Identifizieren von Migrationstooloptionen
Es gibt viele Optionen, um eine Migration von einem PostgreSQL-Server zu Azure Database for PostgreSQL – Flexibler Server durchzuführen. Es gibt native PostgreSQL-Tools wie pg_dump, pgadmin und pg_restore. Und es gibt Microsoft Azure-Clouddienste wie den Database Migration Service und die Migrationsoption in Azure Database for PostgreSQL – Flexibler Server, die den gesamten Datenübertragungsprozess von Quelle zum Ziel weitestgehend automatisieren kann.
Azure Database for PostgreSQL – Flexibler Server: Migration
Im Dienst Azure Database for PostgreSQL – Flexibler Server steht eine native Funktion zur Verfügung, um Datenbanken von anderen PostgreSQL-Instanzen zum Azure-basierten Dienst zu unterstützen. Diese Option ist für die Offlinemigration von Datenbanken von der Quelle zum Ziel konzipiert. Um diese Option zu verwenden, müssen Sie die zuvor erläuterten Tools pg_dumpall und psql verwenden, um die Objektdatenbanken auf Serverebene zu Flexibler Server zu migrieren.
Dieses Feature wurde mit externen PostgreSQL-Instanzen als Quelle und Flexibler Server als Ziel entworfen, an dem das Migrationsprojekt erstellt wurde. Dies dient im Wesentlichen zum Pullen von Daten in Flexibler Server. Ein Vorteil der Verwendung dieses Diensts gegenüber der manuellen Erstellung und Wiederherstellung eines Speicherabbilds stellt die verwaltete Form der Migration dar. Nach der Konfiguration überwacht der Dienst den Prozess für alle Tabellen, die zu Flexibler Server migriert werden, sodass Sie ganz einfach erkennen können, wann die Umstellung auf Anwendungsebene durchgeführt werden kann.
Migrationsprojekte
Nachdem Konnektivität hergestellt ist, müssen Sie lediglich die Datenbanken auswählen, die Sie zum neuen Server migrieren möchten. Beachten Sie im folgenden Screenshot, dass Sie bei mehreren Datenbanken für mehrere Dienste, die Teil eines größeren Systems sind, auswählen können, ob sie als Gruppe anstatt einzeln migriert werden. Diese Datenbankgruppierung kann nicht nur dazu beitragen, die Migration zu beschleunigen, sondern auch die logische Konsistenz während der Migrationsaktivitäten aufrechtzuerhalten.
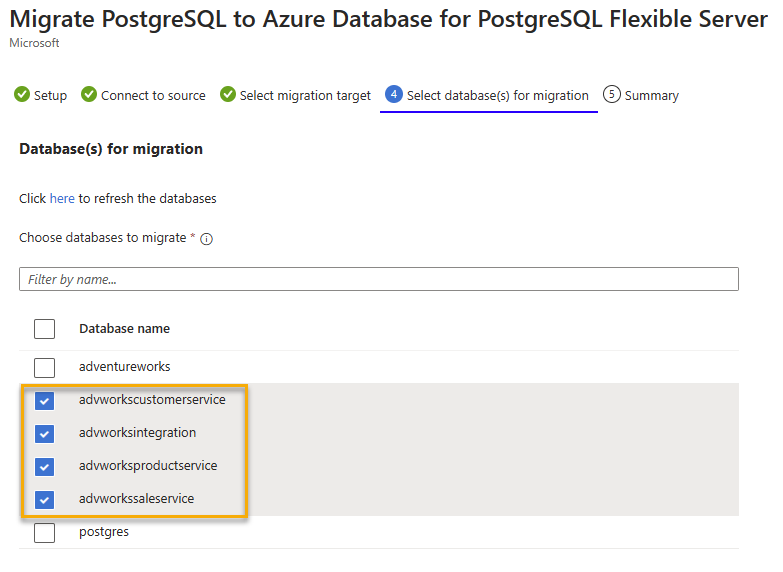
Wenn Sie den Überprüfungs- und Migrationsprozess starten, können Sie den Gesamtfortschritt auf dem Projektdashboard überprüfen. Auf diesem Dashboard wird angezeigt, welche Datenbanken gerade validiert und welche zum neuen Server migriert werden.
