Was ist Skalierbarkeit?
In der Geschäftswelt kann ein Wachstum von Vorteil sein. Wenn das Wachstum jedoch zu schnell vonstatten geht und Sie nicht ausreichend darauf vorbereitet sind, kann es Probleme verursachen. Beispielsweise kann sich die Zuverlässigkeit von Anwendungen und Diensten verringern, die nicht auf eine beträchtliche Erhöhung des Datenverkehrs ausgelegt sind.
Für Ihre Kunden und Benutzer ist ein Ausfall ein Ausfall. Sie wissen nicht bzw. es ist ihnen egal, ob sie nicht auf Ihre Website zugreifen können, weil der Code Fehler enthält oder weil zu viele andere Benutzer gleichzeitig versuchen, ihre korrekt programmierte Website zu verwenden.
Die Skalierbarkeit ist die Möglichkeit, sich an höhere oder geänderte Anforderungen anzupassen. Ihre Anwendungen und Dienste müssen in der Lage sein, größere Workloads zu bewältigen, um das Wachstum zu unterstützen. Skalierbare Anwendungen können eine im Zeitverlauf zunehmende Anzahl von Anforderungen verarbeiten, ohne dass sich dies negativ auf die Verfügbarkeit oder Leistung auswirkt.
In dieser Lerneinheit erfahren Sie mehr über die Beziehung zwischen Skalierbarkeit und Zuverlässigkeit und die Rolle der Kapazitätsplanung beim Erreichen der Skalierbarkeit. Außerdem werden kurz einige grundlegende Konzepte und Begriffe im Zusammenhang mit der Skalierung erläutert.
Die Beziehung zwischen Skalierbarkeit und Zuverlässigkeit
Die gute Nachricht ist: Wenn Sie die Skalierbarkeit Ihrer Anwendung erhöhen, steigern Sie auch ihre Zuverlässigkeit. Wenn das System beispielsweise automatisch skaliert wird, führt ein Komponentenfehler auf einer einzelnen VM dazu, dass der Dienst für die automatische Skalierung eine andere Instanz bereitstellt, um die Mindestanforderungen an die VM-Anzahl zu erfüllen. Ihr System wird zuverlässiger. In einem anderen Beispiel verwenden Sie einen übergeordneten Dienst wie Azure Storage, der von Natur aus skalierbar ist. Der Dienst ist so konzipiert, dass er selbst im Falle eines Speicherproblems zuverlässig ist und die Daten repliziert.
Hier ist eine Analogie: Denken Sie an Rampen für die Barrierefreiheit, die Sie oft an Gebäudeeingängen sehen. Sie wurden ursprünglich entwickelt, um den Zugang für Menschen im Rollstuhl zu ermöglichen. Sie dienen genau diesem Zweck. Sie werden darüber hinaus auch von Eltern mit Buggys oder Kinderwagen und von Kindern genutzt, für die die Stufen zu groß bzw. zu weit auseinander sind. Diese Verwendung kann als sekundärer Nutzen bezeichnet werden.
Die Zuverlässigkeit ist oft ein sekundärer Nutzen der Skalierbarkeit. Wenn Sie Ihre Systeme so entwerfen, dass sie skalierbar sind, sind sie wahrscheinlich auch zuverlässiger.
Skalierbarkeit und Kapazitätsplanung
Die Kapazitätsplanung umfasst die Ermittlung der Ressourcen, die Sie benötigen, um sowohl aktuelle als auch zukünftige Anforderungen zu erfüllen. Im Zuge der Planung analysieren Sie Ihre aktuelle Ressourcennutzung und prognostizieren dann das zukünftige Wachstum.
Um zukünftige Kapazitätsanforderungen zu schätzen, sollten Sie folgende Faktoren berücksichtigen:
- Erwartetes Geschäftswachstum
- Periodische Schwankungen (saisonbedingt usw.)
- Anwendungseinschränkungen
- Identifizierung von Engpässen und einschränkenden Faktoren
Außerdem müssen Sie die Servicelevelziele festlegen, damit Sie einen Plan für die Kapazitätsverwaltung erstellen können, der diese Ziele zuverlässig erfüllt oder übertrifft, wenn sich die Arbeitsauslastung und die Umgebung ändern.
Die Kapazitätsplanung ist ein iterativer Prozess. In diesem Modul erfahren Sie, wie Sie die Ressourcenanforderungen für Anwendungskomponenten ermitteln.
