FOOTAGEFROM newyorkrealestate.propertysales“ auswählen.
Wenn Leistungsempfehlungen verfügbar sind, werden diese vom Tool angezeigt. Auf dieser Seite wird auch die tatsächlich ausgeführte SQL-Abfrage angezeigt, eine visuelle Erläuterung der Abfrage bereitgestellt, die bei der Ausführung von Hive abgeleiteten Konfigurationsdetails sowie eine Zeitachse werden angezeigt, die zeigt, wie viel Zeit mit der Ausführung jedes Teils der Abfrage verbracht wurde.
Untersuchen von Hive-Tabellen mit Zeppelin-Notebooks
- Klicken Sie im Azure-Portal auf der Übersichtsseite im Feld Clusterdashboard auf Zeppelin Notebook.

- Klicken Sie auf Neue Notiz, nennen Sie diese „Real Estate Data“ (Immobiliendaten), und klicken Sie auf Erstellen.
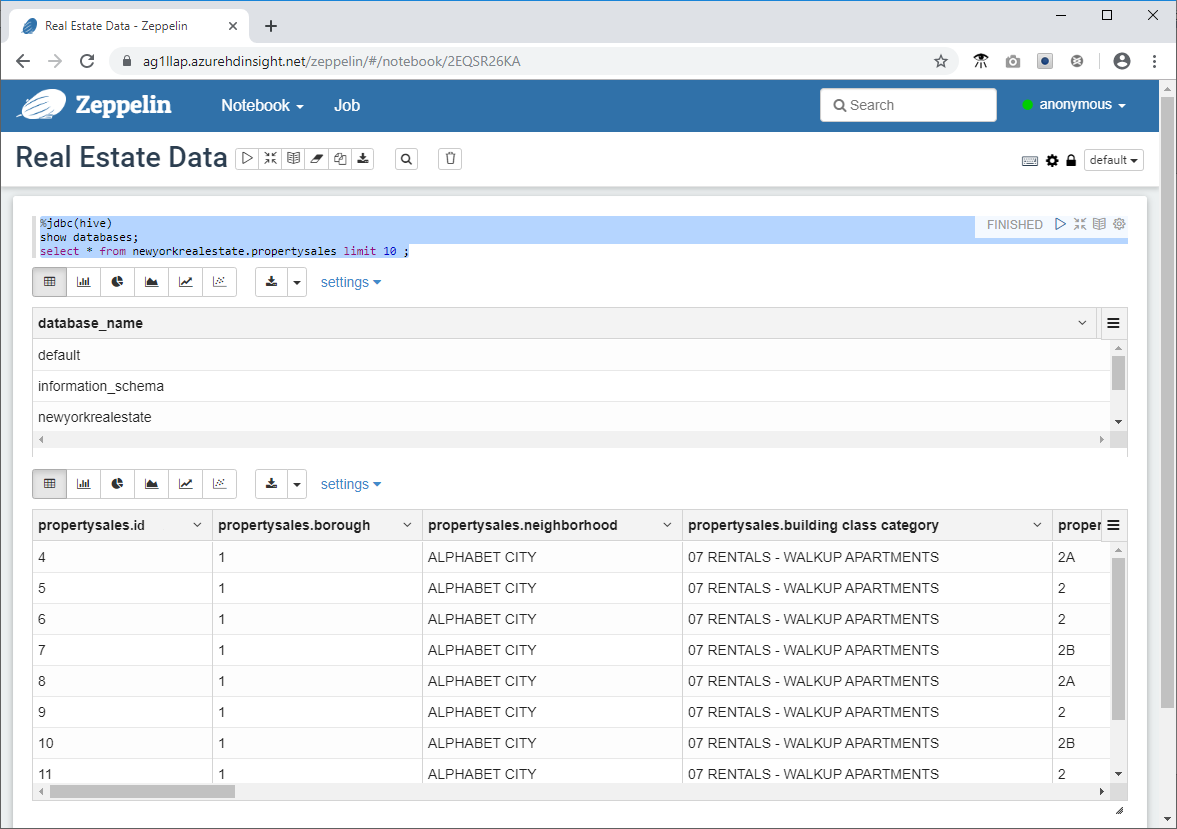
- Fügen Sie den folgenden Codeausschnitt in die Eingabeaufforderung im Zeppelin-Fenster ein, und klicken Sie auf das Wiedergabesymbol.
