Verstehen von Microsoft Defender XDR in einem Security Operations Center (SOC)
Die folgende Grafik enthält einen Überblick darüber, wie Microsoft Defender XDR und Microsoft Sentinel in ein modernes Security Operations Center (SOC) integriert sind.
Security Operations-Modell: Aufgabenbereiche und Tools
Auch wenn die Zuweisung von Zuständigkeiten an einzelne Personen und Teams je nach Größe der Organisation und anderen Faktoren variiert, setzt sich Security Operations aus mehreren verschiedenen Aufgabenbereichen zusammen. Jeder Aufgabenbereich bzw. jedes Team hat einen Schwerpunkt und muss eng mit anderen Aufgabenbereichen und externen Teams zusammenarbeiten, um effektiv sein zu können. Dieses Diagramm zeigt das vollständige Modell mit vollständig besetzten Teams. In kleineren Organisationen sind diese Aufgaben oft in einer einzigen Rolle oder einem Team zusammengefasst, werden vom IT-Betrieb wahrgenommen (für technische Rollen) oder werden als temporäre Aufgaben von Führungskräften oder Stellvertretern übernommen (für das Incidentmanagement).
Hinweis
Wir verweisen auf die Analysten in erster Linie anhand des Teamnamens und nicht anhand der Ebenennummern, da jedes dieser Teams über besondere Fachkenntnisse verfügt und es sich nicht um eine buchstäbliche Rangliste/Hierarchie des Nutzens handelt.
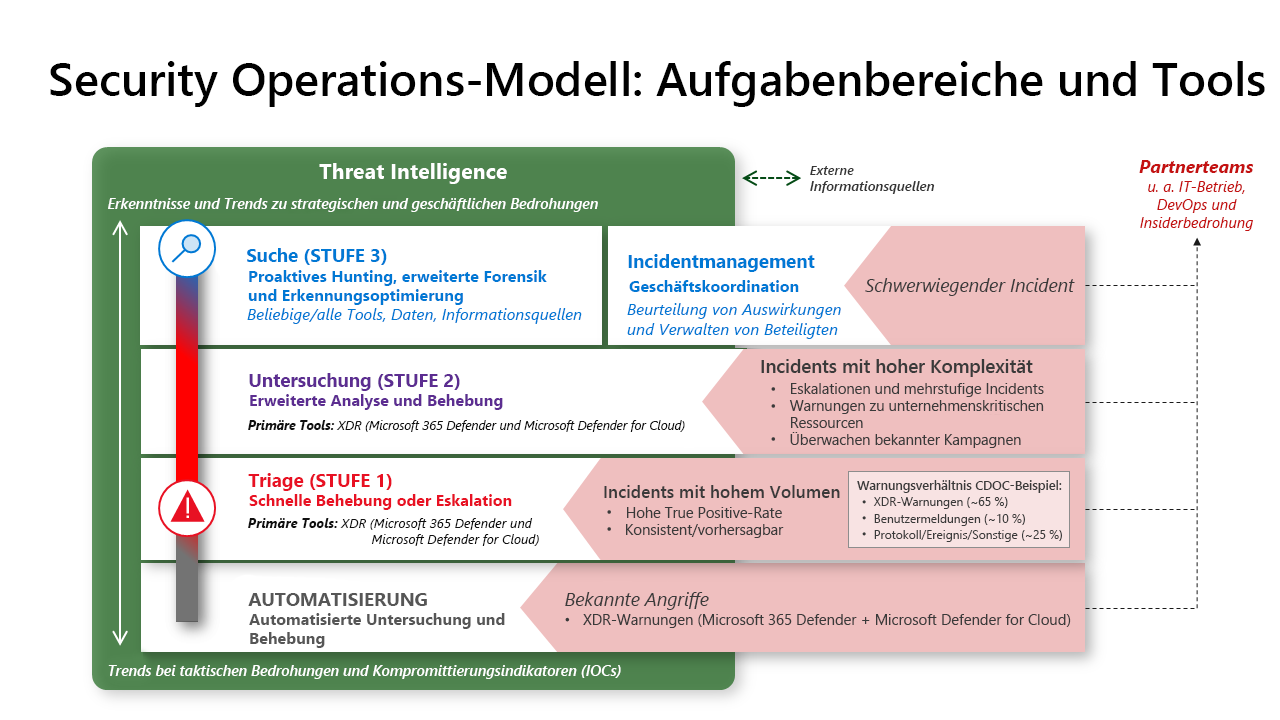
Triage und Automatisierung
Wir beginnen mit dem Umgang mit reaktiven Warnungen, der mit Folgendem beginnt:
Automatisierung: Lösung bekannter Incidenttypen in nahezu Echtzeit mittels Automatisierung. Es handelt sich um genau definierte Angriffe, die die Organisation schon oft beobachtet hat.
