Funktionsweise von Azure Data Explorer
In dieser Lerneinheit sehen wir uns an, wie der Azure Daten-Explorer hinter den Kulissen funktioniert, indem wir die wichtigsten Komponenten des Systems besprechen. Dann lernen Sie, wie Sie mit dem Dienst interagieren können, indem Sie eine gängige Workflow erkunden:
- Datenerfassung
- Kusto-Abfragesprache
- Datenvisualisierung
Mit diesem Wissen können Sie entscheiden, ob der Azure Daten-Explorer für Ihre Datenanforderungen geeignet ist.
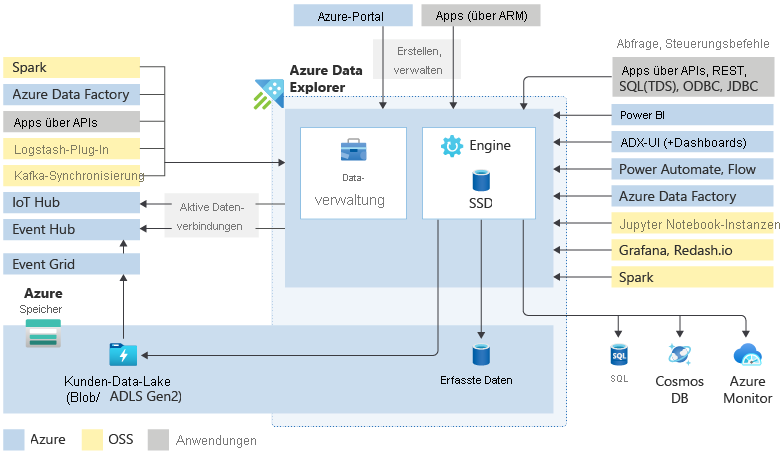
Hauptkomponenten
Ein Azure Data Explorer-Cluster übernimmt die gesamte Arbeit hinsichtlich der Erfassung, Verarbeitung und Abfrage Ihrer Daten. Die Cluster sind je nach Ihren Bedürfnissen automatisch skalierbar. Azure Data Explorer speichert die Daten auch auf Azure Storage und speichert einige dieser Daten auf den Clusterserverknoten zwischen, um eine optimale Abfrageleistung zu erzielen.
Was befindet sich in einem Azure Data Explorer-Cluster?
Jeder Azure Data Explorer-Cluster kann bis zu 10.000 Datenbanken und jede Datenbank bis zu 10.000 Tabellen enthalten. Die Daten in jeder Tabelle werden in Datenshards gespeichert, die auch als Erweiterungen bezeichnet werden. Alle Daten werden basierend auf der Erfassungszeit automatisch indiziert und partitioniert. Im Gegensatz zu einer relationalen Datenbank gibt es keine primären Fremdschlüsseleinschränkungen oder andere Einschränkungen, z. B. Eindeutigkeit. Dieses Design bedeutet, dass Sie große Mengen an unterschiedlichen Daten speichern können. Und aufgrund der Art und Weise, wie die Daten gespeichert werden, können Sie sie schnell abfragen.
Die logische Struktur einer Datenbank ähnelt der von vielen anderen relationalen Datenbanken. Eine Azure Data Explorer-Datenbank kann Folgendes enthalten:
- Tabellen: Diese bestehen aus mehreren Spalten. Jede Spalte verfügt über einen von neun verschiedenen Datentypen.
- Externe Tabellen: Dies sind Tabellen, deren zugrunde liegender Speicher sich an anderen Speicherorten wie Azure Data Lake befindet.
Allgemeiner Workflow
Wenn Sie mit dem Azure Daten-Explorer arbeiten, durchlaufen Sie im Allgemeinen die folgende Workflow: Zuerst geben Sie Ihre Daten ein, dass sie im System vorhanden sind. Anschließend analysieren Sie Ihre Daten. Als Nächstes visualisieren Sie die Ergebnisse Ihrer Analyse. Sie können sich jederzeit auch mit den Datenverwaltungsfunktionen befassen. Diese Arbeit mit Azure Data Explorer erfolgt über die Interaktion mit dem Cluster. Sie können auf diese Ressourcen entweder über die Weboberfläche oder über SDKs zugreifen.
Wie kann ich meine Daten in Azure Data Explorer integrieren?
Die Datenerfassung ist der Prozess, mit dem Datensätze aus einer Quelle oder mehreren Quellen in eine Tabelle in Azure Data Explorer geladen werden. Die weitere Datenbearbeitung umfasst den Schemaabgleich sowie die Organisation, Indizierung, Codierung und Komprimierung der Daten. Der Data Manager committet anschließend die Datenerfassung in der-Engine, wo sie dann für Abfragen bereitstehen.