%jdbc(hive)
show databases;
select * from newyorkrealestate.propertysales limit 10 ;
Daraufhin wird die Ausgabe der Abfrage im Fenster angezeigt. Sie sollten sehen, dass die ersten 10 Ergebnisse zurückgegeben werden.
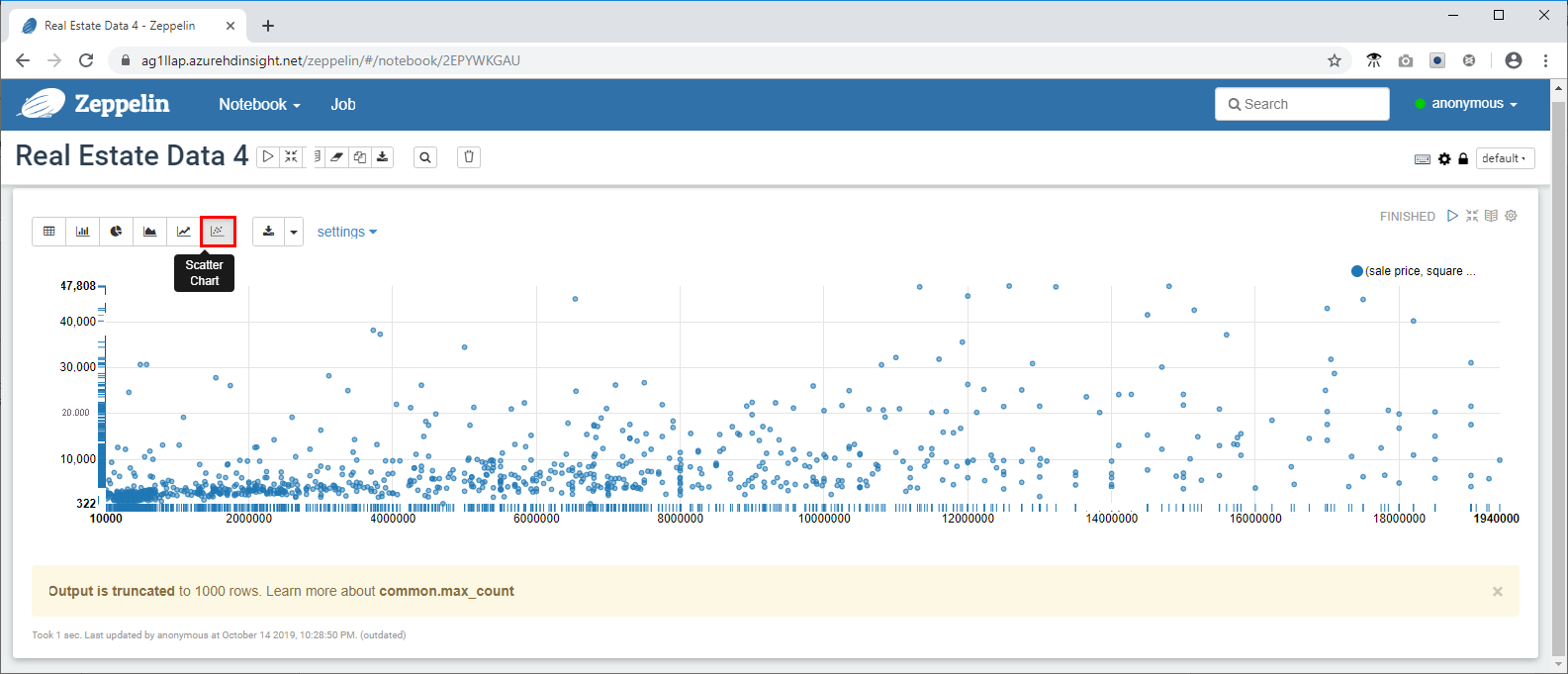
- Führen Sie als Nächstes eine komplexere Abfrage aus, um einige der in Zeppelin verfügbaren Visualisierungs- und Diagrammfunktionen zu verwenden. Kopieren Sie die folgende Abfrage in die Eingabeaufforderung, und klicken Sie auf .
%jdbc(hive)
select `sale price`, `square footage` from newyorkrealestate.propertysales
where `sale price` < 20000000 AND `square footage` < 50000;
Die Abfrageausgabe wird standardmäßig im Tabellenformat angezeigt. Wählen Sie stattdessen die Option „Punktdiagramm“ aus, um eines der Visuals anzuzeigen, die von Zeppelin-Notebooks bereitgestellt werden.