Triage (Stufe 1): Triage-Analysten konzentrieren sich auf schnelle Korrekturen eines hohen Volumens bekannter Incidenttypen, die weiterhin (schnell) ein menschliches Urteil erfordern. Dies wird häufig mit der Genehmigung automatisierter Korrekturworkflows und der Identifizierung von anomalen oder interessanten Aufgaben durchgeführt, die eine Eskalation oder Konsultation mit Untersuchungsteams (Stufe 2) gewährleisten.
Wichtige Erkenntnisse zur Triage und Automatisierung
- Zu 90 % richtig positive Ergebnisse: Wir empfehlen, für alle Warnungen, auf die ein Analyst reagieren muss, einen Qualitätsstandard von zu 90 % richtig positiven Ergebnissen festzulegen, damit Analysten nicht auf ein hohes Volumen von Fehlalarmen reagieren müssen.
- Warnungsquote: Nach den Erfahrungen unseres Cyber Defense Operations Center liefert Microsoft mit XDR-Warnungen die meisten qualitativ hochwertigen Warnungen. Die restlichen Warnungen stammen von Problemen, die von Benutzer*innen gemeldet wurden, von klassischen auf Abfragen basierenden Warnungen und aus anderen Quellen.
- Automatisierung ist ein wichtiger Faktor für Triage-Teams, da sie diese Analysten in die Lage versetzt, den manuellen Aufwand zu reduzieren (z. B. durch eine automatisierte Untersuchung und eine anschließende Aufforderung zur Überprüfung durch einen Mitarbeiter, ehe die Folge von Abhilfemaßnahmen genehmigt wird, die automatisch für diesen Incident erstellt wurde).
- Integration von Tools: Eine der leistungsfähigsten und zeitsparendsten Technologien, die in Microsofts CDOC die Zeit bis zur Problembehebung verkürzt hat, ist die Integration der XDR-Tools in Microsoft Defender XDR, sodass Analysten über eine zentrale Konsole für Endpunkte, E-Mail, Identitätsprüfung und mehr verfügen. Diese Integration ermöglicht es Analysten, Phishing-E-Mails, Schadsoftware und durch Angreifer kompromittierte Konten schnell zu entdecken und zu bereinigen, ehe sie größeren Schaden anrichten können.
- Fokus: Diese Teams können ihre hohe Lösungsgeschwindigkeit nicht für alle Arten von Technologien und Szenarien beibehalten, also konzentrieren sie sich auf einige wenige technische Bereiche und/oder Szenarien. Meistens geht es dabei um die Benutzerproduktivität, wie z. B. E-Mail, Virenwarnungen für Endgeräte (im Gegensatz zu EDR [Endpoint Detection and Response, Endpunkterkennung und Reaktion], die in Untersuchungen einfließt) und die erste Reaktion auf Benutzermeldungen.
Untersuchung und Incidentmanagement (Stufe 2)
Dieses Team dient als Eskalationspunkt für Probleme von Triage (Stufe 1) und überwacht direkt Warnungen, die auf einen komplexeren Angreifer hinweisen. Insbesondere Warnungen, die Verhaltenswarnungen auslösen, Sonderfallwarnungen im Zusammenhang mit unternehmenskritischen Ressourcen und Überwachung für laufende Angriffskampagnen. Proaktiv prüft dieses Team auch regelmäßig die Warnungswarteschlange des Triage-Teams und kann in seiner freien Zeit mit XDR-Tools proaktiv auf die Suche gehen.