Konzepte und Terminologie
Bevor Sie die Konzepte und Strategien verstehen können, die in diesem Modul erläutert werden, benötigen Sie zunächst Kenntnisse einiger grundlegender Konzepte und Begriffe im Zusammenhang mit der Skalierung.
- Hochskalieren: Vergrößern einer Komponente, um höhere Workloads zu bewältigen. Dies wird auch als vertikale Skalierung bezeichnet.
- Aufskalieren: Hinzufügen von weiteren Komponenten oder Ressourcen, um die Arbeitslast auf eine verteilte Architektur auszuweiten. Dazu gehört z. B. die Verwendung einer einfachen Architektur mit mehreren Back-Ends hinter einem Satz von Front-Ends. Wenn die Arbeitslast zunimmt, werden weitere Back-End-Server (und Front-End-Server) hinzugefügt. Dies wird auch als horizontale Skalierung bezeichnet.
- Manuelle Skalierung: Es ist ein Benutzereingriff erforderlich, um die Ressourcenmenge zu erhöhen.
- Automatische Skalierung: Das System passt den Umfang der Ressourcen basierend auf der Last automatisch an. Nur zur Klarstellung: Die Ressourcenmenge wird sowohl erhöht als auch verringert, je nachdem, ob die Arbeitslast höher oder niedriger ausfällt.
