Funktionsweise von Azure Data Factory
Erfahren Sie mehr über die Komponenten und miteinander verbundenen Systeme von Azure Data Factory und deren Funktionsweise. Mit diesen Kenntnissen können Sie bestimmen, wie Sie Azure Data Factory am besten verwenden können, um die Anforderungen Ihrer Organisation zu erfüllen.
Azure Data Factory ist eine Sammlung miteinander verbundener Systeme, die kombiniert werden, um eine umfassende Datenanalyseplattform bereitzustellen. In dieser Lerneinheit erfahren Sie mehr über die folgenden Azure Data Factory-Funktionen:
- Herstellen einer Verbindung und Sammeln von Daten
- Transformieren und Erweitern
- Continuous Integration und Continuous Delivery (CI/CD) und Veröffentlichung
- Überwachung
Außerdem erfahren Sie mehr über diese wichtigen Komponenten von Azure Data Factory:
- Pipelines
- Aktivitäten
- Datasets
- Verknüpfte Dienste
- Datenflüsse
- Integration Runtimes
Azure Data Factory-Funktionen
Azure Data Factory besteht aus mehreren Funktionen, die kombiniert werden, um Ihren Data Engineers eine vollständige Datenanalyseplattform bereitzustellen.
Herstellen einer Verbindung und Sammeln von Daten
Der erste Teil des Prozesses besteht darin, die erforderlichen Daten aus den entsprechenden Datenquellen zu sammeln. Diese Quellen können sich an unterschiedlichen Orten befinden, einschließlich lokaler Quellen und in der Cloud. Diese Daten können in folgenden Formen vorliegen:
- Strukturiert
- Unstrukturiert
- Teilweise strukturiert
Darüber hinaus können diese unterschiedlichen Daten mit unterschiedlichen Geschwindigkeiten und in unterschiedlichen Abständen eintreffen. Mit Azure Data Factory können Sie die Kopieraktivität verwenden, um Daten aus verschiedenen Quellen in einen zentralen Datenspeicher in der Cloud zu verschieben. Nach dem Kopieren der Daten verwenden Sie andere Systeme, um sie zu transformieren und zu analysieren.
Die Kopieraktivität führt die folgenden allgemeinen Schritte aus:
Daten aus dem Quelldatenspeicher lesen
Die folgenden Aufgaben für die Daten ausführen:
- Serialisierung/Deserialisierung
- Komprimierung/Dekomprimierung
- Spaltenzuordnung
Hinweis
Möglicherweise sind weitere Aufgaben vorhanden.
Schreiben von Daten in den Zieldatenspeicher (als Senke bezeichnet)
Dieser Prozess wird in der folgenden Grafik zusammengefasst:

Transformieren und Erweitern
Wenn Sie die Daten erfolgreich an einen zentralen cloudbasierten Speicherort kopiert haben, können Sie sie nach Bedarf mithilfe von Zuordnungsdatenflüssen in Azure Data Factory verarbeiten und transformieren. Mit Datenflüssen können Sie Datentransformationsgraphen erstellen, die unter Spark ausgeführt werden. Sie müssen jedoch keine Spark-Cluster oder Spark-Programmierung verstehen.
Tipp
Obwohl dies nicht notwendig ist, möchten Sie Ihre Transformationen möglicherweise manuell schreiben. Wenn dies der Fall ist, unterstützt Azure Data Factory externe Aktivitäten zum Ausführen Ihrer Transformationen.
CI/CD und Veröffentlichung
Die Unterstützung für CI/CD ermöglicht es Ihnen, Ihre ETL-Prozesse (Extract, Transform, Load – extrahieren, transformieren, laden) vor der Veröffentlichung inkrementell zu entwickeln und zu liefern. Azure Data Factory ermöglicht CI/CD Ihrer Datenpipelines mit:
- Azure DevOps
- GitHub
Hinweis
Continuous Integration bedeutet, dass jede Änderung, die an Ihrer Codebasis vorgenommen wird, automatisch und so früh wie möglich getestet wird. Der Continuous Delivery-Prozess folgt auf dieses Testen. Änderungen werden dabei in ein Staging- oder Produktionssystem gepusht.
