Funktionsweise von HDInsight
HDInsight ist ein verteiltes Datenverarbeitungssystem in der Cloud, das standardmäßig hoch verfügbar und sicher ist. Das Herzstück dieses Systems bildet Apache Hadoop. Apache Hadoop umfasst zwei Kernkomponenten: HDFS (Hadoop Distributed File System) für die Speicherung und Apache Hadoop YARN (Yet Another Resource Negotiator) für die Verarbeitung. Darüber hinaus können Sie ein einfaches MapReduce-Programmiermodell verwenden, um Daten zu verarbeiten und zu analysieren. MapReduce ist zum einen sehr einfach einzurichten und ermöglicht Ihnen zum anderen die Kontrolle Ihrer Kosten über das Feature für die automatische Skalierung.
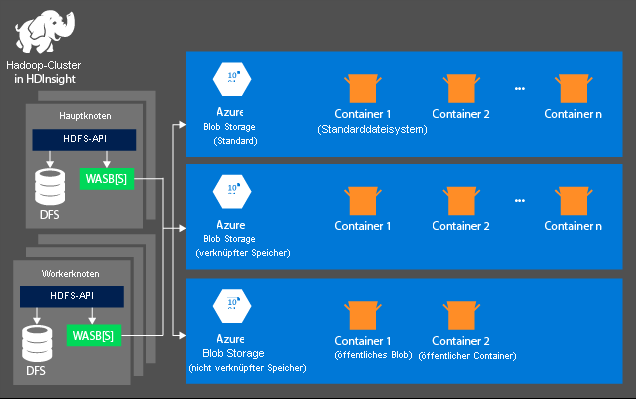
Storage
Der Speicherbereich wird nicht automatisch erstellt, wenn Sie einen HDInsight-Cluster bereitstellen. Stattdessen wird er von einem HDFS-konformen System bereitgestellt, z. B. Azure Storage oder Azure Data Lake. Das Entkoppeln von Speicher- und Verarbeitungsschicht ermöglicht Ihnen das sichere Löschen eines HDInsight-Clusters, der für Berechnungen verwendet wird, ohne dass dabei die Benutzerdaten verloren gehen. Wenn Sie einen HDInsight-Cluster hinzufügen, müssen Sie ein Standarddateisystem definieren. Sie können Dateisysteme nach Bedarf verknüpfen und trennen, um die Größe des Speichers anzupassen.
Die folgenden Informationen beziehen sich speziell auf HDInsight 3.6 und höher. Bei der Erstellung des HDInsight-Clusters können Sie mit einigen wenigen Ausnahmen Azure Storage oder Azure Data Lake Storage Gen2 als Standarddateisystem auswählen. Durch die Bereitstellung eines Standarddateisystems wird sichergestellt, dass bei der Suche nach Dateien relative Dateiverweise aufgelöst werden können. Für Azure Storage sollten Sie einen Blobcontainer als Standarddateisystem angeben.
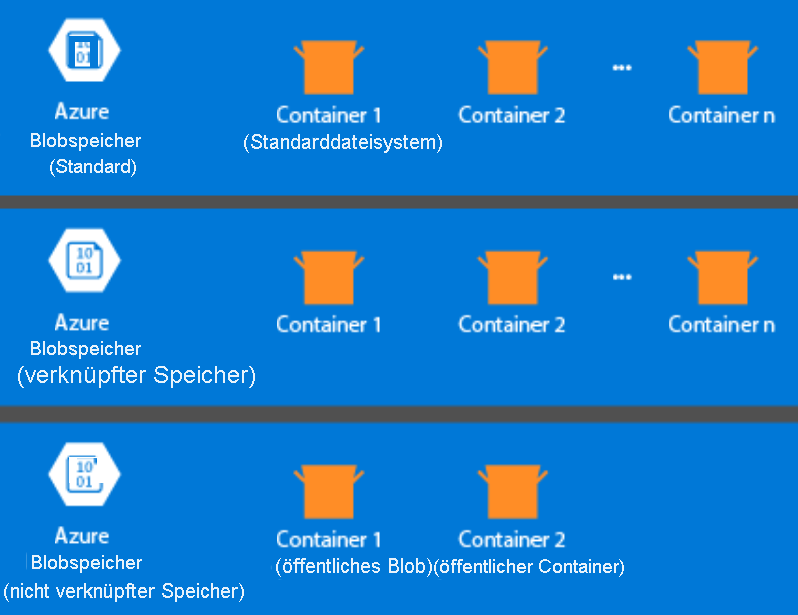
In den meisten Systemen wird Azure Data Lake Storage Gen2 verwendet. Ein solches Setup verwendet die Kernfeatures eines Dateisystems, die mit Hadoop, der Microsoft Entra-Integration und POSIX-basierten Zugriffssteuerungslisten (Access Control Lists, ACLs) kompatibel sind. Sie können Azure Blob Storage aus Gründen der Abwärtskompatibilität verwenden. Es wird jedoch dringend empfohlen, wenn möglich Azure Data Lake Storage Gen2 zu verwenden.
Verarbeitung
Beim Verarbeiten von Daten wird der Computeteil eines Hadoop-Clusters in HDInsight in zwei logische Bereiche aufgeteilt: Hauptknoten (früher auch als Master bezeichnet) und Workerknoten. Der Hauptknoten ist für die Annahme und Verwaltung von Clientanforderungen zuständig und übergibt die Anforderung dann an die Workerknoten, die die eigentliche Verarbeitung der Daten ausführen. Es gibt in der Regel zwei Hauptknoten. Ein aktiver Hauptknoten verwaltet die Clientverbindungen. Ein zweiter, passiver Hauptknoten stellt die Resilienz sicher, falls der primäre Hauptknoten offline geschaltet wird.
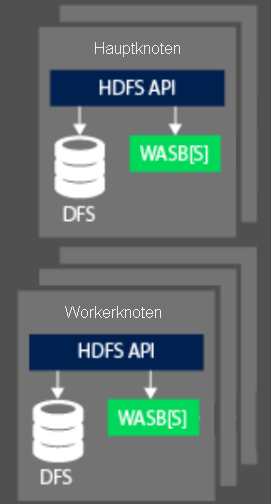
Der Workerknoten ist für die Verarbeitung der Daten zuständig, die ihm vom Hauptknoten zugewiesen wurden. Die verwalteten Daten sind davon abhängig, wie das MapReduce-Programmiermodell die Arbeit mit den Daten definiert hat und wie der Hauptknoten die Arbeit zuordnet. Sowohl Haupt- als auch Workerknoten können direkt mit einem lokal bereitgestellten verteilten Dateisystem (Distributed File System, DFS) verbunden sein oder auf Daten zugreifen, die in Azure Blob Storage oder-Azure Data Lake gespeichert sind.
Aus OSS-Sicht werden die Funktionen zur Ressourcenverwaltung eines HDInsight-Clusters von YARN ausgeführt. Dieser Dienst verwaltet die Ressourcen und die Auftragsplanung beim Verarbeiten der Daten. Er befindet sich zwischen dem HDFS und dem Berechnungssystem des HDInsight-Clusters. Der Dienst arbeitet mit anderen OSS-Technologien zusammen, um sicherzustellen, dass die erforderlichen Ressourcen zur Verarbeitung des HDInsight-Auftrags verfügbar sind. YARN arbeitet mit dem Hauptknoten zusammen, um den Auftrag auf die Workerknoten des Clusters zu verteilen, damit die Datenverarbeitungsaufträge parallel verarbeitet werden.
HDFS, YARN und MapReduce sind die drei wichtigsten Dienste, die für Hadoop in HDInsight erforderlich sind. In den meisten Fällen kommen noch weitere OSS-Technologien zum Einsatz, um die Erstellung einer Lösung zu vereinfachen. Beispielsweise können Sie Hive als Abstraktionsschicht verwenden. Diese kann auf MapReduce aufsetzen, sodass Sie SQL-artige Sprachkonstrukte schreiben können, um eine Ad-hoc-Datenverarbeitung und -Analyse durchzuführen. Sie können auch Apache Ambari verwenden, um die Überwachung im HDInsight-Cluster durchzuführen.