- DIY-Skalierung: Do-it-yourself-Skalierung, bei der die automatische Skalierung konfiguriert werden muss.
- Inhärente Skalierung: Dienste, die so erstellt wurden, dass sie skalierbar sind und diese Skalierung im Hintergrund ohne Benutzereingriff durchführen. Aus ihrer Perspektive sehen sie nahezu unendlich skalierbar aus, da Sie einfach mehr Ressourcen verwenden können, ohne sie manuell bereitstellen zu müssen.
Tailwind Traders-Architektur
In diesem Modul verwenden wir eine Beispielarchitektur eines fiktiven Hardwareherstellers namens Tailwind Traders. Ihre E-Commerce-Plattform sieht wie folgt aus:
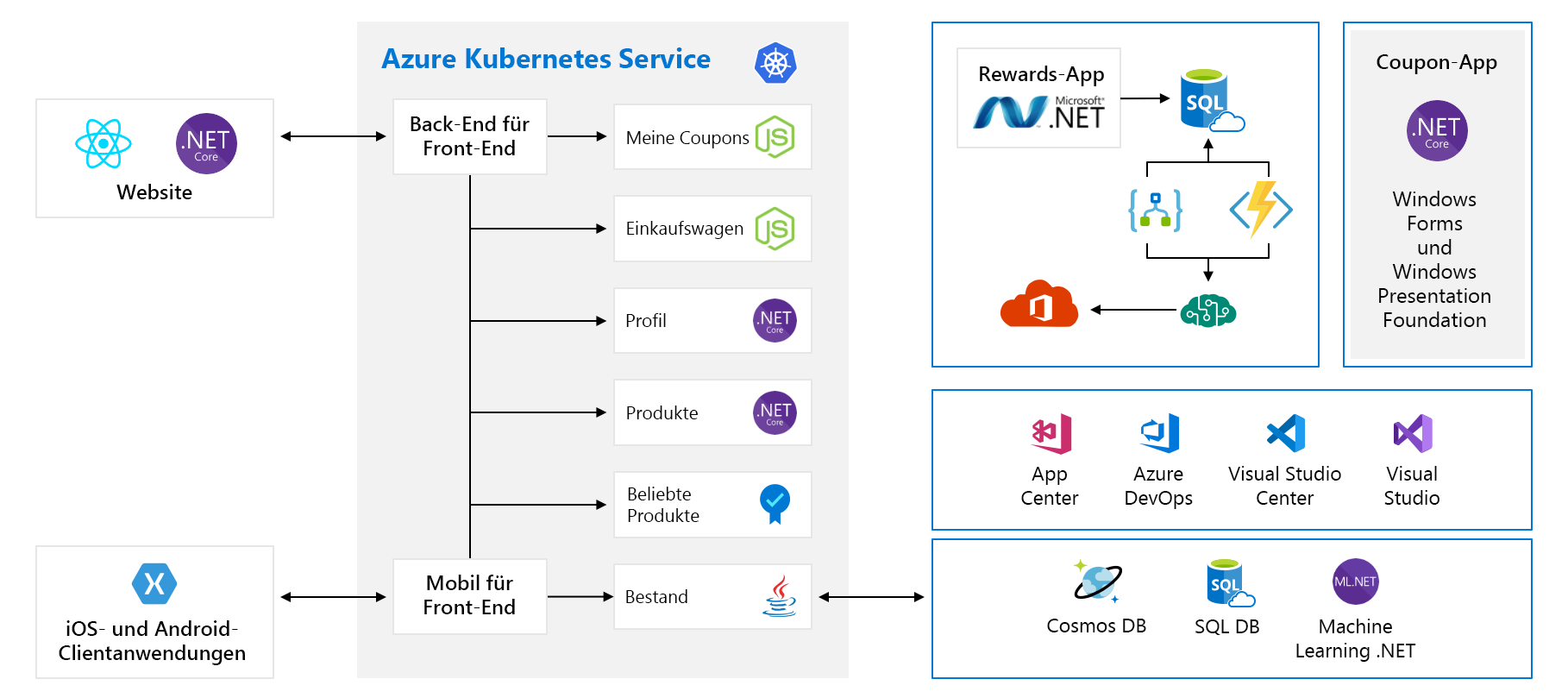
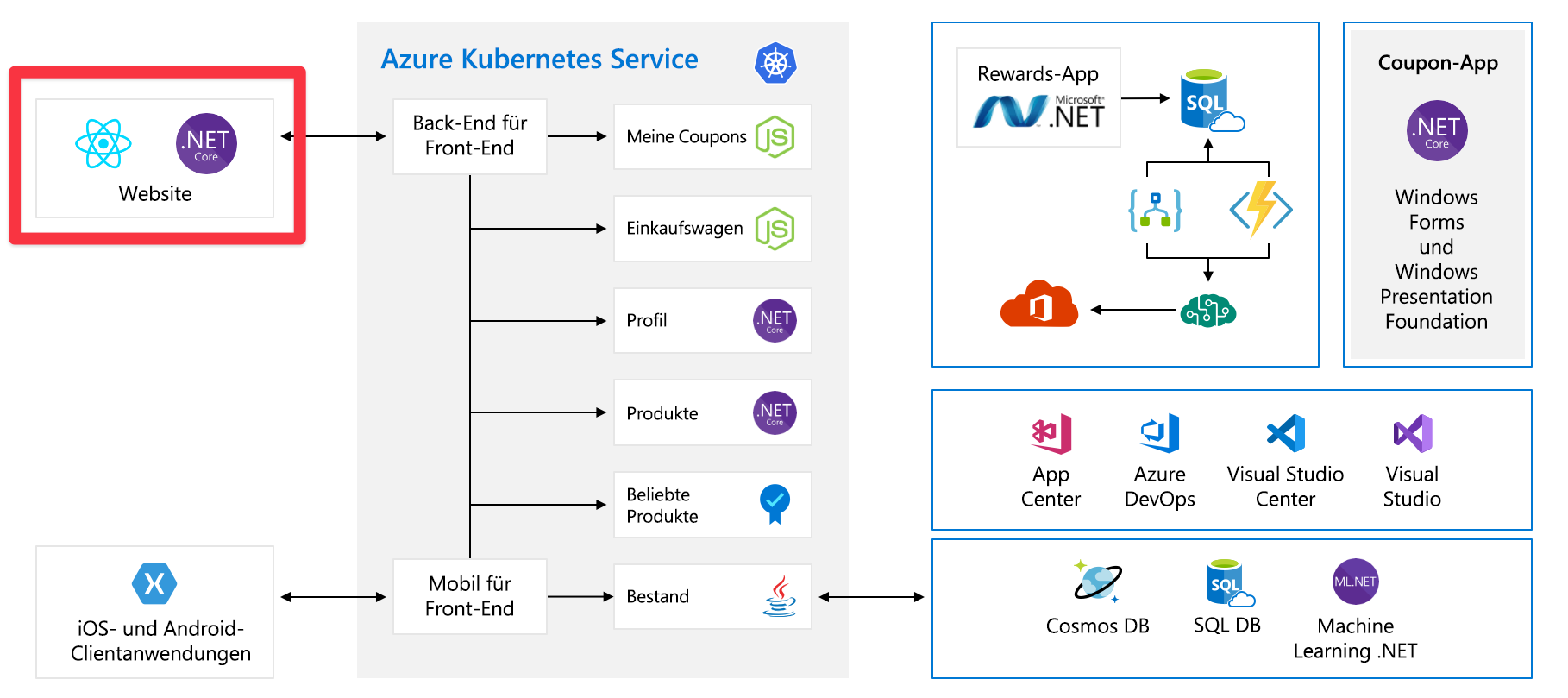
Auf den ersten Blick wirkt die Abbildung sehr komplex, weshalb die einzelnen Bestandteile nacheinander erläutert werden. Die Website verfügt über ein Front-End. Das ist die Komponente, mit der Sie kommunizieren, wenn Sie „tailwindtraders.com“ besuchen.
