Spark Structured Streaming
Spark Structured Streaming ist eine beliebte Plattform für die arbeitsspeicherinterne Verarbeitung. Es verfügt über ein einheitliches Paradigma für die Batch- und die Streamingverarbeitung. Alles, was Sie zur Batchverarbeitung lernen und verwenden, können Sie für auch für die Streamingverarbeitung nutzen. Dies macht den Umstieg von der Batch- auf die Streamingverarbeitung Ihrer Daten so einfach. Spark-Streaming ist eine einfache Engine, die auf Apache Spark ausgeführt wird.
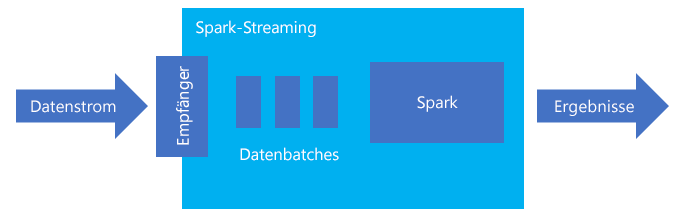
In Structured Streaming wird eine Abfrage mit langer Ausführungszeit erstellt, während der Vorgänge wie die Auswahl, die Projektion, die Aggregation, das Windowing und die Verknüpfung des streamenden mit dem referenzierten DataFrame auf die Eingabedaten angewendet werden. Als Nächstes geben Sie die Ergebnisse mithilfe von benutzerdefiniertem Code an den Dateispeicher (Azure Storage Blob-Instanzen oder Data Lake Storage) oder einen beliebigen Datenspeicher (z.B. SQL-Datenbank oder Power BI) aus. Structured Streaming stellt auch die Ausgabe an die Konsole für lokales Debuggen und ebenso für eine In-Memory-Tabelle bereit, damit Sie die für das Debuggen generierten Daten in HDInsight sehen können.
Streams als Tabellen
Spark Structured Streaming stellt einen Datenstrom als Tabelle mit unbegrenzter Tiefe dar, d. h., dass die Tabelle durch empfangene Daten kontinuierlich wächst. Diese Eingabetabelle wird durch eine Abfrage mit langer Ausführungszeit kontinuierlich verarbeitet, und die Ergebnisse werden an eine Ausgabetabelle gesendet:

In Structured Streaming werden die im System eingehenden Daten sofort in einer Eingabetabelle erfasst. Sie schreiben Abfragen (mit Datenrahmen- und Dataset-API), mit denen Vorgänge für diese Eingabetabelle ausgeführt werden. Die Abfrageausgabe ergibt eine weitere Tabelle, die Ergebnistabelle. Die Ergebnistabelle enthält die Ergebnisse Ihrer Abfrage, aus denen Sie Daten für einen externen Datenspeicher, z.B. eine relationale Datenbank, beziehen. Wann Daten aus der Eingabetabelle verarbeitet werden, wird durch das Triggerintervall gesteuert. Standardmäßig ist das Triggerintervall null (0), also versucht Structured Streaming, die Daten sofort bei Eintreffen zu verarbeiten. In der Praxis bedeutet dies, dass Structured Streaming sofort nach Verarbeitung einer Abfrage mit einer weiteren Verarbeitung neu empfangener Daten beginnt. Sie können den Trigger zur Ausführung in einem Intervall konfigurieren, sodass die Streamingdaten in zeitbasierten Batches verarbeitet werden.
In den Ergebnistabellen sind unter Umständen nur die Daten enthalten, die seit der letzten Verarbeitung der Abfrage neu hinzugekommen sind (Anfügemodus). Stattdessen kann die Tabelle bei jedem Eingang neuer Daten aktualisiert werden, sodass die Tabelle alle Ausgabedaten seit Beginn der Streamingabfrage enthält (vollständiger Modus).
Anfügemodus
Im Anfügemodus sind nur die Zeilen, die seit der letzten Abfrageausführung der Ergebnistabelle hinzugefügt wurden, in der Ergebnistabelle vorhanden, und nur sie werden in den externen Speicher geschrieben. Die einfachste Abfrage kopiert beispielsweise alle Daten unverändert aus der Eingabe- in die Ergebnistabelle. Jedes Mal, wenn ein Triggerintervall abläuft, werden die neuen Daten verarbeitet, und die Zeilen, die diese neuen Daten darstellen, werden in der Ergebnistabelle angezeigt.
