Interaktive HDInsight-Abfragen
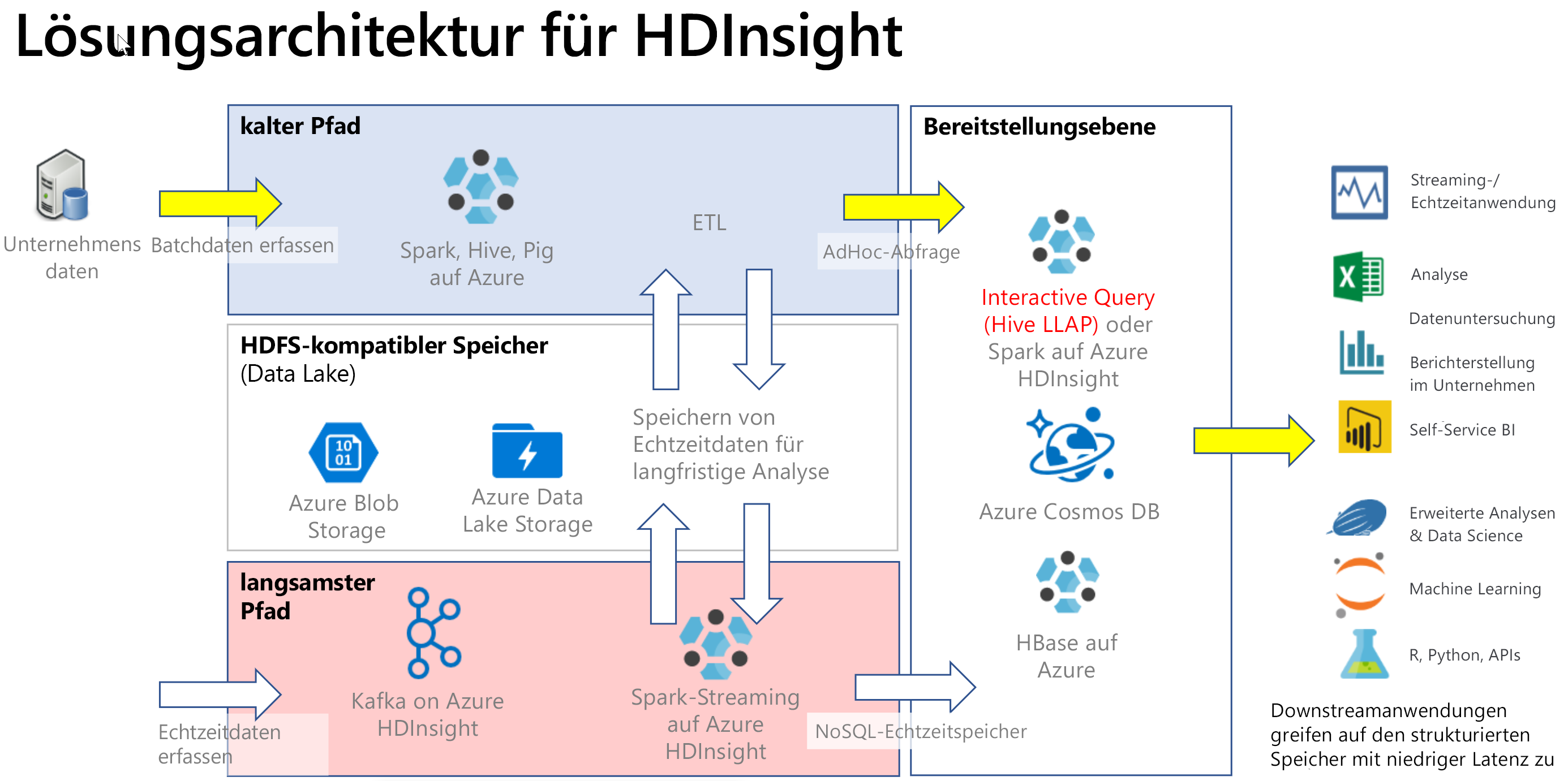
Interaktive Abfragen werden in der Regel in einem Szenario mit einem kalten Pfad implementiert, bei dem Sie über Daten im Tabellenformat verfügen und Fragen stellen, um schnell eine interaktive Antwort mithilfe einer SQL-Syntax zu erhalten. Im folgenden Diagramm wird die Lösungsarchitektur für alle HDInsight-Lösungen mit kaltem oder heißem Pfad veranschaulicht und hervorgehoben, wie interaktive Abfragen über Hive LLAP in der Bereitstellungsebene verarbeitet werden. Daten können per Hive eingespeist werden, interaktive Abfragen werden über Hive LLAP verarbeitet, und die Ausgabe kann für Downstreamanwendungen wie Power BI bereitgestellt werden.
Architektur von Interactive Query
Als Nächstes wird die Interactive Query-Architektur erläutert.
