Streamen von Daten mit Apache Kafka
Apache Kafka wurde 2010 von LinkedIn mit dem Ziel geschaffen, Daten mit einer hohen Fehlertoleranz und sehr geringen Latenz zu verschieben. 2012 spendete LinkedIn das Projekt zwar an die Apache Foundation, verwendet Kafka jedoch weiterhin im gesamten Ökosystem, um Benutzeraktivitäten nachzuverfolgen, Nachrichten auszutauschen und Metriken zu erfassen.
Kafka ist eine verteilte Streamingplattform, die für folgende Zwecke entworfen wurde:
- Vereinfachen von Datenpipelines
- Verarbeiten großer Datenmengen in einem Streamingmuster
- Unterstützung von Echtzeit- und Batchsystemen
- Horizontales Skalieren im großen Stil
Zunächst wird näher auf Apache Kafka an sich, dann auf Kafka in Azure HDInsight eingegangen.
Kafka-Komponenten
Bevor auf die Funktionsweise von Kafka eingegangen wird, werden einige der wichtigsten Komponenten von Kafka beleuchtet und gezeigt, wie diese im Zusammenspiel ein hochgradig skalierbares und fehlertolerantes Messagingsystem ergeben.
Broker
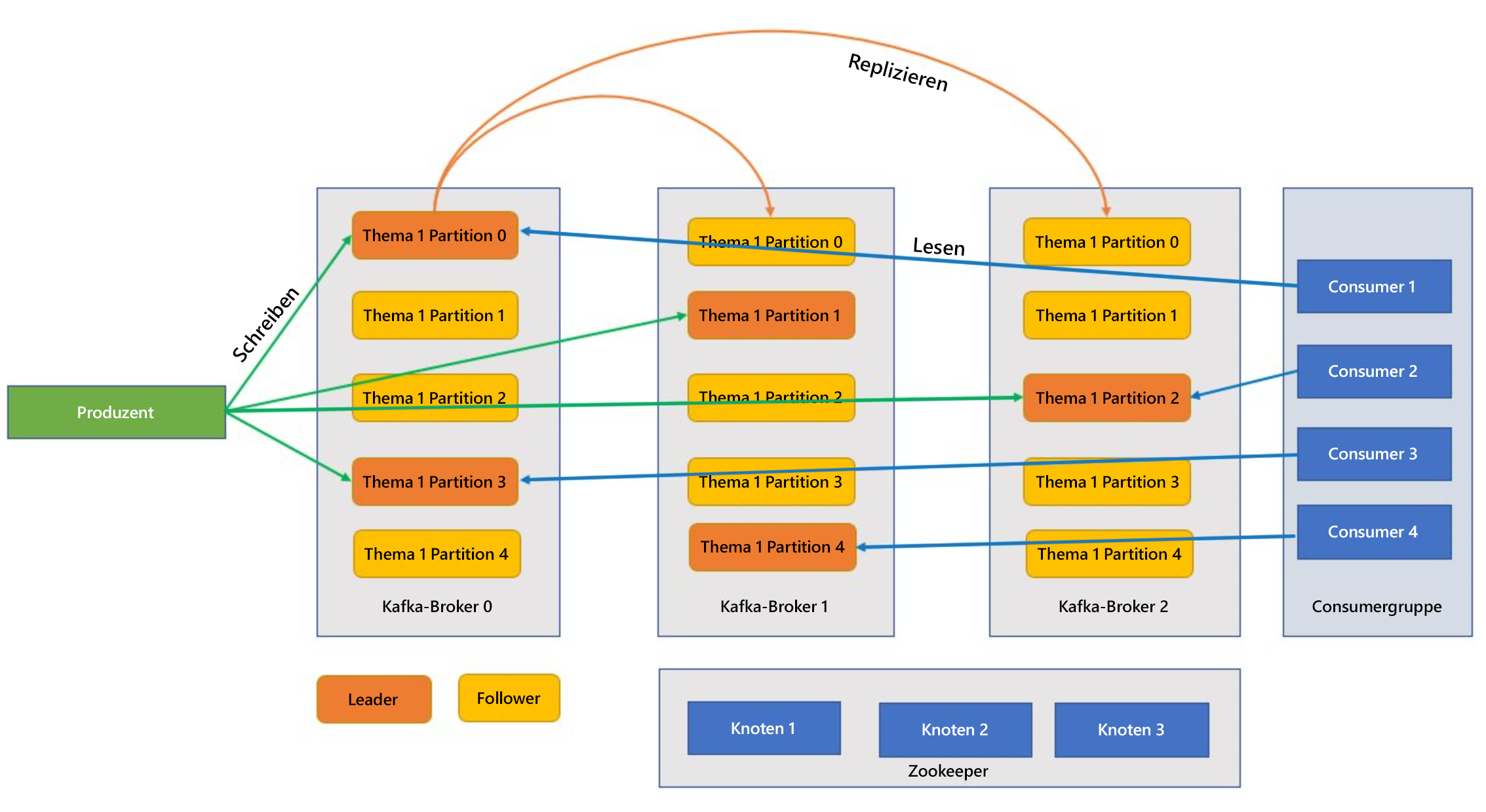
Kafka ist ein Clusterdienst, und ein einzelner Kafka-Cluster wird auch als Broker bezeichnet. Broker empfangen Nachrichten von den Producern und speichern diese Nachrichten auf einem Datenträger. Der Broker antwortet auch auf Abrufanforderungen von Consumern. In einem Brokercluster fungiert ein Broker als Controller und ist für administrative Vorgänge und das Zuweisen von Partitionen zu Brokern zuständig.