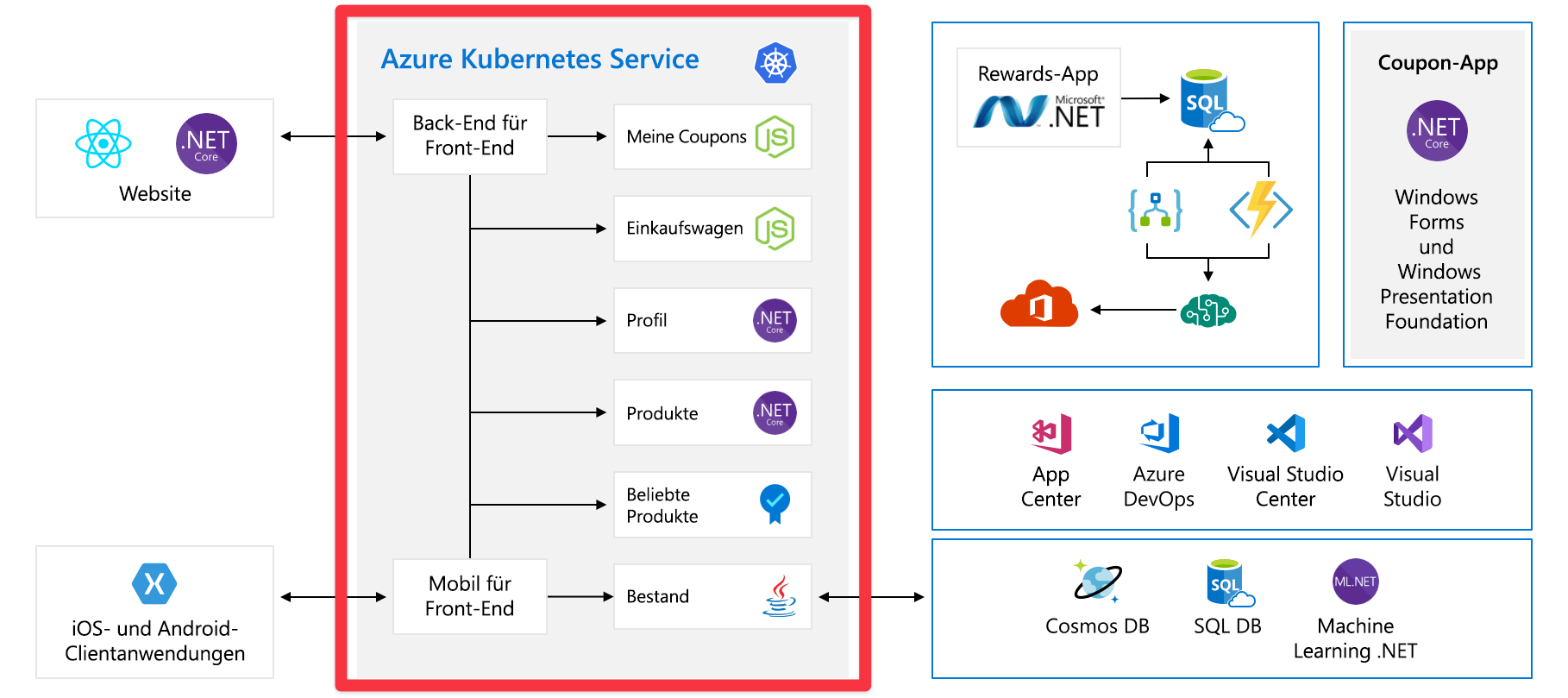
Das Front-End kommuniziert mit einem Satz von Back-End-Diensten. Diese Back-End-Dienste umfassen gängige Komponenten, darunter etwa die Dienste „Coupons“, „Einkaufswagen“, „Bestand“ usw. Sie werden alle in Azure Kubernetes Service ausgeführt. Diese Anwendung umfasst auch andere Komponenten und Technologien. Sie müssen sich lediglich auf die Front-End- und die Back-End-Dienste konzentrieren, die auf Kubernetes ausgeführt werden.
