Konfigurieren von Speicher und Datenbanken
Häufig erfordert ein Teil Ihres Bereitstellungsprozesses, dass Sie eine Verbindung mit Datenbanken oder Speicherdiensten herstellen. Diese Verbindung kann erforderlich sein, um ein Datenbankschema anzuwenden, einer Datenbanktabelle Verweisdaten hinzuzufügen oder einige Blobs hochzuladen. In dieser Lerneinheit erfahren Sie, wie Sie Ihren Workflow erweitern können, um mit Daten- und Speicherdiensten zu arbeiten.
Konfigurieren Ihrer Datenbanken über einen Workflow
Viele Datenbanken verfügen über Schemas, die die Struktur der in der Datenbank enthaltenen Daten darstellen. Als Best Practice empfiehlt es sich häufig, ein Schema aus dem Bereitstellungsworkflow auf Ihre Datenbank anzuwenden. Dadurch wird sichergestellt, dass alles, was Ihre Lösung benötigt, zusammen bereitgestellt wird. Außerdem wird sichergestellt, dass Ihr Workflow bei einem Problem bei der Anwendung des Schemas einen Fehler anzeigt, sodass Sie das Problem beheben und den Workflow erneut bereitstellen können.
Wenn Sie mit Azure SQL arbeiten, müssen Sie Datenbankschemas anwenden, indem Sie eine Verbindung mit dem Datenbankserver herstellen und Befehle mithilfe von SQL-Skripts ausführen. Bei diesen Befehlen handelt es sich um Vorgänge auf Datenebene. Ihr Workflow muss sich beim Datenbankserver authentifizieren und dann die Skripts ausführen. GitHub Actions stellt die Aktion azure/sql-action zur Verfügung, die eine Verbindung mit einem Azure SQL-Datenbankserver herstellen und Befehle ausführen kann.
Einige andere Daten- und Speicherdienste müssen nicht mithilfe einer Datenebenen-API konfiguriert werden. Wenn Sie beispielsweise mit Azure Cosmos DB arbeiten, speichern Sie Ihre Daten in einem Container. Sie können Ihre Container mithilfe der Steuerungsebene direkt in Ihrer Bicep-Datei konfigurieren. Ebenso können Sie die meisten Aspekte von Azure Storage-Blobcontainern in Bicep bereitstellen und verwalten. In der nächsten Übung sehen Sie ein Beispiel zum Erstellen eines Blobcontainers aus Bicep.
Hinzufügen von Daten
Viele Lösungen erfordern, dass Verweisdaten zu ihren Datenbanken oder Speicherkonten hinzugefügt werden, bevor sie funktionieren. Workflows können ein guter Standort zum Hinzufügen dieser Daten sein. Dies bedeutet, dass Ihre Umgebung nach der Workflowausführung vollständig konfiguriert und einsatzbereit ist.
Es ist auch hilfreich, Beispieldaten in Ihren Datenbanken zu verwenden, insbesondere für Nicht-Produktionsumgebungen. Mit Beispieldaten können Tester*innen und andere Personen, die diese Umgebungen verwenden, Ihre Lösung sofort testen. Diese Daten können Beispielprodukte oder Dinge wie gefälschte Benutzerkonten umfassen. Im Allgemeinen möchten Sie diese Daten nicht zu Ihrer Produktionsumgebung hinzufügen.
Der Ansatz, den Sie zum Hinzufügen von Daten verwenden, hängt vom von Ihnen verwendeten Dienst ab. Beispiel:
- Zum Hinzufügen von Daten zu einer Azure SQL-Datenbank müssen Sie ein Skript ausführen, ähnlich wie beim Konfigurieren eines Schemas.
- Wenn Sie Daten in Azure Cosmos DB einfügen müssen, müssen Sie auf die Datenebenen-API zugreifen. Daher müssen Sie möglicherweise benutzerdefinierten Skriptcode schreiben.