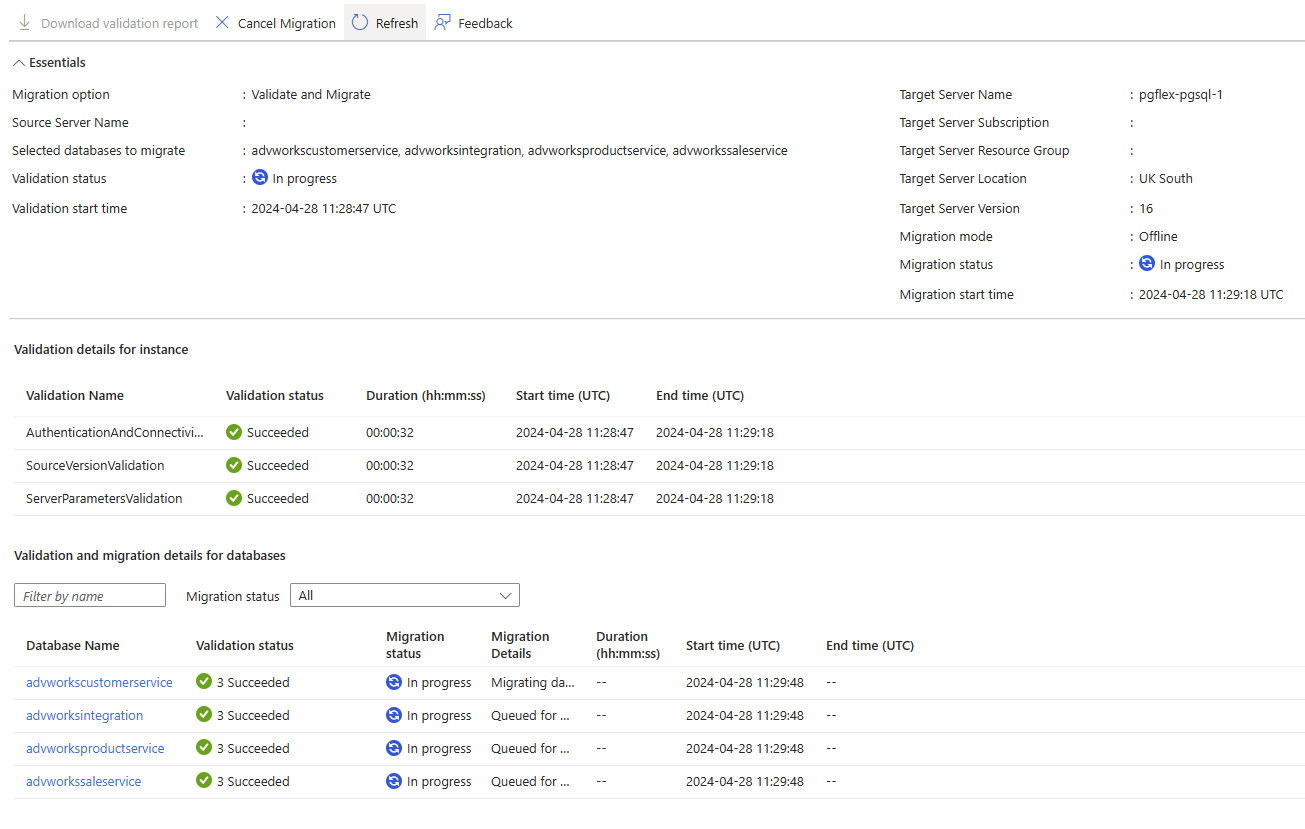
Diese Informationen werden nach der Migration gespeichert, sodass Sie den Gesamtfortschritt nachverfolgen können. Die Informationen umfassen auch alle Nachweise, die erforderlich sind, um Kontrollprozesse für Erfolg und Dauer der durchgeführten Arbeiten zu ändern.
PostgreSQL-Tools
Hier untersuchen Sie die wichtigsten Tools, die zum Migrieren von Daten von einem PostgreSQL-Server zu Azure Database for PostgreSQL – Flexibler Server verwendet werden können.
pgcopydb
Mit dem Open-Source-Projekt pgcopydb können Sie den Kopiervorgang von Datenbanken zwischen PostgreSQL-Servern automatisieren. Die Verwendung von pgcopydb bietet gegenüber den nativen Tools, die bei der Installation von PostgreSQL bereitgestellt werden, einige Vorteile.
- Keine Notwendigkeit der Erstellung von Zwischendateien mit pg_backup und pg_restore
- Nebenläufigkeit bei der Indexerstellung zum Parallelisieren der Erstellung von Indizes in Tabellen mithilfe der synchronize__seqscans-Funktion in PostgreSQL
- Multithreadtabellen zum parallelen Kopieren in Partitionsdaten und Übertragen größerer Tabellen
- Change Data Capture für die Datensynchronisierung zum Minimieren längerer Ausfallzeiten
Es gibt zwei Hauptoptionen in pgcopydb, die für die Datenbank- und Datenmigration von einem Quellserver zum Ziel verwendet werden können. Diese Optionen sind: clone und copy.
pgcopydb clone
„clone“ ist die primäre Option zum Kopieren einer gesamten Datenbank von einem Quellserver zum Ziel. Dieser Befehl verfügt über mehrere Operation, mit denen Sie einen einfachen Klonvorgang konfigurieren, aber auch die CDC-Konfiguration (Change Data Capture) zum Synchronisieren von Daten und zum Minimieren der Ausfallzeiten automatisieren können. Sie können auch Optionen zum Parallelisieren der Datenübertragung nach Tabelle und für die parallele Übertragung von Tabellen, Indizes und großen Objekte angeben.
