Optimieren des Quellsystems – erweitert
Dieser erweiterte Leitfaden kann für den Quellexport von VLDB-Systemen hilfreich sein:
Oracle ROW ID-Tabellenaufteilung
SAP hat den SAP-Hinweis 1043380 veröffentlicht, der ein Skript enthält, das die WHERE-Klausel in einer WHR-Datei in einen Zeilen-ID-Wert konvertiert. Alternativ dazu erzeugen die neuesten Versionen von SAPInst automatisch WHR-Dateien für die ROW ID-Aufteilung, wenn SWPM für die Migration von Oracle zu Oracle R3load konfiguriert ist. Die von SWPM generierten STR- und WHR-Dateien sind unabhängig von Betriebssystem und Datenbank (ebenso wie alle Aspekte des Migrationsprozesses für Betriebssystem/Datenbank).
Der OSS-Hinweis enthält die folgende Information: „Die ROWID-Tabellenaufteilung kann NICHT verwendet werden, wenn die Zieldatenbank keine Oracle-Datenbank ist“. Technisch gesehen sind die R3load-Sicherungsdateien unabhängig von Datenbank und Betriebssystem. Es gibt jedoch eine Einschränkung: Ein Neustart eines Pakets während des Imports ist für SQL Server nicht möglich. In diesem Fall muss die gesamte Tabelle gelöscht und alle Pakete für die Tabelle müssen neu gestartet werden. Es wird immer empfohlen, R3load-Aufgaben für eine spezifische geteilte Tabelle zu beenden, TRUNCATE für die Tabelle auszuführen und den gesamten Importprozess neu zu starten, wenn eine R3load-Aufteilungsvorgang abgebrochen wird. Der Grund dafür ist, dass der integrierte Wiederherstellungsprozess von R3load einzelne zeilenweise DELETE-Anweisungen umfasst, um die vom abgebrochenen R3load-Prozess geladenen Datensätze zu entfernen. Dieses Verfahren ist langsam und führt häufig zu Blockierungen und Sperrungen in der Datenbank. Die Erfahrung zeigt, dass der Import dieser spezifischen Tabelle schneller erfolgt, wenn er vom Beginn an gestartet wird. Deshalb ist die in SAP-Hinweis 1043380 genannte Einschränkung keine Einschränkung.