- Zum Hochladen von Blobs in einen Azure Storage-Blobcontainer können Sie verschiedene Tools aus Workflowskripts verwenden, einschließlich der AzCopy-Befehlszeilenanwendung, Azure PowerShell oder der Azure CLI. Jedes dieser Tools versteht, wie es sich bei Azure Storage in Ihrem Namen authentifiziert und eine Verbindung mit der Datenebenen-API herstellt, um Blobs hochzuladen.
Idempotenz
Eines der Merkmale von Bereitstellungsworkflows und Infrastructure-as-Code ist, dass Sie in der Lage sein sollten, die Bereitstellung wiederholt und ohne negative Nebeneffekte durchzuführen. Wenn Sie beispielsweise eine bereits bereitgestellte Bicep-Datei noch mal bereitstellen, vergleicht der Azure Resource Manager die übermittelte Datei mit dem vorhandenen Status Ihrer Azure-Ressourcen. Wenn es keine Änderungen gibt, wird nichts ausgeführt. Die Fähigkeit, einen Vorgang wiederholt noch mal auszuführen, wird als Idempotenz bezeichnet. Als Best Practice sollten Sie sicherstellen, dass Ihre Skripts und andere Workflowschritte idempotent sind.
Idempotenz ist besonders wichtig, wenn Sie mit Datendiensten interagieren, da sie den Zustand behalten. Angenommen, Sie fügen einen Beispielbenutzer aus Ihrem Workflow in eine Datenbanktabelle ein. Wenn Sie nicht vorsichtig sind, wird bei jeder Ausführung Ihres Workflows ein neuer Beispielbenutzer erstellt. Dies ist wahrscheinlich nicht das, was Sie möchten.
Wenn Sie Schemas auf eine Azure SQL-Datenbank anwenden, können Sie ein Datenpaket verwenden, das auch als DACPAC-Datei bezeichnet wird, um Ihr Schema bereitzustellen. Ihr Workflow erstellt eine DACPAC-Datei aus dem Quellcode und ein Workflowartefakt, genau wie bei einer Anwendung. Anschließend veröffentlicht der Bereitstellungsauftrag in Ihrem Workflow die DACPAC-Datei in der Datenbank:
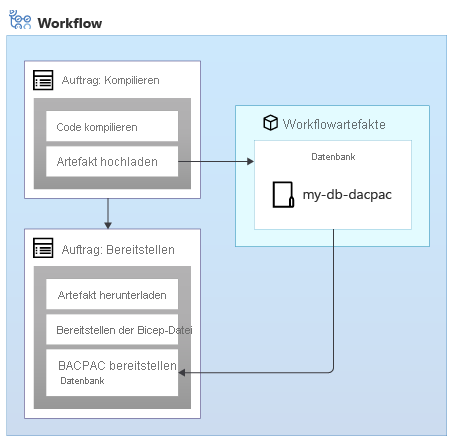
Wenn eine DACPAC-Datei bereitgestellt wird, verhält sie sich idempotent, indem der Zielzustand Ihrer Datenbank mit dem im Paket definierten Zustand verglichen wird. In vielen Situationen bedeutet dies, dass Sie keine Skripts schreiben müssen, die dem Idempotenzprinzip folgen, da die Tools die Verarbeitung für Sie übernehmen. Einige der Tools für Azure Cosmos DB und Azure Storage verhalten sich ebenfalls ordnungsgemäß.
Wenn Sie jedoch Beispieldaten in einer Azure SQL-Datenbank oder einem anderen Speicherdienst erstellen, der nicht automatisch idempotent funktioniert, ist es eine bewährte Methode, Ihr Skript so zu schreiben, dass es die Daten nur erstellt, wenn sie noch nicht vorhanden sind.
Es ist auch wichtig zu bedenken, ob Sie eventuell einen Rollback für Bereitstellungen durchführen müssen, beispielsweise durch das erneute Ausführen einer älteren Version eines Bereitstellungsworkflows. Der Rollback an Ihren Daten kann kompliziert werden. Überlegen Sie daher sorgfältig, wie Ihre Lösung funktioniert, wenn Sie Rollbacks zulassen müssen.
