Anwendungsfälle für HDInsight Interactive Query
Als Business Analyst müssen Sie den besten HDInsight-Cluster zum Erstellen Ihrer Lösung ermitteln. Interactive Query-Cluster stellen eine Vielzahl von Features und Interoperabilitätsoptionen bereit, die einzigartige Vorteile für Business Analysts bieten, die mit SQL vertraut sind. Sie eignen sich bestens für Benutzer, die mit Business Intelligence-Tools arbeiten möchten und schnelle interaktive Abfragen benötigen. Außerdem gibt es weitere Vorteile wie die Unterstützung einer Vielzahl von Dateiformaten, Parallelität und ACID-Transaktionen (Atomarität, Konsistenz, Isolation und Dauerhaftigkeit). Darüber hinaus umfassen die Cluster die Integration mit Apache Range für präzise Kontrolle auf Zeilen- und Spaltenebene über die Daten.
Hinweis
Der Inhalt dieses Moduls bezieht sich auf Interactive Query-Cluster, die für HDInsight 4.0 erstellt wurden. Dieser Dienst verwendet Hive 3.1 und LLAP, auch bekannt als Hive LLAP.
Sie verfügen über ein für Abfragen bereites großes Dataset
Interactive Query-Cluster eignen sich am besten für große Datasets, die unverändert oder mit minimalen Transformationen abgefragt werden können. Dabei handelt es sich um Situationen, in denen Sie eine Vielzahl von Abfragen für die Daten ausführen und sofortige Antworten benötigen. Interactive Query-Cluster sind nicht für die Ausführung von Batchberechnungen mit langer Ausführungszeit optimiert. Interactive Query unterstützt die folgenden Dateiformate: ORC, Parquet, CSV, Avro, JSON, Text und TSV.
Sie benötigen SQL-ähnliche Funktionen
Wenn Sie interaktive und Ad-hoc-Abfragen mit Wartezeiten unter einer Sekunde für Big Data in Azure Storage und Azure Data Lake Storage durchführen müssen und eine Funktionsweise bevorzugen, die der Funktionsweise von SQL ähnelt, sind Interactive Query-Cluster von Azure HDInsight eine hervorragende Wahl. Als Business Analyst sind Sie mit SQL-Tabellen und der Erstellung von Abfragen mit SQL vertraut. Apache Hadoop ist ein leistungsfähiges Tool zum Ausführen von Big Data-Analysen. Die Verwendung des MapReduce-Frameworks und der Java-APIs durch Apache Hadoop kann sich für Sie als Hindernis erweisen, wenn Ihre Java-Programmierkenntnisse etwas eingerostet sind. In diesem Fall stellt Interactive Query von HDInsight die bessere Option dar, da diese Option auf Apache Hadoop basiert, aber für jeden Benutzer mit SQL-Kenntnissen einfacher zu verwenden ist. Interactive Query verwendet SQL-ähnliche Hive-Tabellen zum Verarbeiten von Daten sowie eine SQL-ähnliche Abfragesprache namens HiveQL zum Abfragen von Daten. Die Verwendung von Hive ist weniger komplex als das Verarbeiten von Daten mit MapReduce in Apache Hadoop. Mit Hive wird die Bereitstellung von Lösungen für Ihr Unternehmen beschleunigt und effizienter.
Schnelle interaktive Abfragen mit intelligentem Caching
Interactive Query-Cluster verwenden intelligente Cachingverfahren, um die Daten auf dynamischem RAM, auf der SSD des lokalen Clusterknotens und auf Remotespeichersystemen wie Azure Blob und Azure Data Lake Storage zu staffeln, wodurch interaktive und schnelle Abfrageergebnisse für Big Data erzielt werden. Ein gutes Beispiel für fortschrittliche Cachingverfahren ist der dynamische Textcache, der CSV-Daten dynamisch in ein optimiertes In-Memory-Format konvertiert. Dadurch erfolgt das Caching auf dynamische Weise und die Abfragen bestimmen, welche Daten zwischengespeichert werden. Diese Funktionalität bedeutet, dass Sie Ihre Daten nicht zuerst laden und transformieren müssen. Sie können die Daten im ursprünglichen Format auf Azure Storage hochladen und damit beginnen, diese abzufragen. Das bedeutet auch, dass Abfragen bei der zweiten Durchführung leistungsfähiger sind. Bei der ersten Ausführung einer Abfrage werden die Daten aus der Speicherebene für Geschäftsdaten in Azure Storage oder Azure Data Lake Gen2 gelesen. Anschließend werden die Daten im freigegebenen In-Memory-Cache des Clusters zwischengespeichert. Bei der nächsten Ausführung der Abfrage werden die Daten lediglich aus dem freigegebenen In-Memory-Cache abgerufen, sodass Sie Zeit sparen, da die Daten nicht aus der Remotespeicherebene abgerufen werden.
