Skalieren von Computeressourcen in Azure Synapse Analytics
Eines der wichtigsten Verwaltungsfeatures, die Ihnen in Azure Synapse Analytics zur Verfügung stehen, ist die Möglichkeit, die Computeressourcen für SQL- oder Spark-Pools zu skalieren, um die Anforderungen an die Verarbeitung Ihrer Daten zu erfüllen. Die Skalierungseinheit in SQL-Pools ist eine Abstraktion der Computeleistung, die als Data Warehouse-Einheit bezeichnet wird. Compute- und Speicherressourcen sind getrennt, sodass Sie Compute unabhängig von den Daten in Ihrem System skalieren können. Das heißt, Sie können die Computeleistung entsprechend Ihren Anforderungen herunterskalieren und hochskalieren.
Sie können einen Synapse SQL-Pool entweder über das Azure-Portal, über Azure Synapse Studio oder programmgesteuert mithilfe von T-SQL oder PowerShell skalieren.
Im Azure-Portal können Sie auf das Symbol Skalieren klicken.
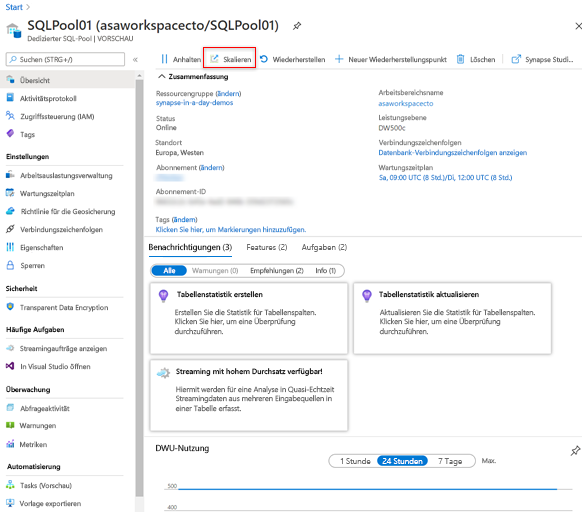
Anschließend können Sie den Schieberegler anpassen, um den SQL-Pool zu skalieren.
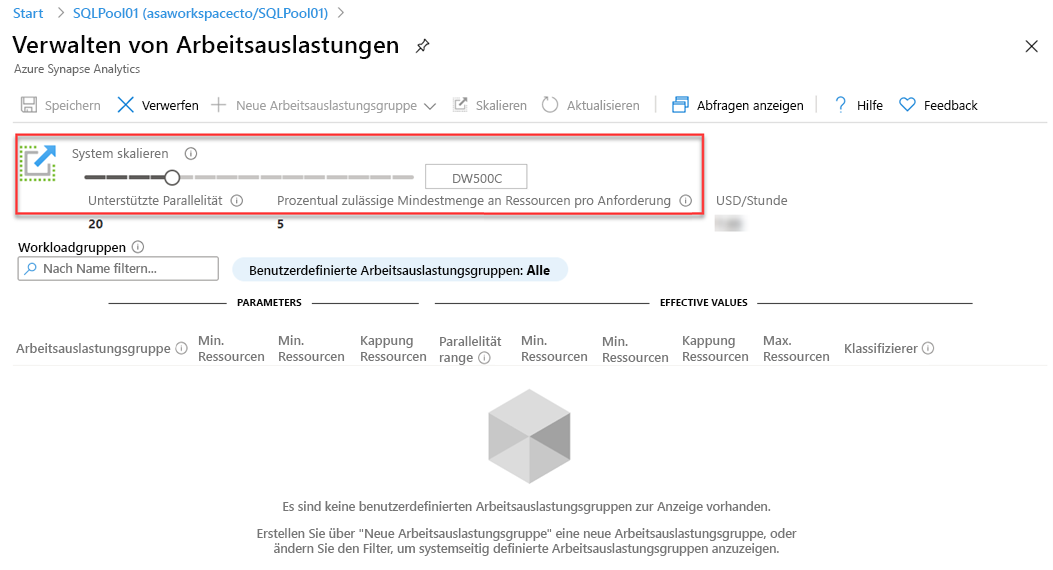
Eine weitere Skalierungsoption finden Sie in Azure Synapse Studio. Klicken Sie dort auf das Symbol Skalieren:
Verschieben Sie den Schieberegler dann folgendermaßen:
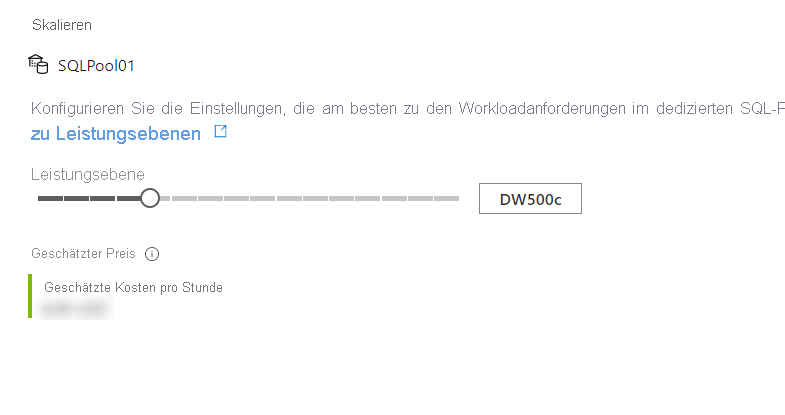
Sie können die Änderung auch mithilfe von Transact-SQL vornehmen.
ALTER DATABASE mySampleDataWarehouse
MODIFY (SERVICE_OBJECTIVE = 'DW300c');