Netzwerksicherheit
Manchmal können Sie Netzwerkeinschränkungen auf einige Ihrer Azure-Ressourcen anwenden. Diese Einschränkungen können Regeln für Anforderungen erzwingen, die an die Datenebene einer Ressource gestellt werden, z. B.:
- Auf diesen Datenbankserver kann nur über eine angegebene Liste von IP-Adressen zugegriffen werden.
- Auf dieses Speicherkonto kann nur von Ressourcen zugegriffen werden, die in einem bestimmten virtuellen Netzwerk bereitgestellt werden.
Netzwerkeinschränkungen gibt es häufig bei Datenbanken, da es so aussieht, als ob im Internet keine Verbindung mit einem Datenbankserver erforderlich wäre.
Allerdings können Netzwerkbeschränkungen auch die Zusammenarbeit Ihrer Bereitstellungsworkflows mit den Datenebenen Ihrer Ressourcen erschweren. Wenn Sie einen von GitHub gehosteten Runner verwenden, ist dessen IP-Adresse nicht ohne Weiteres im Voraus bekannt und wird möglicherweise aus einem großen Pool von IP-Adressen zugewiesen. Darüber hinaus können von GitHub gehostete Runner nicht mit Ihren eigenen virtuellen Netzwerken verbunden werden.
Einige der Aktionen, die Ihnen beim Ausführen von Vorgängen auf Datenebene helfen, können diese Probleme umgehen. Ein Beispiel hierfür ist die Aktion azure/sql-action:
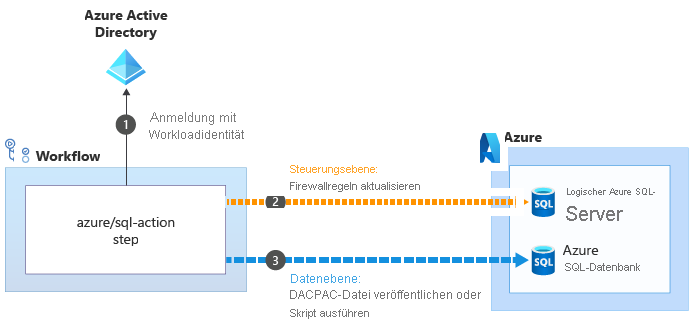
Wenn Sie die Aktion azure/sql-action nutzen, um mit einem logischen Azure SQL-Server oder einer logischen Datenbank zu arbeiten, wird Ihre Workloadidentität verwendet, um eine Verbindung mit der Steuerungsebene für den logischen Azure SQL-Server herzustellen. Die Firewall wird aktualisiert, damit der Runner über seine IP-Adresse auf den Server zugreifen kann
verwendet, um eine Verbindung mit der Steuerungsebene für den logischen Azure SQL-Server herzustellen. Die Firewall wird aktualisiert, damit der Runner über seine IP-Adresse auf den Server zugreifen kann  . Anschließend kann die DACPAC-Datei oder das Skript erfolgreich zur Ausführung übermittelt werden
. Anschließend kann die DACPAC-Datei oder das Skript erfolgreich zur Ausführung übermittelt werden  . Die Aktion entfernt dann nach Abschluss des Vorgangs automatisch die Firewallregel.
. Die Aktion entfernt dann nach Abschluss des Vorgangs automatisch die Firewallregel.
In anderen Situationen ist es nicht möglich, Ausnahmen wie diese zu erstellen. Erwägen Sie unter diesen Umständen die Verwendung eines selbstgehosteten Runners, der auf einer VM oder einer anderen Computeressource ausgeführt wird, die Sie kontrollieren. Sie können diesen Runner dann nach Bedarf konfigurieren. Er kann eine bekannte IP-Adresse verwenden oder mit Ihrem eigenen virtuellen Netzwerk verbunden werden. In diesem Modul werden keine selbstgehosteten Runner besprochen, aber auf der „Zusammenfassungsseite“ des Moduls finden Sie Links zu weiteren Informationen.
Ihr Bereitstellungsworkflow
In der nächsten Übung aktualisieren Sie Ihren Bereitstellungsworkflow, um neue Aufträge zur Erstellung der Datenbankkomponenten Ihrer Website, zur Bereitstellung der Datenbank und zum Hinzufügen von Seedingdaten einzufügen:
