Anwendungen skalierbar machen
Nachdem Sie sich nun mit den Grundlagen der Vorbereitung auf ein Wachstum vertraut gemacht haben und die Faktoren kennen, die bei der Kapazitätsplanung berücksichtigt werden müssen, können Sie Ihre Anwendungen so skalierbar wie möglich gestalten.
Architektur-Überprüfungen
Denken Sie daran, dass Sie regelmäßig die Architektur Ihrer Systeme überprüfen sollten.
Sie wissen, dass Sie Verfahren wie Infrastructure as Code anwenden können, um die Bereitstellung Ihrer Cloudressourcen zu verbessern. Sie aktualisieren und verbessern den Anwendungscode regelmäßig, und Sie sollten dies auch mit den zugrunde liegenden Plattformressourcen tun.
Mithilfe einer Architektur-Überprüfung können Sie die Bereiche identifizieren, die optimiert werden müssen.
Das Azure Architecture Center verfügt über zahlreiche Ressourcen, die Sie beim Entwerfen Ihrer Anwendungen in der Cloud unterstützen, und es gibt viele Empfehlungen für die Skalierbarkeit, die Sie im Leitfaden zur Anwendungsarchitektur unter folgendem Link finden:
Szenario: Tailwind Traders-Architektur
Der erste Schritt besteht darin, die Architektur und die Anwendung zu evaluieren – um nicht nur die Schwächen, sondern auch die Stärken zu identifizieren. Was ist gut daran?
Sehen Sie sich noch einmal das Szenario der vorherigen Einheit an. Nachstehend wird noch einmal das Diagramm der Architektur der Organisation gezeigt.
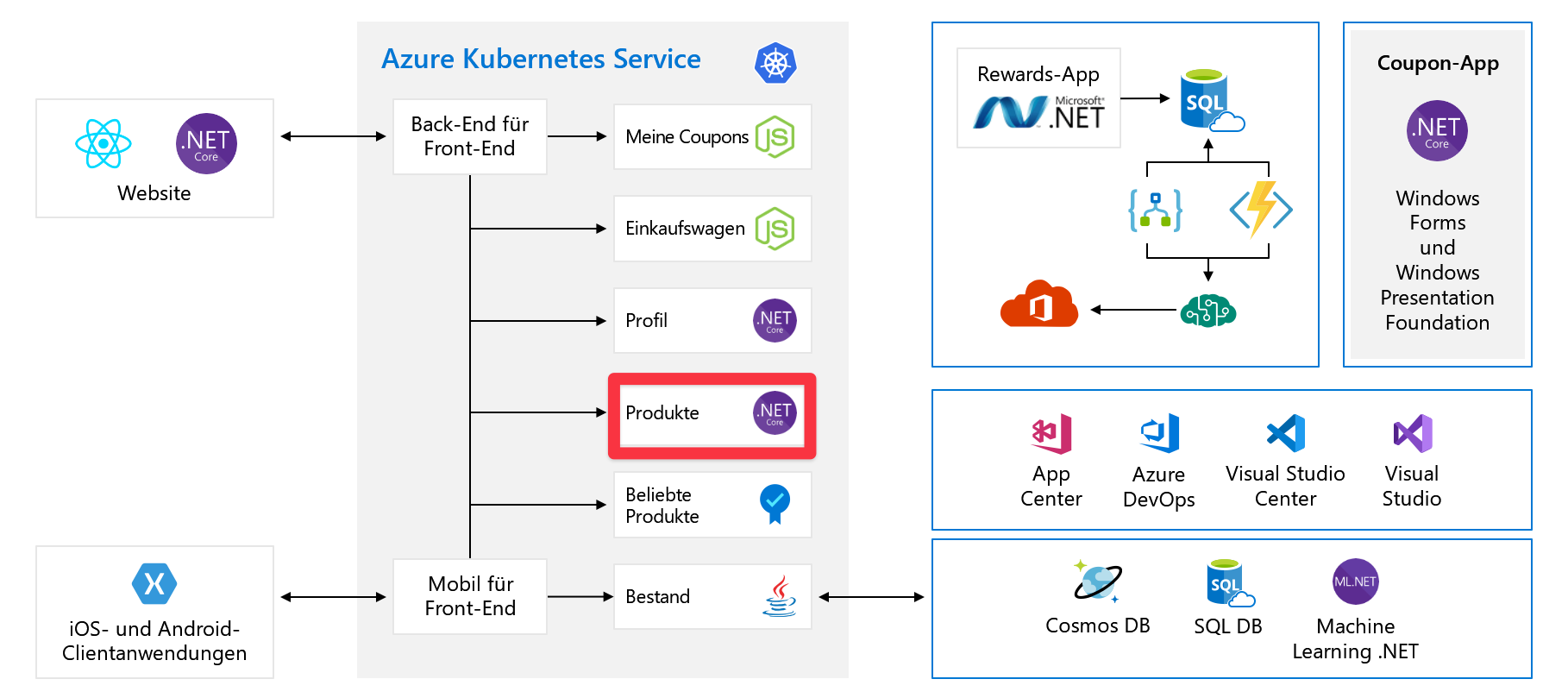
Sie haben die Anwendung in kleinere Microservices zerlegt, und einige dieser Dienste liegen als Container in Azure Kubernetes Service vor oder werden möglicherweise auf VMs oder App Service ausgeführt. Sie verwenden einige inhärent skalierbare Dienste wie z. B. Functions und Logic Apps.
