Auswählen der richtigen MPI-Bibliothek
HB120_v2-, HB60- und HC44-SKUs unterstützen InfiniBand-Netzwerkverbindungen. Da PCI Express über die E/A-Virtualisierung mit Einzelstamm (Single-Root Input/Output Virtualization, SR-IOV) virtualisiert wird, sind alle gängigen MPI-Bibliotheken (HPC-X, OpenMPI, Intel MPI, MVAPICH und MPICH) auf diesen HPC-VMs verfügbar.
Die aktuelle Obergrenze für einen HPC-Cluster, der über InfiniBand kommunizieren kann, liegt bei 300 VMs. In der folgenden Tabelle ist die jeweilige maximale Anzahl paralleler Prozesse aufgelistet, die in eng gekoppelten MPI-Anwendungen unterstützt werden, die über InfiniBand kommunizieren.
| SKU | Maximale Anzahl paralleler Prozesse |
|---|---|
| HB120_v2 | 36.000 Prozesse |
| HC44 | 13.200 Prozesse |
| HB60 | 18.000 Prozesse |
Hinweis
Diese Grenzwerte können sich ändern. Wenn Sie über einen eng gekoppelten MPI-Auftrag verfügen, der eine höhere Anzahl erfordert, senden Sie eine Supportanfrage. Möglicherweise können die Grenzwerte für Ihr Szenario erhöht werden.
Wenn eine HPC-Anwendung eine bestimmte MPI-Bibliothek empfiehlt, probieren Sie diese Version zuerst aus. Wenn Sie die MPI-Bibliothek frei wählen können und die beste Leistung erzielen möchten, probieren Sie es mit HPC-X. Insgesamt weist die MPI-Bibliothek HPC-X die beste Leistung auf, da sie das UCX-Framework für die InfiniBand-Schnittstelle verwendet und alle InfiniBand-Hardware- und Softwarefunktionen von Mellanox nutzt.
In der folgenden Abbildung werden die gängigen MPI-Bibliotheksarchitekturen gegenübergestellt.
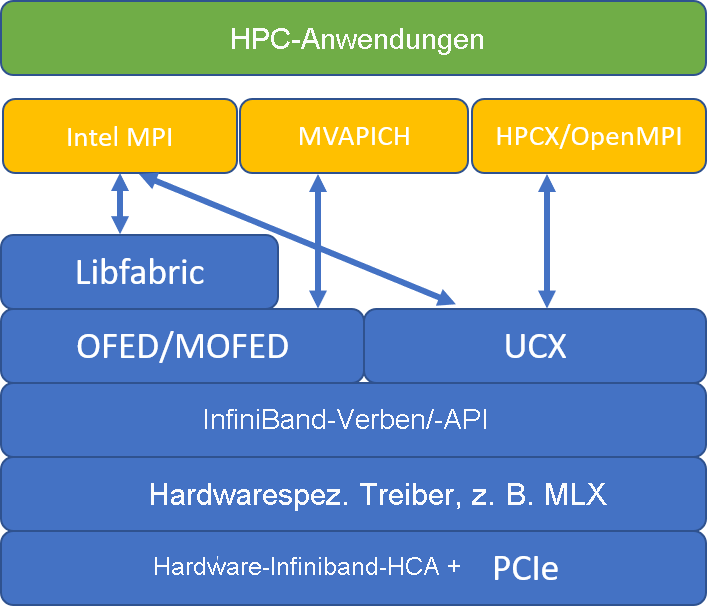
HPC-X und OpenMPI sind ABI-kompatibel, sodass Sie eine HPC-Anwendung, die mit OpenMPI erstellt wurde, dynamisch mit HPC-X ausführen können. Intel MPI, MVAPICH und MPICH sind ebenfalls ABI-kompatibel.
Die Gast-VM kann nicht auf das Warteschlangenpaar 0 zugreifen, um Sicherheitsrisiken über Low-Level-Hardwarezugriff zu verhindern. Dies sollte keine Auswirkung auf HPC-Anwendungen von Endbenutzern haben, kann jedoch verhindern, dass einige Low-Level-Tools ordnungsgemäß funktionieren.