Stellen Sie sich ein Szenario vor, in dem Sie Daten zu Aktienkursen verarbeiten. Angenommen, der erste Trigger zum Zeitpunkt 00:01 verarbeitet ein Ereignis für MSFT-Aktien zu einem Wert von 95 US-Dollar. Im ersten Abfragetrigger wird nur die Zeile mit dem Zeitpunkt 00:01 in der Ergebnistabelle angezeigt. Für den Zeitpunkt 00:02, als ein weiteres Ereignis eingeht, ist die einzige neue Zeile die Zeile mit dem Zeitpunkt 00:02, sodass die Ergebnistabelle nur diese eine Zeile enthält.
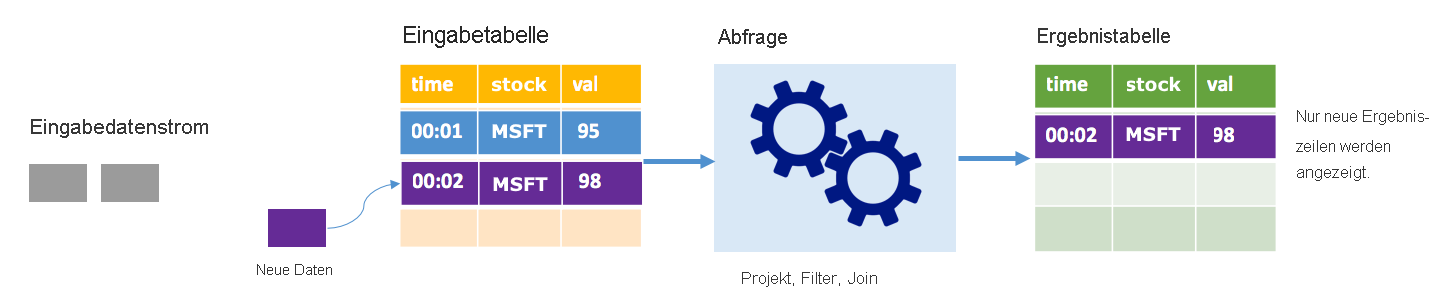
Bei Verwendung des Anfügemodus würde die Abfrage Projektionen anwenden (Auswählen der Spalten von Interesse), filtern (nur Auswählen der Zeilen, die bestimmten Bedingungen entsprechen) oder verknüpfen (die Daten mit Daten aus einer statischen Nachschlagetabelle erweitern). Im Anfügemodus können ganz unkompliziert nur die relevanten neuen Datenpunkte in den externen Speicher gepusht werden.
Vollständiger Modus
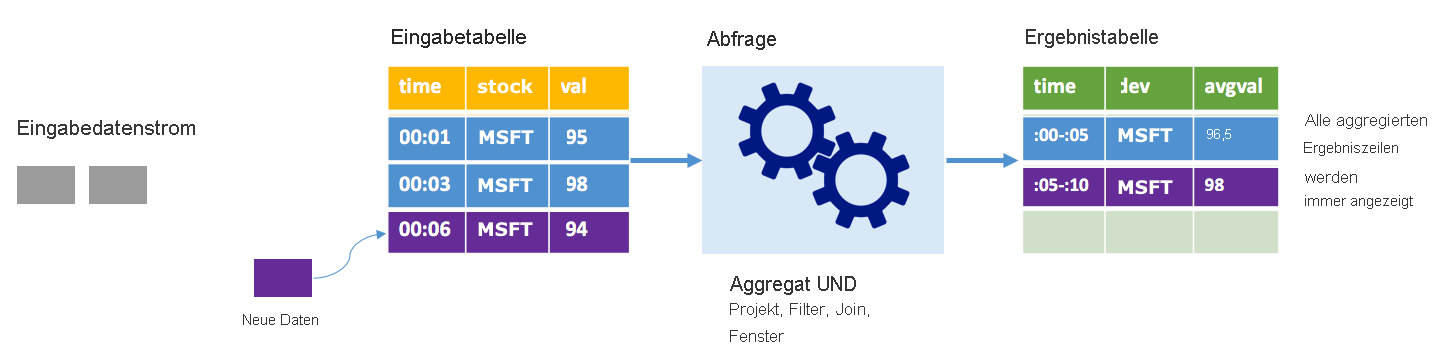
Stellen Sie sich das gleiche Szenario vor, dieses Mal jedoch im vollständigen Modus. Im vollständigen Modus wird die gesamte Ausgabetabelle bei jedem Trigger aktualisiert, sodass die Tabelle nicht nur Daten aus dem letzten Trigger enthält, sondern aus allen Ausführungen. Mit dem vollständigen Modus können Sie die Daten unverändert aus der Eingabe- in die Ergebnistabelle kopieren. Bei jeder ausgelösten Ausführung werden die neuen Ergebniszeilen zusammen mit allen vorherigen Zeilen angezeigt. In der Ausgabeergebnistabelle werden alle Daten gespeichert, die seit Beginn der Abfrage erfasst wurden, und der Arbeitsspeicher wird schließlich ausgehen. Der vollständige Modus dient zur Verwendung mit Aggregatabfragen, die die eingehenden Daten in irgendeiner Weise zusammenfassen, sodass bei jedem Trigger die Ergebnistabelle mit einer neuen Zusammenfassung aktualisiert wird.
