Azure Batch
Unter High Performance Computing (HPC) versteht man die Nutzung einer beträchtlichen Rechenleistung, die im Vergleich zur Nutzung eines Laptops und/oder einer Workstation eine hohe Leistung bietet. Es löst große Probleme, die auf mehreren Kernen gleichzeitig laufen müssen.
Dazu wird ein Problem in kleinere berechenbare Einheiten aufgeteilt und diese Einheiten in einem verteilten System verteilt. Es kommuniziert ständig zwischen ihnen, um die endgültige Lösung viel schneller zu erreichen als die gleiche Berechnung auf weniger Kernen.
In Azure sind mehrere Optionen für die HPC- und Batchverarbeitung verfügbar. Wenn Sie mit Azure-Expert*innen sprechen, würden die Ihnen raten, sich auf drei Optionen zu konzentrieren: Azure Batch, Azure CycleCloud und Microsoft HPC Pack. Die folgenden Einheiten in diesem Modul konzentrieren sich auf jede Option. Beachten Sie, dass sich diese Optionen nicht gegenseitig ausschließen. Sie basieren aufeinander und können als unterschiedliche Tools in einer Toolbox angesehen werden.
Hier erfahren Sie mehr über High Performance Computing im Allgemeinen und über Azure HPC.
Was ist HPC bei Azure?
In vielen verschiedenen Branchen werden leistungsstarke Computingressourcen für spezielle Aufgaben benötigt. Beispiel:
- Genforschung (Gensequenzierung)
- Erdöl- und Erdgasexploration (Lagerstättensimulation)
- Finanzen (Marktmodelle)
- Engineering (Modellierung physischer Systeme)
- Meteorologie (Wettermodelle)
Für diese Bereiche werden Prozessoren benötigt, die Anweisungen schnell ausführen können. HPC-Anwendungen auf Azure können auf Tausende von Rechenkernen skaliert werden, große Rechenleistung vor Ort erweitern oder als 100 % Cloud-native Lösung laufen. Diese HPC-Lösung umfasst Hauptknoten, Serverknoten und Speicherknoten und wird in Azure ohne Hardwareinfrastruktur ausgeführt, die gewartet werden müsste. Diese Lösung basiert auf den folgenden von Azure verwalteten Diensten: Virtual Machine Scale Sets, Virtual Network und Speicherkonten.
Diese Dienste werden in einer Hochverfügbarkeitsumgebung ausgeführt, gepatcht und unterstützt, sodass Sie sich auf die Lösung selbst konzentrieren können und nicht auf die Umgebung, in der sie ausgeführt werden, konzentrieren müssen. Ein Azure-HPC-System bietet auch den Vorteil, dass Sie benötigte Ressourcen dynamisch hinzufügen bzw. entfernen können.
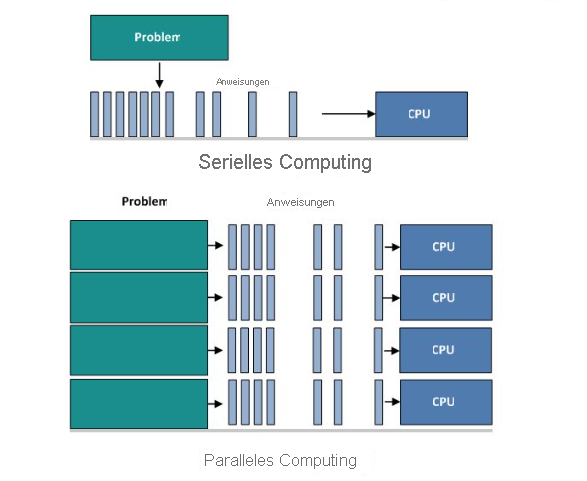
Was ist Parallel Computing auf verteilten Systemen
Parallel Computing ist die gleichzeitige Verwendung mehrerer Berechnungsressourcen, um ein Berechnungsproblem zu lösen:
- Ein Problem wird in diskrete Teile unterteilt, die gleichzeitig gelöst werden können.
- Jeder Teil wird weiter in eine Reihe von Anweisungen aufgeteilt.
- Anweisungen aus jedem Teil, die gleichzeitig auf verschiedenen Prozessoren ausgeführt werden.
- Ein gesamter Kontroll-/Koordinierungsmechanismus wird eingesetzt.