pgcopydb copy
Die Option „copy“ bietet umfangreichere Steuerungsmöglichkeiten, wenn es darum geht, die Datenbank oder Teile davon zu migrieren. Mit dieser Befehlsoption können Sie auswählen, welche Schemas, Tabellen, Rollen usw. von einer Datenbank auf dem Quellserver auf den Zielserver und die Zieldatenbank übertragen werden sollen. Dieser Befehl ist in den Szenarien hilfreich, in denen eine große Datenbank im Rahmen einer Migrationsaktivität zur Anwendungsmodernisierung in kleinere Datenbanken aufgeteilt wird. Alternativ können Sie mit einer Migrationsaktivität zur Konsolidierung den Inhalt einer Datenbank zu Schemas einer anderen Datenbank migrieren.
Diese Optionen stellen nur einige der Möglichkeiten dar, mit denen pgcopydb Ihnen helfen kann, den Prozess der Migration von Datenbanken zu Azure Database for PostgreSQL – Flexibler Server zu verbessern. Dieser Prozess ermöglicht eine Migration, die Risiken minimiert und gleichzeitig die Erfolgsaussichten maximiert.
pgAdmin
pgAdmin ist ein weit verbreitetes Verwaltungstool, das für die Interaktion mit PostgreSQL-Datenbanken verwendet werden kann. Dieses Tool ermöglicht die Erstellung und Ausführung von pgsql-Skripts. Das Tool enthält eine ganze Reihe nützlicher Tools mit Benutzeroberfläche, die zum Konfigurieren, Sichern und Wiederherstellen von PostgreSQL-Datenbanken verwendet werden können. In der Regel wird pgAdmin auf Arbeitsstationen für die Verwaltung installiert. Dieses Tool ermöglicht das Registrieren und Verbindung mit mehreren PostgreSQL-Servern und stellt damit ein wichtiges Migrationstool dar.
pg_dump, pg_restore und psql
pg_dump ist ein Befehlszeilentool, das mit einer PostgreSQL-Instanz installiert und bei Bedarf auf einer Verwaltungsarbeitsstation installiert werden kann. Es ermöglicht die Erstellung konsistenter Datenbanksicherungen aus PostgreSQL, selbst wenn parallel eine Workload ausgeführt wird. Es ist für Einzeldatenbanken konzipiert und ermöglicht, eine ganze Datenbank oder Teile davon zu sichern.
Wenn Sie pg_dump zum Exportieren von Schemaobjekten verwenden, können Sie mit psql die resultierende SQL-Datei in der Zieldatenbank auszuführen, um die Objekte zu erstellen. Nach diesem Schritt können Sie Möglichkeiten zum Verschieben der Daten vom Quell- zum Zielsystem untersuchen. Die Befehle, die zum Exportieren eines Datenbankschemas aus einer Datenbank und zum Erstellen in einer anderen Datenbank verwendet werden, sind im folgenden Beispiel dargestellt.
pg_dump -O --host=MyServerName --port=5432 --username=adminuser --dbname=AdventureWorks --schema-only > adventureWorks.sql
psql --host=MyFlexibleServer --username=demo --dbname=AdventureWorks < adventureWorks.sql
Wenn Sie eine vollständige Sicherung der Quelldatenbank erstellen, verwenden Sie pg_restore, um die resultierende Datei zu lesen und die Datenbank in der PostgreSQL-Zielinstanz wiederherzustellen. Die Dauer dieser Aktivitäten beim Ausführen einer Sicherung und Wiederherstellung der Sicherung hängen von verschiedenen Faktoren ab. Insbesondere spielen die Größe der Datenbank, die Leistung des Speichersubsystems sowie die Netzwerkbandbreite und -latenz zwischen den Verarbeitungskomponenten eine Rolle.
Das folgende Beispiel zeigt, wie Sie eine Datenbanksicherung auf einem benutzerdefinierten Server erstellen und anschließend auf einem anderen Server wiederherstellen.
pg_dump -Fc --host=MyServerName --port=5432 --username=adminuser --dbname=AdventureWorks > db.dump
pg_restore -Fc --host=MyServerName --port=5432 --create --username=adminuser --dbname=AdventureWorks db.dump
pg_dumpall
Während pg_dump verwendet wird, um eine einzelne Datenbank zusichern, dient pg_dumpall dazu, alle Datenbanken in einer einzigen Skriptdatei zusammenzufassen, die dann von psql in eine neue Instanz von PostgreSQL eingelesen wird.
Darüber hinaus können Sie mit pg_dumpall bei der Migration zwischen Servern Skriptdateien für Objekte auf globaler Serverebene (z. B. Rollen) generieren, von denen die Datenbanken abhängen können.