Nachdem Azure Data Factory die Rohdaten aufbereitet hat, können Sie die Daten in die Analyse-Engine laden, auf die Ihre Geschäftsbenutzer über ihre Business Intelligence-Tools zugreifen können, einschließlich:
- Azure Synapse Analytics
- Azure SQL-Datenbank
- Azure Cosmos DB
Monitor
Nachdem Sie Ihre Datenintegrationspipeline erfolgreich erstellt und bereitgestellt haben, ist es wichtig, dass Sie Ihre geplanten Aktivitäten und Pipelines überwachen können. Durch die Überwachung können Sie Erfolgs- und Fehlerraten nachverfolgen. Azure Data Factory unterstützt die Pipelineüberwachung mithilfe einer der folgenden Methoden:
- Azure Monitor
- API
- PowerShell
- Azure Monitor-Protokolle
- Integritätspanels im Azure-Portal
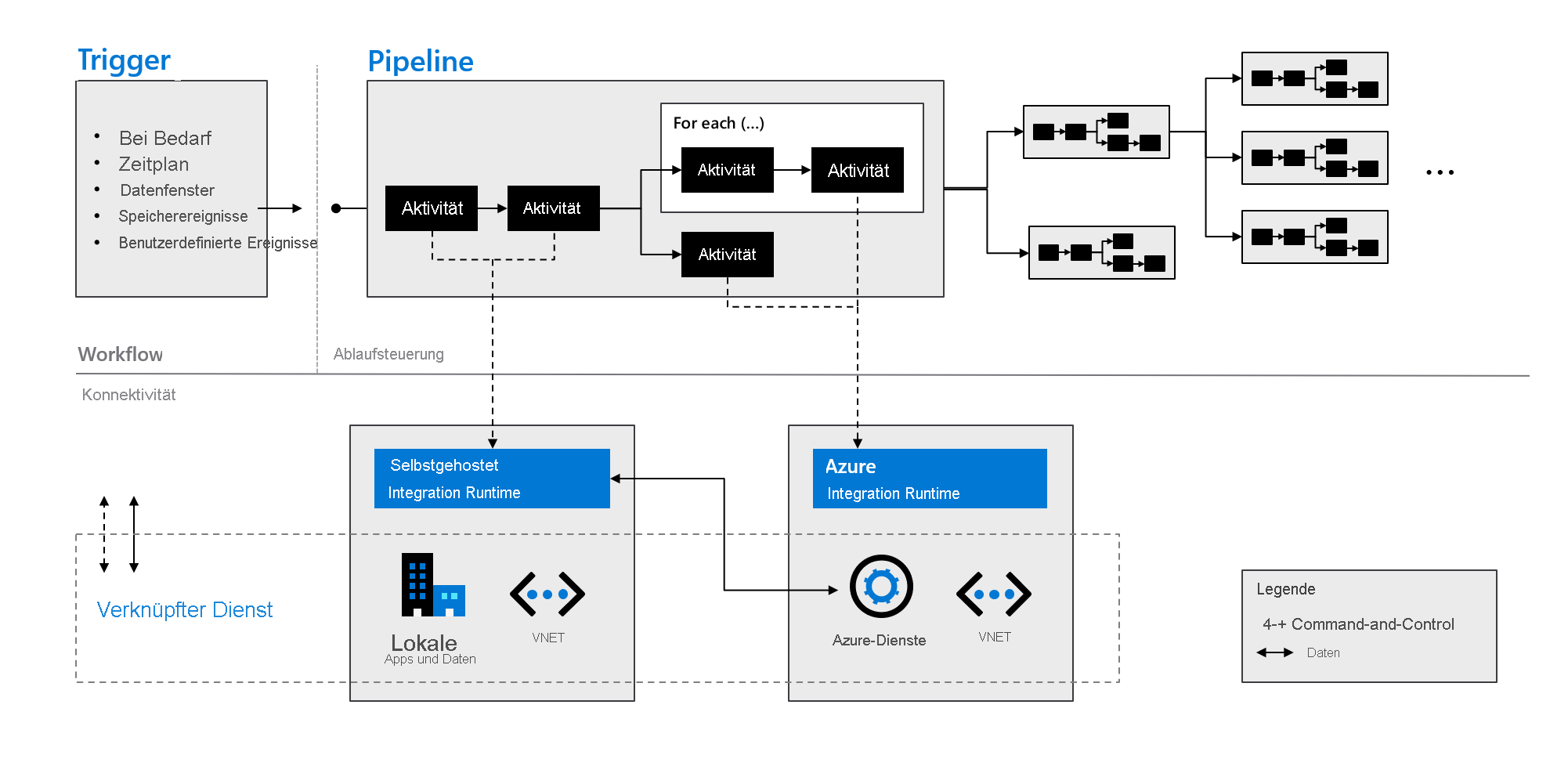
Azure Data Factory-Komponenten
Azure Data Factory besteht aus den in der folgenden Tabelle beschriebenen Komponenten:
| Komponente | BESCHREIBUNG |
|---|---|
| Pipelines | Eine logische Gruppierung von Aktivitäten, die eine bestimmte Arbeitseinheit ausführen. Diese Aktivitäten führen zusammen eine Aufgabe aus. Der Vorteil der Verwendung einer Pipeline besteht in der einfacheren Verwaltung der Aktivitäten als Gruppe anstatt als einzelne Elemente. |
| activities | Ein einzelner Verarbeitungsschritt in einer Pipeline Azure Data Factory unterstützt drei Arten von Aktivitäten: Datenverschiebung, Datentransformation und Steuerung. |
| Datasets | Stellen Datenstrukturen in Ihren Datenspeichern dar. Diese Datasets zeigen bzw. verweisen auf die Daten, die Sie in Ihren Aktivitäten verwenden möchten, z. B. Ein- oder Ausgaben. |