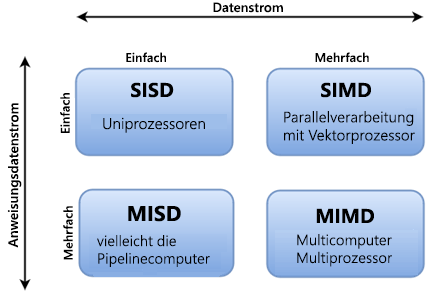
Verschiedene Phasen des Parallelismus
Es gibt verschiedene Möglichkeiten, parallele Computer zu klassifizieren und Flynns Taxonomie ist eine der häufigsten Möglichkeiten, dies zu tun. Es unterscheidet Multi-Prozessor-Computerarchitekturen entsprechend, wie sie entlang der beiden unabhängigen Dimensionen von Anweisungsstream und Datenstrom klassifiziert werden können. Jede dieser Dimensionen kann nur einen von zwei möglichen Zuständen aufweisen: Single oder Multiple.
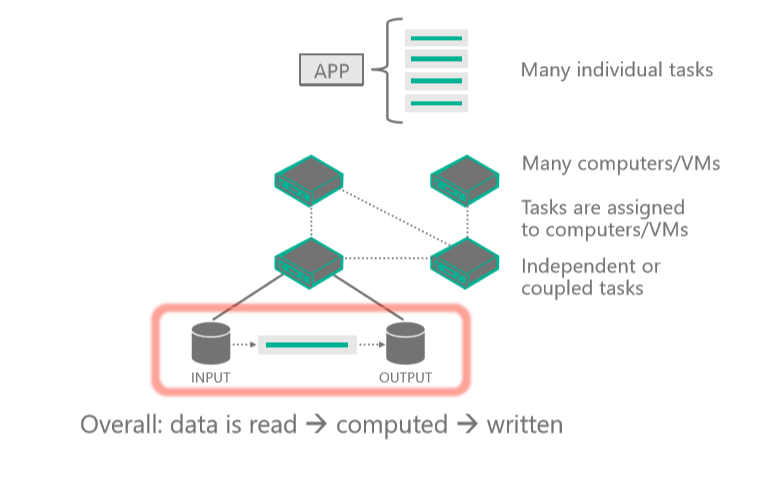
Dieses Diagramm zeigt eine Clientanwendung oder einen gehosteten Dienst, der mit Azure Batch interagiert, um Eingaben hochzuladen, Aufträge zu erstellen, Aufgaben zu überwachen und Ausgaben herunterzuladen:
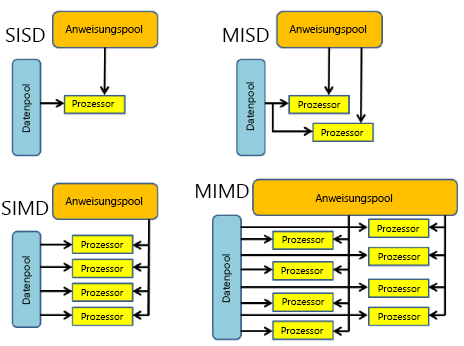
Wir können uns die vier verschiedenen Klassifizierungen genauer ansehen.
| SISD | SIMD | MISD | MIMD |
|---|---|---|---|
| - Serieller (nicht paralleler) Computer. - Einzelne Anweisung: Nur ein Anweisungsdatenstrom wird während eines Uhrzyklus von der CPU ausgeführt - Einzelne Daten: Nur ein Datenstrom wird während eines Uhrzyklus als Eingabe verwendet. - Ältester Computertyp. Beispiele: 1. Frühgenerierungs-Mainframes 2. Minicomputer, Arbeitsstationen 3. Einzelne Prozessorkern-PCs |
- Parallelrechner - Einzelne Anweisung: Alle Verarbeitungseinheiten führen dieselbe Anweisung bei jedem bestimmten Uhrzyklus aus. - Mehrere Daten: Jede Verarbeitungseinheit kann auf einem anderen Datenelement funktionieren. - Am besten geeignet für spezielle Probleme, die durch einen hohen Grad an Regelmäßigkeit gekennzeichnet sind, z. B. Grafiken/Bildverarbeitung. - Die meisten modernen Computer mit Grafikprozessoreinheiten (GPUs) verwenden SIMD-Anweisungen und Ausführungseinheiten. Beispiele: 1. Prozessorarrays: Denkende Maschinen CM-2, MasPar MP-1 und MP-2, ILLIAC IV 2. Vektorpipelines: IBM 9000, Cray X-MP, Y-MP & C90, Fujitsu VP, NEC SX-2, Hitachi S820, ETA10 |
- Parallelrechner - Mehrere Anweisungen: Jede Verarbeitungseinheit arbeitet unabhängig von den Daten über separate Anweisungsströme. - Einzelne Daten: Ein einzelner Datenstrom wird in mehrere Verarbeitungseinheiten eingespeist. - Wenige (falls vorhanden) tatsächliche Beispiele dieser Klasse des parallelen Computers sind jemals vorhanden. Beispiele: 1. Mehrere Frequenzfilter, die auf einem einzelnen Signalstrom ausgeführt werden 2. Mehrere Kryptografiealgorithmen, die versuchen, eine einzelne codierte Nachricht zu knacken |