ROW ID hat den Nachteil, dass die Berechnung der Aufteilungen während der Downtime erfolgen muss, siehe SAP-Hinweis 1043380.
Erstellen mehrerer Klone der Quelldatenbank und paralleler Export
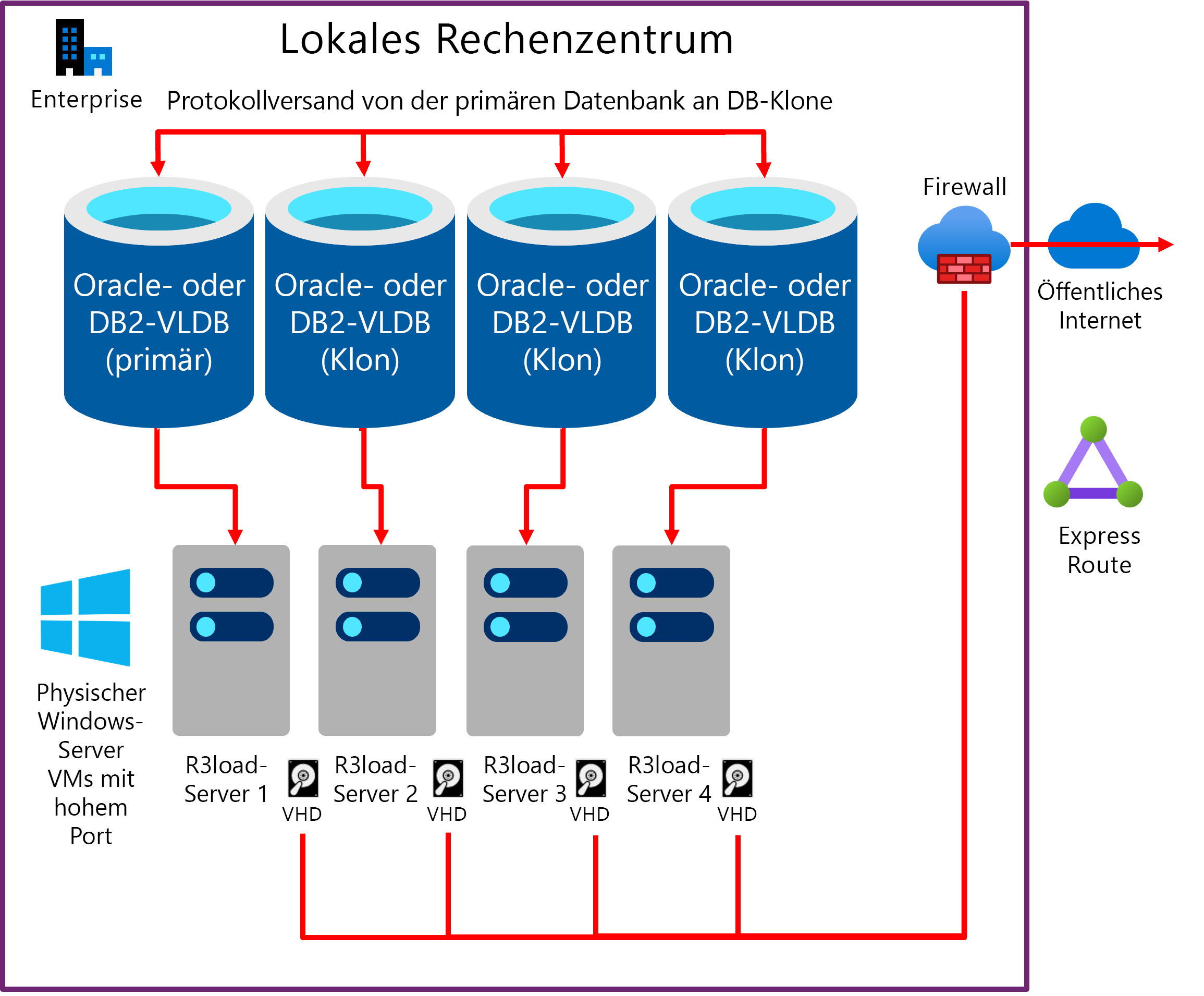
Eine Methode zur Steigerung der Exportleistung ist der Export aus mehreren Kopien derselben Datenbank. Wenn die zugrunde liegende Infrastruktur einschließlich Server, Netzwerk und Speicher skalierbar ist, ist dieser Ansatz tendenziell linear skalierbar. Der Export aus zwei Kopien derselben Datenbank ist doppelt so schnell, vier Kopien sind viermal so schnell. Der Migration Monitor ist so konfiguriert, dass er eine ausgewählte Anzahl von Tabellen aus jedem Klon der Datenbank exportiert. Im folgenden Fall ist die Exportworkload zu je etwa 25 % auf die vier Datenbankserver verteilt.
- DB-Server 1 und Exportserver 1: vorgesehen für die größten 1–4 Tabellen, abhängig vom Grad der Verzerrung der Datenverteilung in der Quelldatenbank
- DB-Server 2 und Exportserver 2: vorgesehen für Tabellen mit Tabellenaufteilungen
- DB-Server 3 und Exportserver 3: vorgesehen für Tabellen mit Tabellenaufteilungen
- DB-Server 4 und Exportserver 4: für alle übrigen Tabellen
Es muss sorgfältig darauf geachtet werden, dass die Datenbanken genau synchronisiert sind, da es sonst zu Datenverlusten oder Dateninkonsistenzen kommen kann. Wenn die angegebenen Schritte genau befolgt werden, bleibt die Datenintegrität gewahrt.