Diese Änderung ist gut, aber es gibt einige Verbesserungen, die die Skalierbarkeit der Anwendung noch erhöhen würden. Konzentrieren Sie sich als Beispiel jetzt auf den Products-Dienst. Im Diagramm wird der Dienst „Produkte“ in Kubernetes ausgeführt, aber im Rahmen dieser Erläuterungen wird davon ausgegangen, dass er auf einer VM in Azure ausgeführt wird. Die Skalierungskonzepte, möglicherweise mit einer leicht abweichenden Implementierung, können auf Anwendungen angewendet werden. Dabei spielt es keine Rolle, ob diese auf Servern, in App Service oder Containern ausgeführt werden.
Der Produktdienst wird zurzeit auf einer einzelnen VM ausgeführt, die mit einer einzelnen Azure SQL-Datenbank verbunden ist. Sie müssen diese VM für die Aufskalierung aktivieren. Mit Azure VM-Skalierungsgruppen können Sie identische VMs mit Lastenausgleich erstellen und verwalten. Da Sie nun über mehr als eine VM verfügen, müssen Sie einen Lastenausgleich implementieren, um den Datenverkehr auf die VMs zu verteilen.
VM-Skalierungsgruppen
Die Anwendung von VM-Skalierungsgruppen anstelle von einzelnen VMs bietet verschiedene Vorteile:
- Die automatische Skalierung kann basierend auf Hostmetriken, gastspezifischen Metriken, Anwendungsdaten oder nach einem Zeitplan durchgeführt werden.
- Sie können Verfügbarkeitszonen nutzen, bei denen es sich um unabhängige, eigenständige Rechenzentren innerhalb einer Azure-Region handelt. Mit der Unterstützung von Verfügbarkeitszonen können Sie Ihre VMs auf mehrere Verfügbarkeitszonen verteilen, wodurch Ihre Anwendung zuverlässiger wird und vor Rechenzentrumsausfällen geschützt ist. Neue Instanzen in einer Skalierungsgruppe werden automatisch gleichmäßig auf Verfügbarkeitszonen verteilt.
- Das Hinzufügen eines Load Balancers wird vereinfacht. VM-Skalierungsgruppen unterstützen die Verwendung von Azure Load Balancer für die einfache Verteilung von Schicht-4-Datenverkehr. Sie unterstützen auch Azure Application Gateway für eine erweiterte Verteilung von Schicht-7-Datenverkehr und SSL-Terminierung.
Vor der Implementierung von Skalierungsgruppen müssen Sie einige wichtige Faktoren berücksichtigen. Insbesondere:
- Vermeiden Sie eine Bindung der Instanz, damit kein Client auf ein bestimmtes Back-End festgelegt ist.
