Überlegungen zum Anheften von Prozessen
Warum werden Prozesse und Threads angeheftet?
Heften Sie Prozesse immer an bestimmte Kerne, um maximale Leistung zu erzielen und eine konsistentere Leistung von Ausführung zu Ausführung zu erreichen.
Anheften von Prozessen:
Maximiert die Arbeitsspeicherbandbreite, indem Prozesse an Speicherorten platziert werden, die alle Speicherkanäle verwenden und diese Kanäle gleichmäßig auf die Kerne verteilen, oder indem Prozesse an diese Speicherorte angeheftet werden.
Verbessert die Leistung in Bezug auf Gleitkommaoperationen, indem sichergestellt wird, dass jeder Prozess sich auf einem eigenen Kern befindet. Dadurch wird verhindert, dass zwei Prozesse auf demselben Kern landen.
Optimiert die Datenverschiebung zwischen den Prozessen, indem Prozesse platziert werden, die über NUMA-Domänenknoten (Non-Uniform Memory Access) kommunizieren. Hierdurch werden die geringstmögliche Latenz und die höchste Bandbreite gewährleistet.
Reduziert den Verwaltungsaufwand für das Betriebssystem, und Sie erhalten konsistentere Ergebnisse, da das Betriebssystem Prozesse nicht auf andere Kerne oder in andere NUMA-Domänen verschieben kann.
Wo werden Prozesse und Threads angeheftet?
Damit Sie wissen, wo Prozesse und Threads angeheftet werden sollen, müssen Sie die Prozessor- und Arbeitsspeichertopologie sowie insbesondere die Anzahl und den Standort der NUMA-Domänen kennen.
Das Hilfsprogramm lstopo-no-graphics (aus hwloc RPM) und Intel Memory Latency Checker (MLC) sind nützliche Tools zum Ermitteln der Prozessor- und Arbeitsspeichertopologie. Damit finden Sie z. B. Antworten auf die folgenden Fragen: Über wie viele NUMA-Domänen verfügt die VM? Welche Kerne gehören jeweils zu den einzelnen NUMA-Domänen? Wie hoch ist die Latenz und wie groß die Bandbreite für Prozesse in den einzelnen NUMA-Domänen, während diese miteinander kommunizieren?
In der folgenden Abbildung sehen Sie die von Intel MLC generierte Latenzzuordnung für die NUMA-Domänen von HB120_v2. Je geringer die Latenz zwischen NUMA-Domänen ist, desto schneller ist die Kommunikation zwischen ihnen. Die Abbildung zeigt deutlich, dass HB120_v2 über 30 NUMA-Domänen verfügt und welche NUMA-Domänen sich auf welchem Socket befinden. Außerdem ist zu sehen, welche NUMA-Domänen gruppiert werden können, um eine möglichst geringe Latenz für die Datenübertragung und Kommunikation zu erzielen.

Intel-Prozessoren verfügen über sechs Speicherkanäle, AMD EPYC-Prozessoren über acht. Stellen Sie sicher, dass Sie alle Speicherkanäle verwenden, um die verfügbare Arbeitsspeicherbandbreite zu maximieren. Dazu verteilen Sie die parallelen Prozesse gleichmäßig auf die NUMA-Knotendomänen. Sorgen Sie bei hybriden parallelen Anwendungen dafür, dass Prozesse/Threads in denselben NUMA-Domänen gruppiert werden und idealerweise denselben L3-Cache verwenden. Stellen Sie sicher, dass die Gesamtanzahl der Threads die Gesamtanzahl der Kerne nicht übersteigt.
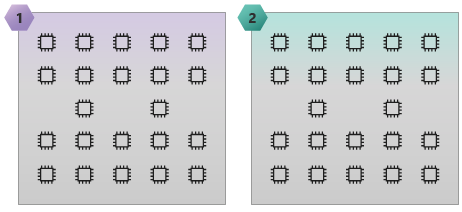
Die folgende Abbildung zeigt eine HC44-SKU mit zwei NUMA-Domänen und 44 Kernen.
Die folgende Abbildung zeigt eine HB60-SKU mit 15 NUMA-Domänen und 60 Kernen.
An die Arbeitsspeicher-Bandbreite gebundene Anwendungen
Wenn Sie über eine Anwendung verfügen, die an die Arbeitsspeicherbandbreite gebunden ist, können Sie möglicherweise eine bessere Leistung auf der VM erzielen, indem Sie die Anzahl paralleler Prozesse und Threads in den einzelnen NUMA-Knotendomänen verringern. Dadurch kann eine größere Arbeitsspeicherbandbreite pro Prozess bereitgestellt werden.
Wenn Sie z. B. eine HB120_v2-SKU mit 30 NUMA-Knotendomänen verwenden, können Sie einen, zwei und drei Prozesse und Threads pro NUMA-Knotendomäne (z. B. 30, 60 und 90 Prozesse und Threads pro VM) ausführen. Anschließend können Sie sehen, welche Konfiguration die beste Leistung bietet.