Ausführen von Abfragen mithilfe beliebter Tools
Interactive Query vereinfacht die Arbeit mit Big Data mithilfe von BI-Tools, die Ihnen bereits vertraut sind, z. B. Microsoft Power BI und Tableau. Unter Organisationen steigen die Bedenken bezüglich Big Data-Analysen, dass ihre Endbenutzer nicht ausreichend Nutzen aus den Analysesystemen gewinnen, da dies häufig zu schwierig ist und die Ausführung der Analysen die Verwendung fremder und komplexer Tools erfordert. Interactive Query von HDInsight löst dieses Problem, da nur minimale oder keine weiteren Schulungen für Benutzer erforderlich sind, damit Erkenntnisse aus den Daten gewonnen werden können. Benutzer können HiveQL-Abfragen, die SQL ähneln, in den Tools schreiben, die sie bereits verwenden. Zu diesen Tools gehören Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio und Hive ODBC. Mit der Hive-Konsole, mit Templeton, der klassischen Azure CLI oder mit Azure PowerShell können Sie keine Abfragen für Ihren Interactive Query-Cluster durchführen.
Sie benötigen Transaktionskonsistenz und Parallelität
Mit der Einführung einer präzisen Ressourcenverwaltung sowie der Vorwegnahme und Freigabe zwischengespeicherte Daten für Abfragen und Benutzer, unterstützt Interactive Query gleichzeitige Benutzer problemlos. HDInsight unterstützt das Erstellen mehrerer Cluster im freigegebenen Azure-Speicher. Hive-Metastore trägt dazu bei, einen hohen Parallelitätsgrad zu erzielen. Sie können die Parallelität skalieren, indem Sie mehr Clusterknoten hinzufügen oder mehr Cluster hinzufügen, die auf dieselben zugrunde liegenden Daten und Metadaten verweisen. Interactive Query unterstützt auch Datenbanktransaktionen, die atomar, konsistent, isoliert und dauerhaft (ACID) sind. ACID-Transaktionen garantieren, dass eine Transaktion in einer einzelnen Einheit enthalten ist, selbst wenn diese mehrere Vorgänge enthält. Wenn ein einzelner Vorgang in der Transaktion fehlschlägt, kann daher ein Rollback für den gesamten Vorgang durchgeführt werden, wodurch die Daten konsistent und korrekt gehalten werden.
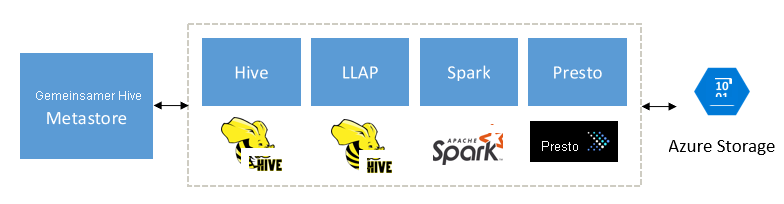
Interactive Query komplementiert Spark, Hive, Presto und andere Big Data-Engines
Interactive Query von HDInsight ist für die Funktionalität mit beliebten Big Data-Engines konzipiert, z. B. Apache Spark, Hive, Presto und mehr. Diese Art von Abfragen ist insbesondere hilfreich, da Ihre Benutzer möglicherweise eines dieser Tools verwenden, um ihre Analysen durchzuführen. Mit der Architektur für externe Tabellen für freigegebene Daten und Metadaten von HDInsight können Benutzer mehrere Cluster mit derselben oder einer anderen Engine erstellen, die auf dieselben zugrunde liegenden Daten und Metadaten verweisen. Diese Funktionalität ist ein leistungsfähiges Konzept, da Sie nicht mehr an eine Technologie für die Analyse gebunden sind.