- Entfernen Sie persistente Daten von der VM, und speichern Sie sie an einem anderen Ort, z. B. in Azure Storage oder in einer Datenbank.
- Denken Sie bei der Entwicklung an das Herunterskalieren. Außerdem ist es wichtig, dass Ihre Anwendung auch leicht wieder herunterskaliert werden kann. Sie muss nicht nur das Hinzufügen zusätzlicher Instanzen zum Serverpool ermöglichen, die den Datenverkehr verarbeiten, sondern bei einer Abnahme der Arbeitslast auch sofort Instanzen beenden können. Dieser Aspekt des Herunterskalierens wird häufig übersehen.
Entkopplung
Sie haben weitere VMs mit Skalierungsgruppen hinzugefügt. Das Aufskalieren ist die typische Reaktion auf eine Skalierungsanforderung. Sie können jedoch nur basierend auf einer einzelnen Metrik skalieren, und diese Reaktion ist möglicherweise nicht für alle Aufgaben relevant, die von Ihrem Produktdienst durchgeführt werden.
In unserem Szenario hat der Produktdienst einen Auftrag. Er lädt ein Produktbild hoch. Anschließend wird das Bild transcodiert und in unterschiedlichen Größen gespeichert, z. B. für Miniaturansichten oder Katalogabbildungen. Die Bildverarbeitung ist rechenintensiv, aber die allgemeine Verwendung ist speicherintensiv.
Die Bildverarbeitung ist eine asynchrone Aufgabe, die in einen Hintergrund-Auftrag aufgebrochen werden kann. Dazu können Sie Ihren Bildverarbeitungsdienst über eine Warteschlange entkoppeln. Entkoppeln bedeutet, dass Sie beide Dienste unabhängig voneinander skalieren können – den einen basierend auf dem Arbeitsspeicher (Produktdienst), den anderen basierend auf der CPU (Bildverarbeitungsdienst) oder sogar der Warteschlangenlänge. Eine andere Skalierungsgruppe kann die Nachrichten anschließend nutzen und die Bilder verarbeiten.
Skalieren mit Warteschlangen
Azure verfügt über zwei Arten von Warteschlangen-Angeboten:
- Azure Service Bus-Warteschlangen ist ein fortgeschritteneres Warteschlangenangebot, das Teil des umfassenderen Azure Service Bus-Produkts ist, das Pub/Sub und erweiterte Integrationsmuster bietet.
- Azure Storage-Warteschlangen ist eine einfache REST-basierte Warteschlangenschnittstelle, die auf Azure Storage aufsetzt. Sie bietet zuverlässiges, beständiges Messaging.
Ihre Anforderungen in diesem Szenario sind einfach, sodass Sie Azure Storage-Warteschlangen verwenden können. Ihre Produktebene muss überhaupt nicht skaliert werden, da Sie diese Hintergrundaufgabe entkoppelt haben.
In-Memory-Caching
Eine weitere Möglichkeit, die Leistung Ihrer Anwendung zu verbessern, besteht darin, In-Memory-Caching zu implementieren.
Nun wissen Sie, dass die Leistung nicht genau mit der Skalierbarkeit identisch ist, dass Sie aber durch eine Verbesserung der Leistung Ihrer Anwendung auch die Auslastung anderer Ressourcen reduzieren können. Diese Optimierung bedeutet, dass Sie möglicherweise nicht so bald skalieren müssen.
Azure Cache for Redis ist ein verwaltetes Redis-Angebot. Redis kann für viele Muster und Anwendungsfälle verwendet werden. Für den Produktdienst in diesem Szenario implementieren Sie wahrscheinlich das cachefremde Muster. In diesem Muster laden Sie bei Bedarf Elemente aus der Datenbank in den Cache, damit Ihre Anwendung leistungsfähiger und die Last für die Datenbank verringert wird.
