Replizieren von Daten in einem sekundären Cluster
Kafka wird aufgrund der Notfallwiederherstellung, der Hochverfügbarkeit und von Hybridszenarios mit lokalen Ressourcen und Cloudressourcen häufig in mehreren Umgebungen bereitgestellt. In diesen Szenarios müssen die Daten mithilfe des Spiegelungsfeatures von Apache Kafka von einer Kafka-Instanz in einer anderen repliziert werden. Die Spiegelung kann als fortlaufend oder in Abständen ausgeführt werden. Letzteres eignet sich für die Migration von Daten aus einem Cluster in einen anderen.
Die Spiegelung sollte nicht als Mittel zum Erzielen von Fehlertoleranz angesehen werden. Der Versatz von Elementen in einem Thema unterscheidet sich im primären und sekundären Cluster, sodass die Cluster für Clients nicht austauschbar sind.
Wie funktioniert die Spiegelung?
Für die Spiegelung wird das Tool MirrorMaker (Teil von Apache Kafka) verwendet, um Datensätze aus Themen im primären Cluster zu nutzen und anschließend eine lokale Kopie im sekundären Cluster zu erstellen. MirrorMaker nutzt mindestens einen Consumer, um Daten aus dem primären Cluster zu lesen, und einen Producer, der in den lokalen sekundären Cluster schreibt.
Am sinnvollsten ist es, die Spiegelung für die Notfallwiederherstellung mit Kafka-Clustern in verschiedenen Azure-Regionen einzurichten. Zu diesem Zweck werden die virtuellen Netzwerke, in denen sich die Cluster befinden, zu einem Peeringnetzwerk zusammengeschlossen.
Das folgende Diagramm veranschaulicht den Spiegelungsprozess und den Kommunikationsfluss zwischen den Clustern:
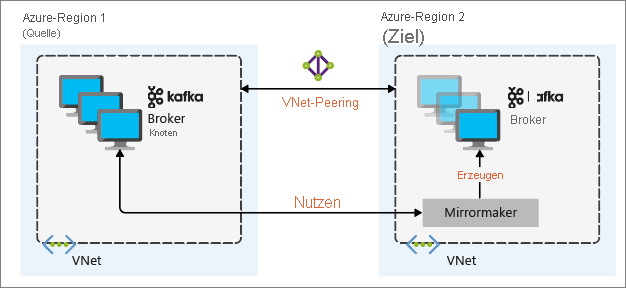
Der primäre und der sekundäre Cluster können sich in Bezug auf die Anzahl von Knoten und Partitionen unterscheiden, und auch der Versatz in den Themen ist unterschiedlich. Beim Spiegeln wird der Schlüsselwert beibehalten, der für die Partitionierung verwendet wird, sodass die Datensatzreihenfolge pro Schlüssel beibehalten wird.
Spiegelung über Netzwerkgrenzen hinweg
Wenn Sie eine Spiegelung zwischen Kafka-Clustern in unterschiedlichen Netzwerken durchführen müssen, sollten Sie außerdem Folgendes beachten:
- Gateways: Die Netzwerke müssen auf TCP/IP-Ebene kommunizieren können.
- Serveradresse: Sie können die IP-Adressen oder die vollqualifizierten Domänennamen verwenden, um Ihre Clusterknoten zu erreichen.
- IP-Adressen: Wenn Sie Ihre Kafka-Cluster für die Ankündigung der IP-Adresse konfigurieren, können Sie die Spiegelung mit den IP-Adressen der Brokerknoten und der Zookeeperknoten einrichten.
- Domänennamen: Wenn Sie Ihre Kafka-Cluster nicht für die Ankündigung der IP-Adresse konfigurieren, müssen die Cluster über ihre vollqualifizierten Domänennamen eine Verbindung miteinander herstellen können. Hierfür ist ein DNS-Server (Domain Name System) in jedem Netzwerk erforderlich, der dafür konfiguriert ist, Anforderungen an die anderen Netzwerke weiterzuleiten. Beim Erstellen eines virtuellen Azure-Netzwerks müssen Sie einen benutzerdefinierten DNS-Server und die IP-Adresse für den Server angeben, anstatt das automatisch bereitgestellte DNS des Netzwerks zu verwenden. Nach der Erstellung des virtuellen Netzwerks müssen Sie dann einen virtuellen Azure-Computer erstellen, für den diese IP-Adresse verwendet wird, und anschließend die DNS-Software darauf installieren und konfigurieren.
Warnung
Erstellen und konfigurieren Sie den benutzerdefinierten DNS-Server, bevor Sie HDInsight im virtuellen Netzwerk installieren. Es ist keine zusätzliche Konfiguration erforderlich, damit HDInsight den für das virtuelle Netzwerk konfigurierten DNS-Server verwenden kann.