Single Points of Failure
Nachdem Sie nun die gesamte Architektur kennengelernt haben, sehen wir uns nun die Single Points of Failure und die Stellen an, mit denen wir uns bei der Skalierung beschäftigen können.
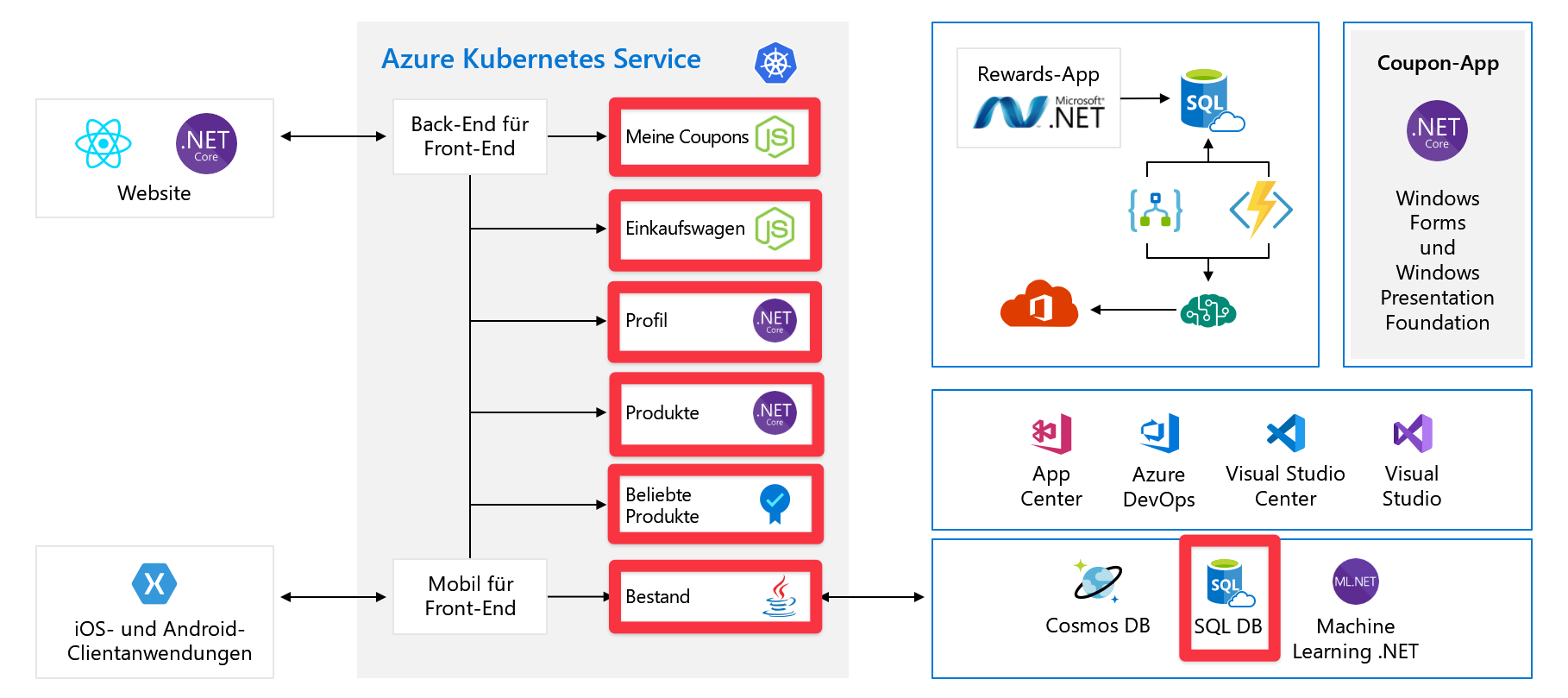
Alle diese Dienste sind jeweils ein Single Point of Failure. Sie sind nicht für Resilienz oder Skalierbarkeit konzipiert. Wenn einer dieser Dienste überlastet wird, stürzt er wahrscheinlich ab. Es gibt auch keine einfache Möglichkeit, das Problem in diesem Moment zu beheben.
Später in diesem Modul werden weitere Möglichkeiten erläutert, wie Sie den Dienst so entwerfen können, dass er skalierbarer und zuverlässiger wird.