Redis kann auch als Messaging-Warteschlange zum Zwischenspeichern von Webinhalten oder Benutzersitzungen verwendet werden. Diese Art des Zwischenspeicherns kann für andere Dienste im System besser geeignet sein, z. B. den Warenkorbdienst, in dem Sie Warenkorbdaten pro Sitzung in Redis speichern können, anstatt ein Cookie zu verwenden.
Skalieren der Datenbank
Nachdem Sie die Skalierbarkeit Ihrer Rechenressourcen erhöht haben, geht es nun um Ihre Datenbank. In diesem Szenario verwenden Sie Azure SQL-Datenbank, bei der es sich um ein verwaltetes SQL Server-Angebot von Azure handelt.
Relationale Datenbanken sind schwieriger zu skalieren als nicht relationale Datenbanken. Um Ihre Datenbank zu skalieren, können Sie zunächst die Größe der Datenbank hochskalieren. Diese Größenänderung kann ganz einfach mit einer durchschnittlichen Downtime von weniger als vier Sekunden durchgeführt werden. Dazu kann entweder ein einfacher API-Aufruf in Azure SQL oder ein Schieberegler im Portal verwendet werden.
Wenn diese Größenanpassung Ihre Anforderungen nicht erfüllt, kann es je nach Eigenschaften des Datenverkehrs sinnvoll sein, die Lesevorgänge in der Datenbank aufzuskalieren. Auf diese Weise können Sie den Lesedatenverkehr an Ihr Lesereplikat weiterleiten.
Hinweis
Wenn Sie bei Azure SQL die Ebenen „Premium“ oder „unternehmenskritisch“ verwenden, ist die Leseskalierung standardmäßig aktiviert. Sie kann nicht für die Basic- oder Standard-Ebene aktiviert werden.
Diese Änderung muss im Code implementiert werden. Gehen Sie dazu folgendermaßen vor:
#Azure SQL Connection String
#Master Connection String
ApplicationIntent=ReadWrite
#Read Replica Connection String
ApplicationIntent=ReadOnly
#Full Example
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Aktualisieren Sie das Attribut ApplicationIntent in der Verbindungszeichenfolge Ihrer Datenbank, um festzulegen, mit welchem Server eine Verbindung hergestellt werden soll. Verwenden Sie ReadOnly, wenn Sie eine Verbindung mit dem Replikat herstellen möchten, oder ReadWrite, wenn Sie eine Verbindung mit dem Master herstellen möchten.
Da dies im Befehl implementiert werden muss, ist es möglicherweise keine geeignete Lösung für Ihre Situation. Was ist zu tun, wenn jeder einzelne Produktdienst Lese-und Schreibzugriff benötigt?
In diesem Fall ist die Aufskalierung der SQL-Datenbank über Sharding vielleicht eine Möglichkeit.
Datenbank-Sharding
Wenn die Datenbankressourcen nach dem Hochskalieren oder der Implementierung von Lesereplikaten die Anforderungen Ihres Systems nicht erfüllen, ist die nächste Option das Sharding.
Mit Sharding werden große Mengen identisch strukturierter Daten auf mehrere unabhängige Datenbanken verteilt. Sharding kann aus verschiedenen Gründen erforderlich sein. Beispiel:
- Die Gesamtmenge der Daten ist zu groß, um auf eine einzelne Datenbank zu passen.
- Der Transaktionsdurchsatz des gesamten Workloads überschreitet die Fähigkeiten einer einzelnen Datenbank.
- Separate Tenants müssen sich wegen der Compliance auf verschiedenen physischen Datenbanken befinden (bei dieser Anforderung geht es weniger um die Skalierung, aber es handelt sich um eine weitere Situation, in der Sharding verwendet wird).
Die Anwendung fügt die relevanten Daten dem entsprechenden Shard hinzu, sodass das System über die Einschränkungen der einzelnen Datenbanken hinaus skalierbar ist.
Azure SQL bietet die Azure-Tools für elastische Datenbanken. Diese Tools unterstützen Sie beim Erstellen, Verwalten und Abfragen von Sharding-Datenbanken in Azure aus ihrer Anwendungslogik.