Dies ist auch mithilfe von PowerShell möglich.
Set-AzSqlDatabase -ResourceGroupName "resourcegroupname" -DatabaseName "mySampleDataWarehouse" -ServerName "sqlpoolservername" -RequestedServiceObjectiveName "DW300c"
Skalieren von Apache Spark-Pools in Azure Synapse Analytics
Für Apache Spark-Pools wird in Azure Synapse Analytics ein Feature für die Autoskalierung verwendet, das die Anzahl der Knoten in einer Clusterinstanz automatisch nach oben oder unten skaliert. Während der Erstellung eines neuen Spark-Pools kann bei Auswahl der Autoskalierung eine minimale und maximale Anzahl von Knoten festgelegt werden. Die automatische Skalierung überwacht dann die Ressourcenanforderungen der Auslastung und skaliert die Anzahl von Knoten zentral hoch oder herunter. Um die Funktion für automatische Skalierung zu aktivieren, führen Sie als Teil des normalen Poolerstellungsvorgangs die folgenden Schritte aus:
- Aktivieren Sie auf der Registerkarte Grundlagen das Kontrollkästchen Automatische Skalierung aktivieren.
- Geben Sie die gewünschten Werte für die folgenden Eigenschaften ein:
- Min. Anzahl von Knoten
- Max. Anzahl von Knoten
Die anfängliche Anzahl von Knoten ist der Minimalwert. Dieser Wert definiert die Anfangsgröße der Instanz bei der Erstellung. Die Mindestanzahl von Knoten darf nicht kleiner als drei sein.
Sie können dies auch im Azure-Portal ändern, klicken Sie dazu auf das Symbol Einstellungen für die Autoskalierung.