Angenommen, dass die Daten der ersten fünf Sekunden bereits verarbeitet wurden und dass es an der Zeit ist, die Daten der sechsten Sekunde zu verarbeiten. Die Eingabetabelle enthält Ereignisse für die Zeitpunkte 00:01 und 00:03. Das Ziel dieser Beispielabfrage besteht darin, alle fünf Sekunden den durchschnittlichen Kurs einer Aktie auszugeben. Bei der Implementierung dieser Abfrage wird ein Aggregat angewendet, das alle Werte entgegennimmt, die innerhalb der einzelnen 5-Sekunden-Fenster liegen. Anschließend wird der durchschnittliche Kurs ermittelt und eine Zeile für den durchschnittlichen Kurs dieses Intervalls erzeugt. Am Ende des ersten 5-Sekunden-Fensters gibt es zwei Tupel: (00:01, 1, 95) und (00:03, 1, 98). Für das Fenster 00:00–00:05 erzeugt die Aggregation also ein Tupel mit dem durchschnittlichen Aktienkurs von 96,50 US-Dollar. Im folgenden 5-Sekunden-Fenster gibt es nur einen Datenpunkt bei 00:06, sodass der resultierende durchschnittliche Kurs 98 US-Dollar beträgt. Zum Zeitpunkt 00:10 enthält die Ergebnistabelle im vollständigen Modus die Zeilen für beide Intervalle (00:00-00:05 und 00:05 00:10), da die Abfrage alle aggregierten Zeilen ausgibt, nicht nur die neuen. Aus diesem Grund wächst die Ergebnistabelle weiter an, je mehr neue Fenster hinzugefügt werden.
Nicht alle Abfragen im vollständigen Modus bewirken, dass eine Tabelle unbegrenzt wächst. Angenommen, im vorherigen Beispiel wäre der durchschnittliche Kurs nicht pro Zeitfenster, sondern pro Aktie berechnet worden. Die Ergebnistabelle enthält eine festgelegte Anzahl von Zeilen (eine pro Aktie) mit dem durchschnittlichen Aktienkurs aller Aktien für alle Datenpunkte, die von diesem Gerät empfangen wurden. Wenn neue Aktienkurse empfangen werden, wird die Ergebnistabelle aktualisiert, sodass die Durchschnittswerte in der Tabelle immer auf dem neuesten Stand sind.
Welche Vorteile bietet Spark Structured Streaming?
Im Finanzsektor ist das Timing von Transaktionen alles. Bei einem Aktienhandel ist beispielsweise der Unterschied zwischen dem Zeitpunkt, zu dem das Aktiengeschäft auf dem Aktienmarkt abgeschlossen wurde, dem Zeitpunkt, an dem Sie die Transaktion erhalten, und dem Zeitpunkt, an dem die Daten gelesen werden, extrem relevant. Finanzinstitute sind abhängig von diesen kritischen Daten und ihrem Timing.
Ereigniszeitpunkt, späte Daten und Wasserzeichen
Spark Structured Streaming kennt den Unterschied zwischen einem Ereigniszeitpunkt und dem Zeitpunkt, an dem das Ereignis vom System verarbeitet wurde. Jedes Ereignis stellt eine Zeile in der Tabelle dar, und die Ereigniszeit ist einer der Spaltenwerte. So können fensterbasierte Aggregationen (z. B. die Anzahl von Ereignissen pro Minute) schlicht eine Gruppierung und Aggregation der Ereigniszeitspalte sein, da jedes Zeitfenster eine Gruppe ist und jede Zeile zu mehreren Fenstern/Gruppen gehören kann. Aus diesem Grund können solche auf dem Ereigniszeitfenster basierenden Aggregationsabfragen sowohl für ein statisches Dataset als auch für einen Datenstrom konsistent definiert werden, was Data Engineers die Arbeit erheblich erleichtert.