Meldung
Eine Nachricht stellt eine Dateneinheit in einem Kafka-Cluster dar. Nachrichten bestehen in den meisten Fällen aus Schlüssel-Wert-Paaren.
Themen und Partitionen
Themen und Partitionen sind Nachrichtenkategorien in Kafka. Themen werden zur Verbesserung des Durchsatzes normalerweise auf verschiedene Partitionen aufgeteilt, wobei mindestens drei Partitionen empfohlen werden. Nachrichten werden nur durch Anfügen in eine Themenpartition geschrieben. Partitionen werden in mehreren Brokern repliziert, um die Redundanz bei Brokerfehlern zu verbessern. In Partitionen können Themen parallel gelesen werden, da Daten sich auf mehrere Broker aufteilen lassen. Es gibt ein führendes Replikat, das alle Lese-/Schreibanforderungen verarbeitet, und die untergeordneten Instanzen werden vom führenden Replikat repliziert. Wenn eine führende Instanz ausfällt, nimmt eines der anderen Replikate ihren Platz ein.
Producer und Consumer
Producer und Consumer sind die Clients, die Nachrichten im Kafka-System erzeugen und dort verarbeiten. Producer veröffentlichen neue Nachrichten und leiten sie an ein bestimmtes Thema weiter. Consumer können so konzipiert werden, dass sie in eine bestimmte Themenpartition schreiben. Consumer abonnieren mindestens ein Thema und lesen Nachrichten darin.
Consumergruppe
Ein oder mehrere Consumer können als Gruppe zusammenarbeiten und Nachrichten als Gruppe verarbeiten. Wenn die Anzahl der Consumer gleich der Anzahl der Themenpartitionen ist, nutzt jeder Consumer eine einzelne Themenpartition, wodurch Parallelität entsteht.
Aufbewahrung
Nachrichten in Kafka können für einen vordefinierten Zeitraum dauerhaft im Kafka-Cluster aufbewahrt werden. Nachdem dieser Aufbewahrungszeitraum abgelaufen ist, kann Kafka die Nachrichten als abgelaufen erklären und sie löschen.
Offset
Ein Offset ist nichts anderes als die Position einer Nachricht innerhalb einer Partition. Die Aktualisierung dieser Position beim Verarbeiten von Nachrichten wird als Commit bezeichnet. Nachdem eine Nachricht verarbeitet wurde, committet Kafka den Offset der Nachricht in einem speziellen internen Kafka-Thema. Wenn ein Producer eine Nachricht in einer Partition veröffentlicht, wird sie an die führende Instanz weitergeleitet. Die führende Instanz fügt die Nachricht dem Commitprotokoll hinzu und erhöht den Nachrichtenoffset. Als Nachrichtenoffset wird die Art bezeichnet, wie Nachrichten innerhalb des Themas ermittelt werden. Die Meldung ist erst für den Consumer verfügbar, nachdem die Nachricht im Cluster committet wurde.
Zookeeper
Zookeeper ist ein Koordinationsdienst und bietet in Kafka-Clustern eine synchronisierte Ansicht des Clusterzustands. Kafka nutzt Zookeeper, um aus Brokern und Themenpartitionen eine übergeordnete Instanz zu wählen. Ferner verwaltet Kafka mithilfe von Zookeeper die Dienstermittlung für die Kafka-Broker, die den Cluster bilden. Zookeeper sendet Topologieänderungen an Kafka, sodass jeder Clusterknoten weiß, wann ein Broker erstellt oder gelöscht und ein Thema entfernt oder hinzugefügt wurde.
Wie setzen sich diese Einzelkomponenten zu einer Streamingplattform zusammen?