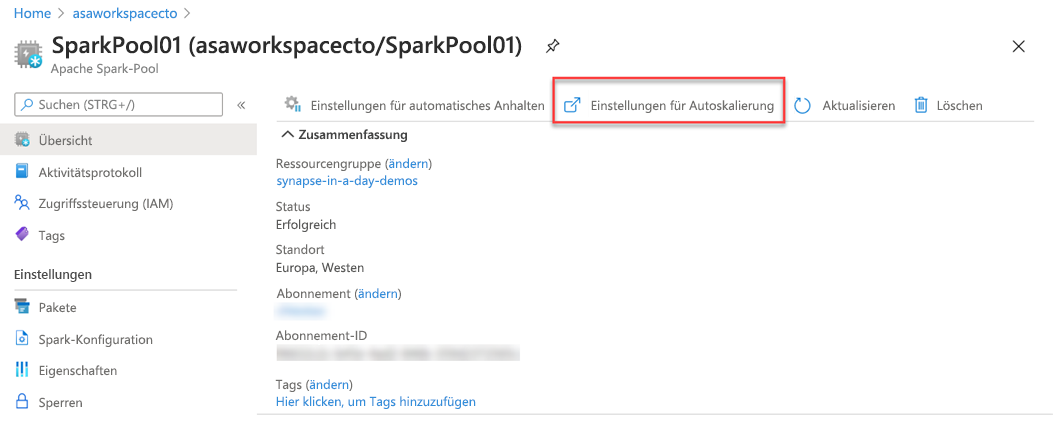
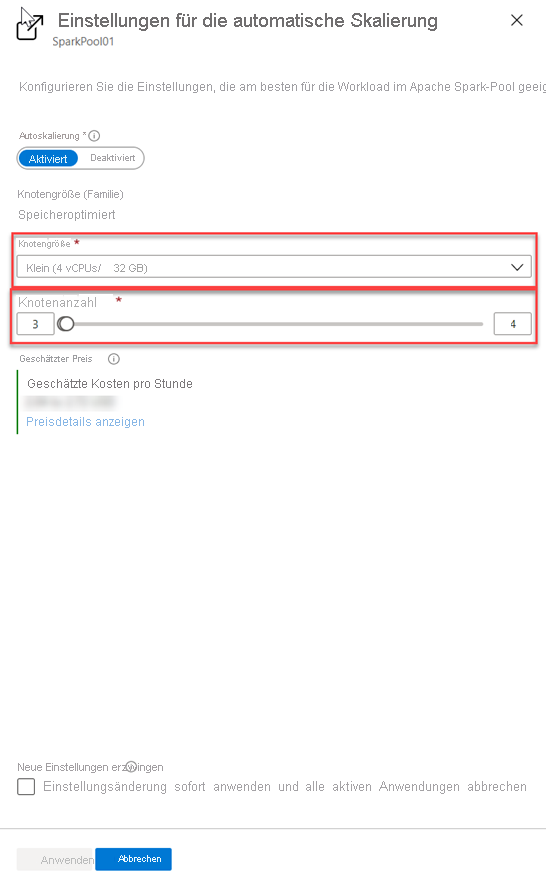
Wählen Sie eine Knotengröße und eine Knotenanzahl aus.
Gehen Sie in Azure Synapse Studio folgendermaßen vor:
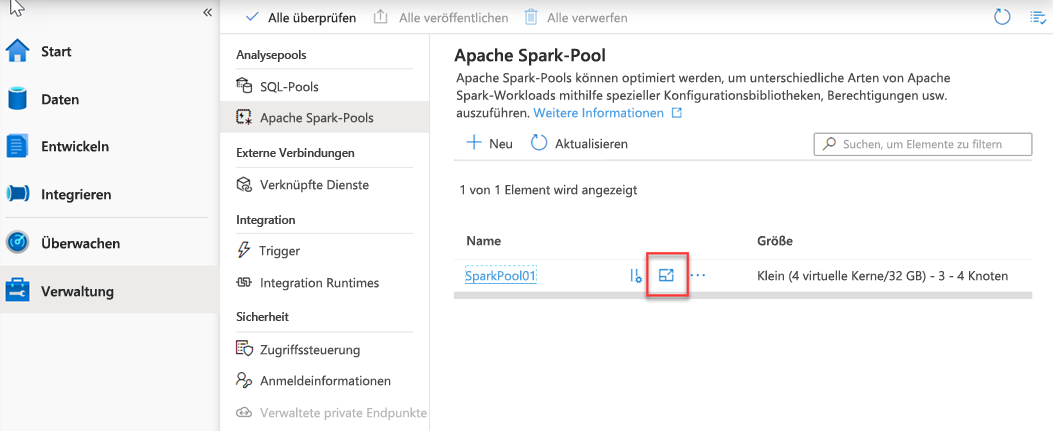
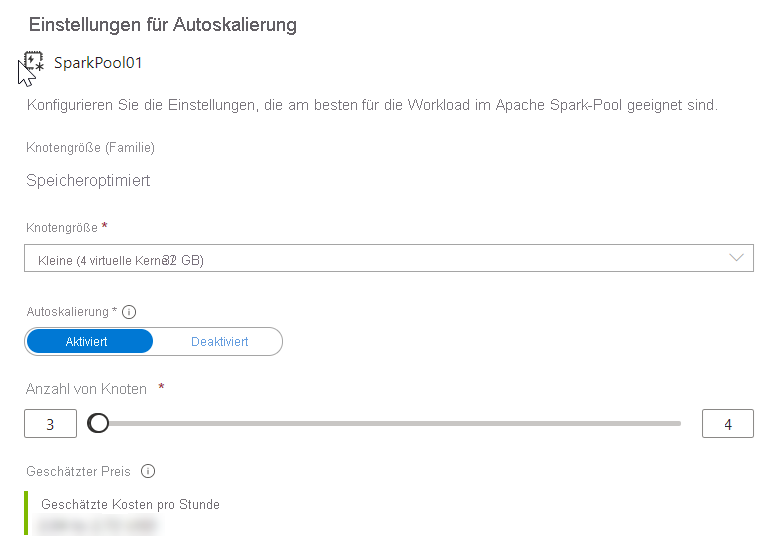
Wählen Sie anschließend eine Knotengröße und eine Knotenanzahl aus.
Die automatische Skalierung überwacht kontinuierlich die Spark-Instanz und sammelt die folgenden Metriken:
| Metrik | BESCHREIBUNG |
|---|---|
| CPU insgesamt für ausstehende | Die Gesamtanzahl von Kernen, die zum Starten der Ausführung aller ausstehenden Knoten erforderlich sind. |
| Arbeitsspeicher insgesamt für ausstehende | Die Gesamtgröße des Arbeitsspeichers (in MB), die zum Starten der Ausführung aller ausstehenden Knoten erforderlich ist. |
| Freie CPUs insgesamt | Die Summe aller nicht verwendeten Kerne auf den aktiven Knoten. |
| Freier Arbeitsspeicher insgesamt | Die Summe des nicht verwendeten Arbeitsspeichers (in MB) auf den aktiven Knoten. |
| Verwendeter Arbeitsspeicher pro Knoten | Die Auslastung eines Knotens. Ein Knoten, auf dem 10 GB Arbeitsspeicher verwendet werden, ist höher ausgelastet als ein Knoten, auf dem 2 GB verwendet werden. |
Die folgenden Bedingungen führen dann zu einer Autoskalierung für Arbeitsspeicher oder CPU.
| Zentrales Hochskalieren | Zentrales Herunterskalieren |
|---|---|
| „CPU insgesamt für ausstehende“ ist länger als eine Minute größer als die Anzahl der insgesamt freien CPUs. | „CPU insgesamt für ausstehende“ ist länger als 2 Minuten kleiner als die Anzahl der insgesamt freien CPUs. |
| „Arbeitsspeicher insgesamt für ausstehende“ ist länger als 1 Minute größer als der insgesamt freie Arbeitsspeicher. | „Arbeitsspeicher insgesamt für ausstehende“ ist länger als 2 Minuten kleiner als der insgesamt freie Arbeitsspeicher. |
Der Skalierungsvorgang kann ein bis fünf Minuten dauern. Beim Herunterskalieren der Instanz wird für die Knoten durch die Autoskalierung der Status „Wird außer Betrieb gesetzt“ festgelegt, sodass keine neuen Executors auf diesen Knoten gestartet werden können.
Die ausgeführten Aufträge werden weiterhin ausgeführt und abgeschlossen. Für die ausstehenden Aufträge wird auf die reguläre Einplanung mit weniger verfügbaren Knoten gewartet.