Die Technik ist einfach und kostengünstig mit handelsüblicher Intel-Hardware umzusetzen, kann aber auch von Kunden mit proprietärer UNIX-Hardware eingesetzt werden. Zur Mitte eines Datenbank-/DB-Migrationsprojekts hin werden erhebliche Hardwareressourcen frei, wenn Sandbox-, Entwicklungs-, QAS-, Trainings- und DR-Systeme bereits nach Azure verlagert wurden. Es ist nicht zwingend erforderlich, dass die Klonserver über identische Hardwareressourcen verfügen. Bei angemessener CPU-, RAM-, Datenträger- und Netzwerkleistung erhöht das Hinzufügen jedes Klons die Leistung.
Falls eine zusätzliche Exportleistung benötigt wird, öffnen Sie in BC-DB-MSS einen SAP-Incident, um weitere Schritte zur Steigerung der Exportleistung zu unternehmen (nur für erfahrene Berater).
Die Schritte zum Implementieren eines mehrfach parallelen Exports lauten wie folgt:
- Sichern Sie die primäre Datenbank, und führen Sie auf „n“ Servern eine Wiederherstellung durch (n = Anzahl von Klonen). In diesem Beispiel wird von n = 3 Servern und damit insgesamt vier Datenbankservern ausgegangen.
- Stellen Sie die Sicherung auf drei Servern wieder her.
- Richten Sie den Protokollversand vom primären Quell-DB-Server an drei Zielklonserver ein.
- Überwachen Sie den Protokollversand für mehrere Tage, und stellen Sie sicher, dass der Protokollversand zuverlässig funktioniert.
- Zu Beginn der Downtime werden alle SAP-Anwendungsserver mit Ausnahme von PAS heruntergefahren. Stellen Sie sicher, dass die gesamte Batchverarbeitung beendet und sämtlicher RFC-Datenverkehr eingestellt wird.
- Geben Sie in Transaktion SM02 den Text „Checkpoint PAS Running“ ein. Dadurch wird die Tabellen-TEMSG aktualisiert.
- Beenden Sie den primären Anwendungsserver. SAP ist jetzt heruntergefahren. In der Quelldatenbank können keine Schreibvorgänge mehr ausgeführt werden. Stellen Sie sicher, dass keine Nicht-SAP-Anwendung mit der Quell-DB verbunden ist (dies sollte nie der Fall sein, aber prüfen Sie, ob auf Datenbankebene Nicht-SAP-Sitzungen vorhanden sind).
- Führen Sie diese Abfrage auf dem primären Datenbankserver aus:
SELECT EMTEXT FROM [schema].TEMSG; - Führen Sie die folgende native Anweisung auf DBMS-Ebene aus:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(Die genaue Syntax richtet sich nach dem Quell-DBMS. Einfügen über INSERT in EMTEXT.) - Halten Sie die automatische Transaktionsprotokollsicherung an. Führen Sie manuell eine abschließende Transaktionsprotokollsicherung auf dem primären Datenbankserver aus. Stellen Sie sicher, dass die Protokollsicherung auf die Klonserver kopiert wird.
- Stellen Sie die endgültige Transaktionsprotokollsicherung auf allen drei Knoten wieder her.
- Stellen Sie die Datenbank auf den 3 Klonknoten wieder her.
- Führen Sie die folgende SELECT-Anweisung auf allen vier Knoten aus:
SELECT EMTEXT FROM [schema].TEMSG; - Erfassen Sie die Bildschirmergebnisse der SELECT-Anweisung für jeden der vier Datenbankserver (primärer Server und drei Klone). Achten Sie genau darauf, jeden Hostnamen anzugeben. So wird bestätigt, dass die Klon-DB und die primäre DB identisch sind und dieselben Daten desselben Zeitpunkts enthalten.
- Starten Sie „export_monitor.bat“ auf jedem Intel R3load-Exportserver.
- Starten Sie den Prozess zum Kopieren der Dumpdatei nach Azure (entweder mit AzCopy oder Robocopy).
- Starten Sie „import_monitor.bat“ auf den R3load-Azure-VMs.
Die folgende Abbildung zeigt einen vorhandenen Protokollversand der Produktionsdatenbankserver an die Klondatenbanken. Jeder Datenbankserver verfügt über mindestens einen Intel R3load-Server.