| Verknüpfte Dienste | Definieren die erforderlichen Verbindungsinformationen, die für Azure Data Factory zur Verbindung mit externen Ressourcen wie einer Datenquelle erforderlich sind. Azure Data Factory verwendet diese für zwei Zwecke: zur Darstellung eines Datenspeichers oder einer Computeressource. |
| Datenflüsse | Ermöglichen es Ihren Data Engineers, Datentransformationslogik zu entwickeln, ohne Code schreiben zu müssen. Datenflüsse werden als Aktivitäten in Azure Data Factory-Pipelines ausgeführt, für die erweiterte Apache Spark-Cluster verwendet werden. |
| Integration Runtimes | Azure Data Factory verwendet die Computeinfrastruktur, um die folgenden Datenintegrationsfunktionen für verschiedene Netzwerkumgebungen zur Verfügung zu stellen: Datenflüsse, Datenverschiebungen, Aktivitätsdispatch und SSIS-Paketausführungen (SQL Server Integration Services). In Azure Data Factory stellt eine Integration Runtime die Brücke zwischen der Aktivität und verknüpften Diensten bereit. |
In der folgenden Grafik ist zu sehen, wie diese Komponenten zusammenarbeiten, um eine vollständige und umfassende Plattform für Data Engineers bereitzustellen. Mit Azure Data Factory haben Sie folgende Möglichkeiten:
- Legen Sie Trigger bedarfsgesteuert fest, und planen Sie die Datenverarbeitung basierend auf Ihren Anforderungen.
- Ordnen Sie eine Pipeline einem Trigger zu, oder starten Sie sie bei Bedarf manuell.
- Stellen Sie über Integration Runtimes eine Verbindung mit verknüpften Diensten her, z. B. mit lokalen Apps und Daten oder mit Azure-Diensten.
- Überwachen Sie alle Pipelineausführungen nativ in der Azure Data Factory-Benutzeroberfläche oder mithilfe von Azure Monitor.