- Parallelrechner - Mehrere Anweisungen: Jeder Prozessor kann einen anderen Anweisungsstrom ausführen. - Mehrere Daten: Jeder Prozessor kann mit einem anderen Datenstrom arbeiten. - Derzeit die am häufigsten verwendete Art paralleler Computer – die modernsten Supercomputer fallen in diese Kategorie. Beispiele: 1. Die meisten aktuellen Supercomputer 2. Netzwerkierte parallele Computercluster und „Grids“ 3. SMP-Computer mit mehreren Prozessorn 4. Mehrkern-PCs |
Verschiedene Arten von HPC-Aufträgen: Massive parallel vs Eng gekoppelt
Parallele Aufträge haben Berechnungsprobleme, die in kleine, einfache und unabhängige Aufgaben unterteilt sind, die gleichzeitig ausgeführt werden können, oft mit wenig oder keiner Kommunikation zwischen ihnen.
Allgemeine Anwendungsfälle für parallele Aufträge umfassen Risikosimulationen, molekulare Modellierung, Kontextsuche und Logistiksimulationen.
Eng gekoppelte Aufträge verfügen über einen großen freigegebenen Workload, der in kleinere Aufgaben unterteilt ist, die kontinuierlich kommunizieren. Die verschiedenen Knoten im Cluster kommunizieren miteinander, während sie ihre Verarbeitung ausführen.
Allgemeine Anwendungsfälle für eng gekoppelte Aufträge umfassen:
- Numerische Strömungsmechanik
- Wettervorhersage-Modellierung
- Materialsimulationen
- Automobil-Kollisionsemulationen
- Geospatialsimulationen
- Datenverkehrsverwaltung
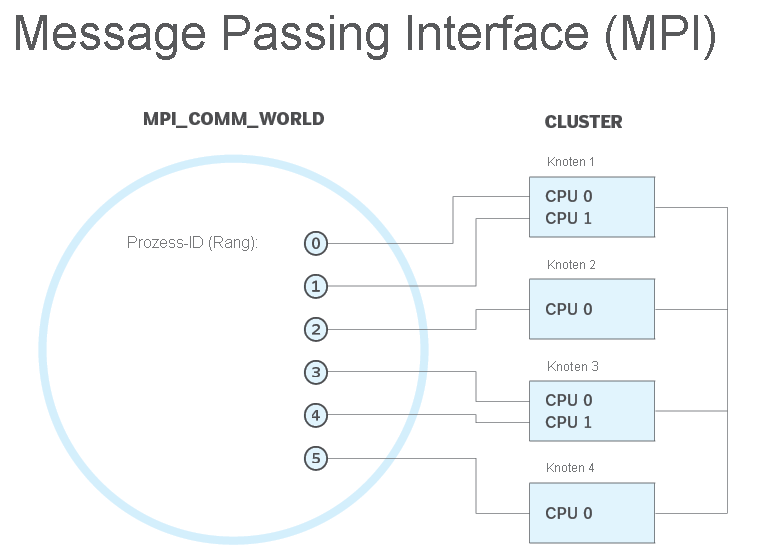
Was ist Nachrichtenübergabeschnittstelle (MPI)
MPI ist ein System, das einen tragbaren und effizienten Standard für die Nachrichtenübergabe bieten soll. Es ist hoch leistungsfähige, tragbare und skalierbare, und wurde entwickelt, um an Netzwerken verschiedener paralleler Computer zu arbeiten.
MPI hat bei der Vernetzung und parallelen Computing auf industrieller und globaler Ebene geholfen und die Arbeit von parallelen Computeranwendungen im großen Maßstab verbessert.
Microsoft MPI-Vorteile:
- Einfache Portierung von vorhandenem Code, der MPICH verwendet.
- Sicherheit basierend auf Active Directory Domain Services.
- Hohe Leistung im Windows-Betriebssystem.
- Binäre Kompatibilität über verschiedene Arten von Verbindungsoptionen.