mpirun-Argumente für HPC-X und OpenMPI
Der folgende Befehl enthält einige empfohlene mpirun-Argumente für HPC-X und OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
Dieser Befehl umfasst folgende Parameter:
| Parameter | BESCHREIBUNG |
|---|---|
$NPROCS |
Hier wird die Anzahl der MPI-Prozesse angegeben. Beispiel: -n 16 |
$HOSTFILE |
Gibt eine Datei an, die den Hostnamen oder die IP-Adresse enthält, um den Speicherort anzugeben, an dem die MPI-Prozesse ausgeführt werden. Beispiel: --hostfile hosts |
$NUMBER_PROCESSES_PER_NUMA |
Gibt die Anzahl der MPI-Prozesse an, die in jeder NUMA-Domäne ausgeführt werden. Für vier MPI-Prozesse pro NUMA-Domäne verwenden Sie z. B. --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Hier wird die Anzahl der Threads pro MPI-Prozess angegeben. Für einen MPI-Prozess und vier Threads pro NUMA-Domäne verwenden Sie z. B. --map-by ppr:1:numa:pe=4. |
-report-bindings |
Hiermit wird die Zuordnung der MPI-Prozesse zu den Kernen ausgegeben. Dies ist nützlich, um zu überprüfen, ob Sie die MPI-Prozesse richtig angeheftet haben. |
$MPI_EXECUTABLE |
Hier wird die erstellte ausführbare MPI-Datei angegeben, die die MPI-Bibliotheken einbindet. Bei MPI-Compilerwrappern erfolgt dies automatisch. Zum Beispiel: mpicc oder mpif90. |
Wenn Sie vermuten, dass übermäßig viel gemeinsame Kommunikation über Ihre eng gekoppelte MPI-Anwendung erfolgt, können Sie versuchen, Hierarchical Collectives (HCOLL) zu aktivieren. Verwenden Sie die folgenden Parameter, um diese Features zu aktivieren.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
mpirun-Argumente für Intel MPI
Mit dem Intel MPI 2019-Release wurde vom OFA-Framework (Open Fabrics Alliance) auf das OFI-Framework (Open Fabrics Interfaces) umgestellt, und libfabric wird derzeit unterstützt. Es gibt zwei Anbieter für InfiniBand-Unterstützung: mlx und verbs. Der Anbieter mlx ist der bevorzugte Anbieter für HB- und HC-VMs.
Im Folgenden sind einige Vorschläge für mpirun-Argumente für Intel MPI 2019, Update 5 und höher aufgeführt:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Diese Argumente umfassen folgende Parameter:
| Parameter | Beschreibung |
|---|---|
FI_PROVIDER |
Hier wird angegeben, welcher libfabric-Anbieter verwendet werden soll. Dies wirkt sich auf die API, das Protokoll und das Netzwerk aus, die verwendet werden. verbs ist eine weitere Option, doch bietet mlx im Allgemeinen eine bessere Leistung. |
I_MPI_DEBUG |
Hier wird der Umfang der zusätzlichen Debugausgabe angegeben, die Details dazu bereitstellen kann, wo Prozesse angeheftet sind und welches Protokoll und Netzwerk verwendet werden. |
I_MPI_PIN_DOMAIN |
Hier geben Sie an, wie Sie die Prozesse anheften möchten. Sie können sie beispielsweise an Kerne, Sockets oder NUMA-Domänen anheften. In diesem Beispiel wurde diese Umgebungsvariable auf numa festgelegt. Dies bedeutet, dass Prozesse an NUMA-Knotendomänen angeheftet werden. |
Es gibt noch einige weitere Optionen, die Sie ausprobieren können, insbesondere dann, wenn gemeinsame Vorgänge viel Zeit beanspruchen. Intel MPI 2019, Update 5 und höher, unterstützt den Anbieter mlx und verwendet das UCX-Framework für die Kommunikation mit InfiniBand. Darüber hinaus wird HCOLL unterstützt.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
mpirun-Argumente für MVAPICH
In der folgenden Liste sind einige empfohlene mpirun-Argumente aufgeführt:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Diese Argumente umfassen folgende Parameter:
| Parameter | BESCHREIBUNG |
|---|---|
MV2_CPU_BINDING_POLICY |
Hier wird angegeben, welche Bindungsrichtlinie verwendet werden soll. Dies wirkt sich darauf aus, wie Prozesse an Kern-IDs angeheftet werden. In diesem Fall geben Sie scatter an, sodass die Prozesse gleichmäßig auf die NUMA-Docks verteilt werden. |
MV2_CPU_BINDING_LEVEL |
Hier wird angegeben, wo Prozesse angeheftet werden sollen. In diesem Fall wurde numanode festgelegt. Dies bedeutet, dass Prozesse an NUMA-Domäneneinheiten angeheftet werden. |
MV2_SHOW_CPU_BINDING |
Hier wird angegeben, ob Debuginformationen dazu abgerufen werden sollen, wo die Prozesse angeheftet sind. |
MV2_SHOW_HCA_BINDING |
Hier wird angegeben, ob Debuginformationen dazu abgerufen werden sollen, welchen Hostkanaladapter die einzelnen Prozesse verwenden. |