Anwendungen (auch Producer genannt) senden Nachrichten an einen Kafka-Broker. Diese Nachrichten werden von mindestens einem Consumer verarbeitet. Nachrichten in einem Cluster werden nach Themen kategorisiert. Beispiel: Ein Kunde kann das Thema „Vertrieb“ erstellen, um alle für den Vertrieb relevanten Nachrichten zu senden, und diesen Vorgang für weitere Abteilungen wiederholen. Wenn Themen durch eine zunehmende Anzahl von Nachrichten größer werden, werden sie in Partitionen aufgeteilt. Diese Partitionen werden aus Redundanzgründen weiter in Kafka-Brokern repliziert. Partitionen werden in führende und untergeordnete Instanzen eingeteilt. Die führende Partition ist diejenige, auf der alle Schreib- und Lesevorgänge erfolgen, während die untergeordneten Partitionen einfache Replikate sind, die den Zustand der übergeordneten Instanz übernehmen. Producer und Consumer müssen wissen, welche Partitionen als führende Instanz entworfen wurden, um zu ermitteln, auf welcher Partition Lese-/Schreibvorgänge ausgeführt werden sollen. Zookeeper-Knoten verwalten den Zustand des Kafka-Clusters. Außerdem wählen sie u. a. führende Partition aus und stellen diese für Producer und Consumer bereit.
Kafka gewährleistet, dass Nachrichten in einer Partition nach der Empfangszeit sortiert sind. Eine bestimmte Nachricht kann durch ihren Offset, d. h. durch ihre Position in der Partition, eindeutig identifiziert werden. Consumer lesen Nachrichten aus Partitionen und der Nachbearbeitung, committen den Offset und geben so an, dass die Nachricht erfolgreich verarbeitet wurde. Kafka speichert alle zugehörigen Datensätze auf einem Datenträger und sichert so die Nachrichtenpersistenz. Falls der Consumer unterbrochen und die Verarbeitung beendet wird, bewahrt Kafka diese Nachrichten für einen vorgegebenen Aufbewahrungszeitraum auf. Nachdem der Consumer wieder in Betrieb genommen wurde, kann er die Verarbeitung ab dem committeten Offset fortsetzen, an dem er unterbrochen wurde.
Kafka-Themen
Bei einem Kafka-Thema handelt es sich um einen Feed oder eine Warteschlange, in der Nachrichten gespeichert und veröffentlicht werden. Producer übertragen Nachrichten an Themen, während Consumer aus Themen lesen. Jeder Knoten in einem Kafka-Broker kann mehrere Themen enthalten.
Welche Vorteile bietet Kafka in Azure HDInsight?
Die Open-Source-Version von Kafka bietet zwar viele Funktionen, es fällt jedoch ein hoher Einrichtungsaufwand an. Azure HDInsight macht alle Vorteile von Open-Source-Analyseframeworks in Azure verfügbar und ermöglicht es Kunden, ihre Open-Source-Cluster innerhalb weniger Minuten anstelle von Wochen oder Monaten einzurichten – und das Beste ist, dass die Cluster sofort einsatzbereit sind. HDInsight ist außerdem aufgrund der folgenden Vorteile für Unternehmen geeignet:
- Es ist ein verwalteter Dienst, der einen vereinfachten Konfigurationsprozess bereitstellt. Das Ergebnis ist eine von Microsoft getestete und unterstützte Konfiguration.
- Microsoft bietet eine 99,9 prozentige Vereinbarung zum Servicelevel (Service Level Agreement, SLA) zur Uptime von Spark und Kafka.
- Azure Managed Disks werden als Sicherungsspeicher für Kafka verwendet. Managed Disks kann mehrere Kafka-Broker mi jeweils bis zu 16 TB Speicher bereitstellen.
- HDInsight bietet mit VNETs, differenzierten Sicherheitskontrollen dank Apache Ranger und Bring-Your-Own-Key-Verschlüsselung (BYOK) für ruhende Daten die höchste Unternehmenssicherheit.
- HIPAA-, SOC- und PCI-Compliance
- Die Möglichkeit, über automatisierte Azure Resource Manager-Vorlagen (ARM) im gleichen VNET umfassende Streamingpipelines mit Spark und Storage bereitzustellen
- Hochverfügbarkeit kann mit Kafka MirrorMaker erzielt werden. Dieses Tool verarbeitet Datensätze aus Themen im primären Cluster und erstellt eine lokale Kopie im sekundären Cluster.
- Mit HDInsight können Sie die Anzahl von Workerknoten (zum Hosten des Kafka-Brokers) nach der Clustererstellung ändern. Die Skalierung kann über das Azure-Portal, Azure PowerShell und andere Azure-Verwaltungsoberflächen durchgeführt werden. Für Kafka sollten Sie für Partitionsreplikate nach Skalierungsvorgängen einen Ausgleichsvorgang durchführen. Durch das Ausgleichen von Partitionen kann für Kafka die neue Anzahl von Workerknoten genutzt werden.
- Zur Überwachung von Kafka in HDInsight können Azure Monitor-Protokolle verwendet werden. Azure Monitor protokolliert VM-Informationen, z. B. Metriken zu Datenträgern und NICs sowie JMX-Metriken aus Kafka.