Zusätzlich zum nativen Weboberflächen-Assistenten stehen verschiedene Eingabewerkzeuge zur Verfügung. Einschließlich der verwalteten Pipelines, Event Grid, IoT Hub und Azure Data Factory. Sie können Connectors und Plug-Ins wie das Logstash-Plug-In, den Kafka-Connector, Power Automate und den Apache Spark-Connector verwenden. Sie können die programmgesteuerte Erfassung auch mit SDKs oder LightIngest verwenden.
Daten können in zwei Modi erfasst werden: Batchverarbeitung oder Streaming. Die Batchverarbeitungserfassung ist für hohen Erfassungsdurchsatz und schnelle Abfrageergebnisse optimiert. Durch die Streamingerfassung sinkt die Latenz bei kleinen Datensätzen pro Tabelle auf nahezu Echtzeit.
Wie analysiere ich meine Daten?
Azure Data Explorer verwendet die proprietäre Kusto-Abfragesprache (Kusto Query Language, KQL) zum Analysieren von Daten. Sie wird häufig in Microsoft-Produkten (Azure Monitor: Log Analytics und Application Insights, Microsoft Sentinel und Microsoft Defender XDR) verwendet. KQL ist für schnelles, vielfältiges Erkunden von Big Data optimiert. Abfragen verweisen auf Tabellen, Sichten, Funktionen und andere tabellarische Ausdrücke. Einschließlich Tabellen in verschiedenen Datenbanken oder sogar Clustern. Sie können Abfragen über die Weboberfläche, verschiedene Abfragetools oder mit einem der Azure Daten-Explorer SDKs durchführen.
Wie funktioniert die Kusto-Abfragesprache?
Die Kusto-Abfragesprache ist eine ausdrucksstarke, intuitive und äußerst produktive Abfragesprache. Sie bietet einen reibungslosen Übergang von einfachen Einzeilern zu komplexen Datenverarbeitungsskripts und unterstützt das Abfragen strukturierter, teilweise strukturierter und unstrukturierter Daten (Textsuche). Die Abfragesprache umfasst eine Vielzahl von Operatoren und Funktionen (Aggregation, Filterung, Zeitreihenfunktionen, Geofunktionen, Verknüpfungen, Vereinigungen usw.). KQL unterstützt cluster- und datenbankübergreifende Abfragen und bietet umfangreiche Analysefeatures (JSON, XML usw.). Darüber hinaus unterstützt die Sprache nativ erweiterte Analysen.
Wie kann ich meine Abfrageergebnisse anzeigen?
Die Azure Data Explorer-Webbenutzeroberfläche wurde unter Berücksichtigung von Big Data entwickelt, sodass Sie Abfragen ausführen und Dashboards erstellen können. Es unterstützt eine Anzeige von bis zu 500.000 Datensätzen und Tausenden von Spalten. Es ist hochgradig skalierbar und bietet viele Funktionen, mit denen Sie schnell Erkenntnisse aus Ihren Daten gewinnen können. Sie können auch verschiedene visuelle Darstellungen Ihrer Daten in Ihren Azure Data Explorer-Dashboards verwenden. Sie können Ihre Ergebnisse auch mit nativen Connectors in einigen der führenden Visualisierungsdiensten anzeigen, die heute verfügbar sind, z. B. Power BI und Grafana. Azure Data Explorer verfügt auch über ODBC- und JDBC-Connectorunterstützung für Tools wie Tableau und Qlik.
Wie verwalte ich meine Daten?
Administrator*innen möchten verschiedene Wartungs- und Richtlinienaufgaben für ihre Azure Daten-Explorer-Cluster durchführen. Steuerungsbefehle geben ihnen die Möglichkeit, dies zu tun. Mit Hilfe von Steuerungsbefehlen können sie neue Cluster oder Datenbanken erstellen, Datenverbindungen herstellen, automatische Skalierung durchführen und Cluster-Konfigurationen anpassen. Sie können auch Entitäten, Metadatenobjekte, die Verwaltung von Berechtigungen und Sicherheitsrichtlinien kontrollieren und ändern. Darüber hinaus können sie materialisierte Ansichten (ständig aktualisierte gefilterte Ansichten anderer Tabellen), Funktionen (gespeicherte Funktionen und benutzerdefinierte Funktionen) und die Aktualisierungsrichtlinie (Funktionen, die nach dem Ingestion ausgelöst werden) ändern.
Steuerungsbefehle werden direkt in der Engine mithilfe der Webbenutzeroberfläche, des Azure-Portals, verschiedener Abfragetools oder mit einem der Azure Data Explorer-SDKs ausgeführt.