Interactive Query-Benutzer verfügen über eine umfassende Auswahl von ODBC- oder JDBC-Clients zum Ausführen von Abfragen ihrer Geschäftsdaten, z. B. Data Analytics Studio, Zeppelin-Notebooks und Visual Studio Code. Nachdem ein Client eine HiveQL-Abfrage übermittelt hat, wird diese vom Hive-Server empfangen, der für die Abfrageplanung, die Abfrageoptimierung und die Sicherheitskürzung zuständig ist. Hive teilt die Analyseaufgaben auf verteilte Knoten im Cluster auf. Abfragen werden in untergeordnete Aufgaben unterteilt und an Knoten gesendet, die jede untergeordnete Aufgabe verarbeiten. Diese untergeordneten Aufgaben werden weiter unterteilt, und jede dieser Aufgaben liest Daten aus der zugrunde liegenden Speicherebene für Geschäftsdaten. Die Architektur gilt aufgrund der Verwendung von Always-On-LLAP-Daemons, mit denen Startzeiten vermieden werden, und aufgrund des freigegebenen In-Memory-Caches als optimiert, in dem Daten gespeichert werden, die aus dem Speicher abgerufen wurden, und dieser gibt die Daten für alle Knoten frei.
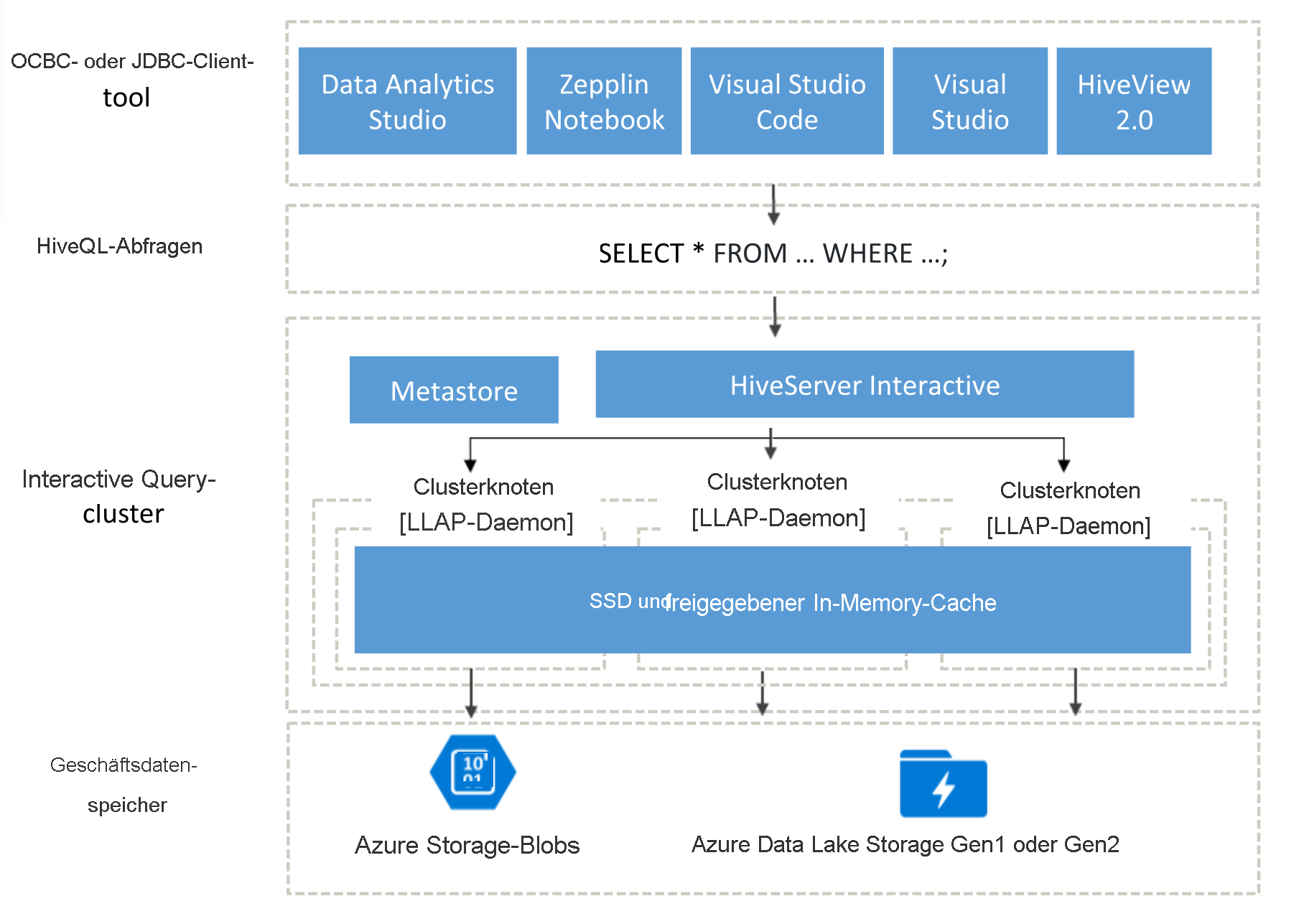
Die von Interactive Query-Clustern verwendeten SSDs (Solid State Drive) kombinieren RAM und SSD in einem riesigen Arbeitsspeicherpool, der vom Cache verwendet wird. Mit dieser Ressourcenkombination kann ein herkömmliches Serverprofil die vierfache Menge an Daten zwischenspeichern, sodass Sie größere Datasets verarbeiten und mehr Benutzer unterstützen können. Der Interactive Query-Cache beachtet die Änderungen an den zugrunde liegenden Daten im Remotespeicher (Azure Storage). Wenn die zugrunde liegenden Daten geändert werden und Benutzer eine Abfrage ausgeben, werden die geänderten Daten daher in den Arbeitsspeicher geladen, ohne dass der Benutzer weitere Schritte ausführen muss.