Darüber hinaus verarbeitet dieses Modell natürlich auch Daten, die später als erwartet eingehen, auf Grundlage der Ereigniszeit. Spark verfügt über vollständige Kontrolle über das Aktualisieren (im Fall von späten Daten) und das Bereinigen alter Aggregate (zum Einschränken der Größe von zwischenzeitlichen Zustandsdaten). Seit Spark 2.1 werden außerdem Wasserzeichen unterstützt. Damit können Sie den Schwellenwert für späte Daten festlegen, und die Engine kann den alten Zustand entsprechend bereinigen.
Flexibilität beim Hochladen der aktuellen oder aller Daten
Wie in der vorherigen Lerneinheit erläutert, können Sie in Spark Structured Streaming zwischen dem Anfügemodus und dem vollständigen Modus wählen, damit Ihre Ergebnistabelle nur die neuesten oder alle Daten enthält.
Unterstützung des Wechsels von Mikrobatches zur fortlaufenden Verarbeitung
Durch Ändern des Triggertyps einer Spark-Abfrage können Sie von der Mikrobatchverarbeitung zur kontinuierlichen Verarbeitung wechseln, ohne weitere Änderungen an Ihrem Framework vorzunehmen. Nachstehend finden Sie die verschiedenen Trigger, die von Spark unterstützt werden.
- Nicht angegeben, Standardeinstellung: Wenn kein Trigger explizit festgelegt wird, wird die Abfrage in Mikrobatches ausgeführt und kontinuierlich verarbeitet.
- Mikrobatches mit festgelegten Intervallen: Die Abfrage wird in wiederkehrenden, vom Benutzer festgelegten Intervallen ausgeführt. Wenn keine neuen Daten empfangen werden, wird kein Mikrobatchprozess ausgeführt.
- Einmalige Mikrobatches: Die Abfrage führt einen einzelnen Mikrobatch aus und wird dann beendet. Dieser Trigger eignet sich, wenn alle Daten seit dem vorherigen Mikrobatch verarbeitet werden sollen. Außerdem kann er bei Aufträgen, die nicht fortlaufend ausgeführt werden müssen, zu Kosteneinsparungen führen.
- Fortlaufend mit einem festgelegten Prüfpunktintervall: Die Abfrage wird in einem neuen fortlaufenden Verarbeitungsmodus mit niedriger Latenz ausgeführt, der eine niedrige End-to-End-Latenz (ca. 1 ms) mit At-least-once-Fehlertoleranzgarantien bietet. Dies ist vergleichbar mit der Standardeinstellung, die zwar Exactly-once-Garantien erzielen kann, dafür jedoch nur Latenzen von etwa 100 ms.
Kombinieren von Batch- und Streamingaufträgen
Die Umstellung von Batch- auf Streamingaufträge kann nicht nur vereinfacht werden – Batch- und Streamingaufträge lassen sich auch kombinieren. Dies ist besonders hilfreich, wenn Sie mithilfe langfristiger historischer Daten zukünftige Trends vorhersagen und gleichzeitig Echtzeitinformationen verarbeiten möchten. Bei Aktien sollten Sie sich den Kursverlauf der letzten fünf Jahre sowie den aktuellen Kurs ansehen, um Änderungen an den jährlichen oder vierteljährlichen Gewinnprognosen vorherzusagen.
Ereigniszeitfenster
Daten sollten in Zeitfenstern erfasst werden, z. B. ein hoher Aktienkurs und ein niedriger Kurs in einem Ein-Tages- oder Ein-Minuten-Fenster. Spark Structured Streaming unterstützt, dass Sie die Fenstergröße selbst festlegen. Überlappende Fenster werden ebenfalls unterstützt.
Prüfpunkterstellung für die Fehlerwiederherstellung
Im Falle eines Fehlers oder beabsichtigten Herunterfahrens können Sie den Fortschritt und Zustand einer vorherigen Abfrage wiederherstellen und den Vorgang an dem Punkt fortsetzen, an dem er beendet wurde. Dies erfolgt mithilfe der Prüfpunkterstellung und über Write-Ahead-Protokolle. Abfragen können mit einem Prüfpunktspeicherort konfiguriert werden. Dies bewirkt, dass Abfragen alle Statusinformationen (d. h. den Bereich der in den einzelnen Triggern verarbeiteten Offsets) sowie die aktuell ausgeführten Aggregate im Prüfpunktspeicherort speichern. Dieser Prüfpunktspeicherort muss ein Pfad in einem HDFS-kompatiblen Dateisystem sein und kann beim Start einer Abfrage als Option in DataStreamWriter festgelegt werden.