Dieses Team stellt eine tiefere Untersuchung zu einem niedrigeren Volumen komplexerer Angriffe bereit, oft mehrstufige Angriffe, die von menschlichen Angriffsoperatoren durchgeführt werden. Dieses Team pilotiert neue/nicht vertraute Warnungstypen für Dokumentprozesse für Triage-Team und Automatisierung, häufig einschließlich Warnungen, die von Microsoft Defender für Cloud für in der Cloud gehostete Apps, VMs, Container und Kubernetes, SQL-Datenbanken usw. generiert werden.
Vorfallmanagement – Dieses Team übernimmt die nicht-technischen Aspekte des Incident Managements, einschließlich der Koordination mit anderen Teams wie Kommunikation, Recht, Führung und anderen Geschäftsinteressenten.
Suche und Incidentmanagement (Stufe 3)
Es handelt sich um ein fachbereichsübergreifendes Team, das sich auf die Identifizierung von Angreifern konzentriert, die die reaktiven Erkennungsmechanismen umgangen haben könnten, und sich mit wichtigen Ereignissen befasst, die sich auf das Geschäft auswirken.
- Hunt – Dieses Team sucht proaktiv nach nicht erkannten Bedrohungen, hilft bei Eskalationen und erweiterten Forensiken für reaktive Untersuchungen und verbessert Warnungen/Automatisierung. Diese Teams funktionieren in mehr als einem hypothesengesteuerten Modell als einem reaktiven Warnungsmodell und sind auch dort, wo rote/lila Teams mit Sicherheitsvorgängen verbunden sind.
Wie alles zusammenkommt
Um Ihnen eine Vorstellung davon zu geben, wie das Ganze funktioniert, lassen Sie uns den üblichen Lebenszyklus eines Incidents nachvollziehen.
- Triage (Stufe 1): Der Analyst entnimmt der Warteschlange eine Warnung zu Schadsoftware und untersucht sie (z. B. mit der Microsoft Defender XDR-Konsole).
- Während die meisten Triage-Fälle schnell behoben und abgeschlossen werden, stellt der Analyst dieses Mal fest, dass die Malware möglicherweise eine aufwändigere/fortgeschrittenere Behebung erfordert (z. B. Geräteisolierung und -bereinigung). Triage eskaliert den Fall an den Untersuchungsanalysten (Ebene 2), der die Leitung der Untersuchung übernimmt. Das Triage-Team hat die Möglichkeit, sich weiter einzubringen und mehr zu erfahren (das Untersuchungsteam könnte Microsoft Sentinel oder ein anderes SIEM für einen breiteren Kontext verwenden).
- Die Zuständigen für die Untersuchung überprüfen die Schlussfolgerungen der Untersuchung (oder vertiefen sie), fahren mit der Behebung fort und schließen den Fall ab.
- Später können die Zuständigen für die Suche (Stufe 3) diesen Fall bei der Überprüfung abgeschlossener Vorfälle bemerken, um nach Gemeinsamkeiten oder Anomalien zu suchen, für die sich ein genauere Untersuchung lohnen:
- Erkennungen, die für die automatische Behebung in Frage kommen
- Mehrere ähnliche Incidents mit einer gemeinsamen Ursache
- Andere mögliche Verbesserungen von Prozessen/Tools/Warnungen. In einem Fall hat Stufe 3 den Fall überprüft und festgestellt, dass der Benutzer auf einen technischen Betrug hereingefallen war. Diese Erkennung wurde dann als Warnung mit potenziell höherer Priorität eingestuft, da es den Betrügern gelungen war, sich Administratorzugriff auf den Endpunkt zu verschaffen. Ein höheres Gefahrenpotenzial durch Risiken.
Bedrohungsanalyse
Threat Intelligence-Teams bieten Kontext und Einblicke, um alle anderen Aufgabenbereiche (mithilfe einer Threat Intelligence-Plattform [TIP] in größeren Organisationen) zu unterstützen. Dies könnte viele verschiedene Facetten umfassen, einschließlich
- Reaktive technische Forschung für aktive Vorfälle
- Proaktive technische Recherche von Angreifergruppen, Angriffstrends, Angriffe auf Profile mit hohen Rechten, neue Techniken usw.
- Strategische Analyse, Forschung und Einblicke, um Geschäfts- und technische Prozesse und Prioritäten zu informieren.
- und mehr...