Vorab bereitgestellte Kapazität
Sehen wir uns nun ein anderes Problem an, das auftreten könnte. Dies sind die Dienste bzw. Komponenten, für die vorab Kapazität bereitgestellt werden muss:
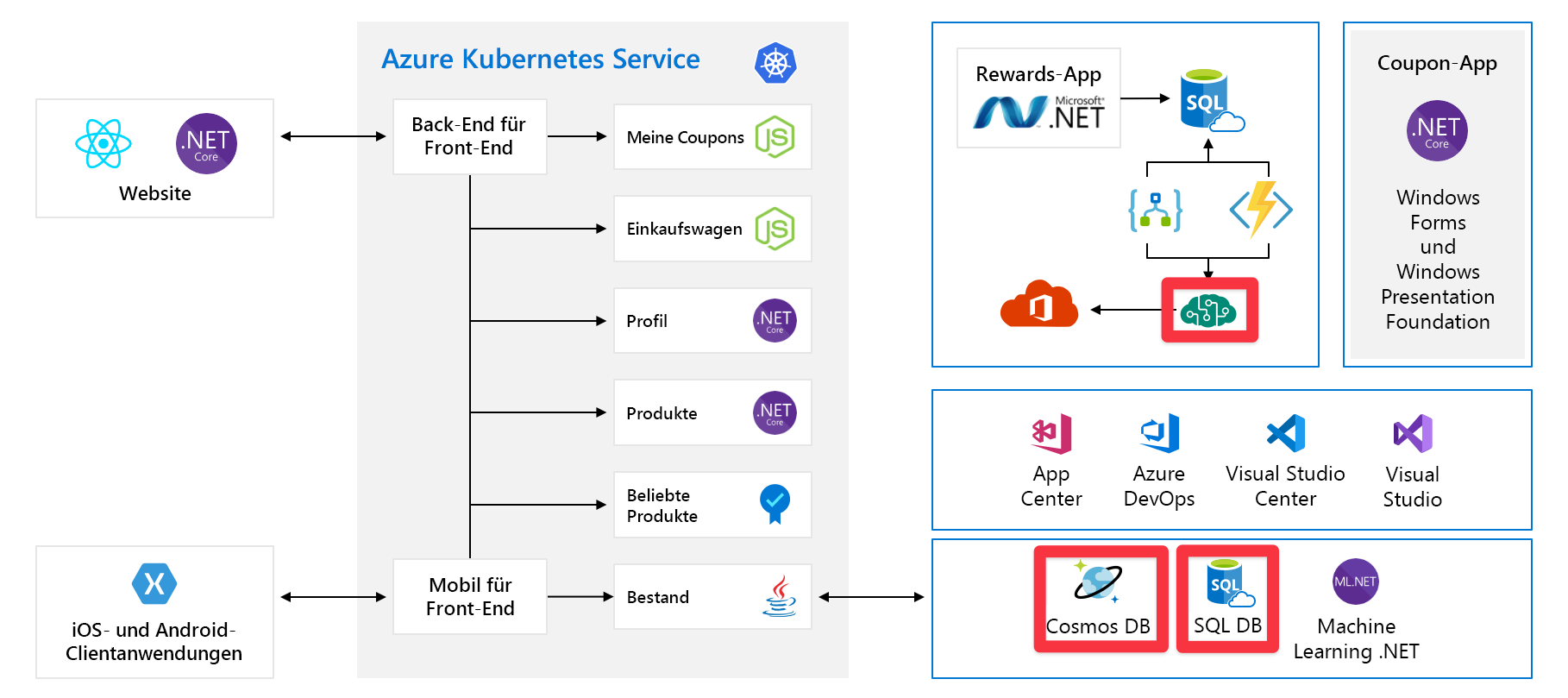
Beispielsweise wird bei Cosmos DB der Durchsatz vorab bereitgestellt. Wenn diese Grenzwerte überschritten werden, werden Fehlermeldungen an unsere Kunden zurückgegeben. Mit Azure KI Services-Instanzen wählen Sie die Ebene aus, und für diese Ebene gilt eine Höchstzahl von Anforderungen pro Sekunde. Bei Erreichen einer dieser Grenzwerte werden die Clients gedrosselt.
Werden diese Grenzwerte durch eine Spitze im Datenverkehr, beispielsweise nach einer Produkteinführung, erreicht? Zurzeit wissen wir das nicht. Dies ist ein weiterer Punkt, der später in diesem Modul erläutert wird.
Kosten
Auch wenn wir alles richtig machen, müssen wir dennoch für Wachstum planen. Hier finden Sie die Dienste mit nutzungsbasierter Bezahlung:
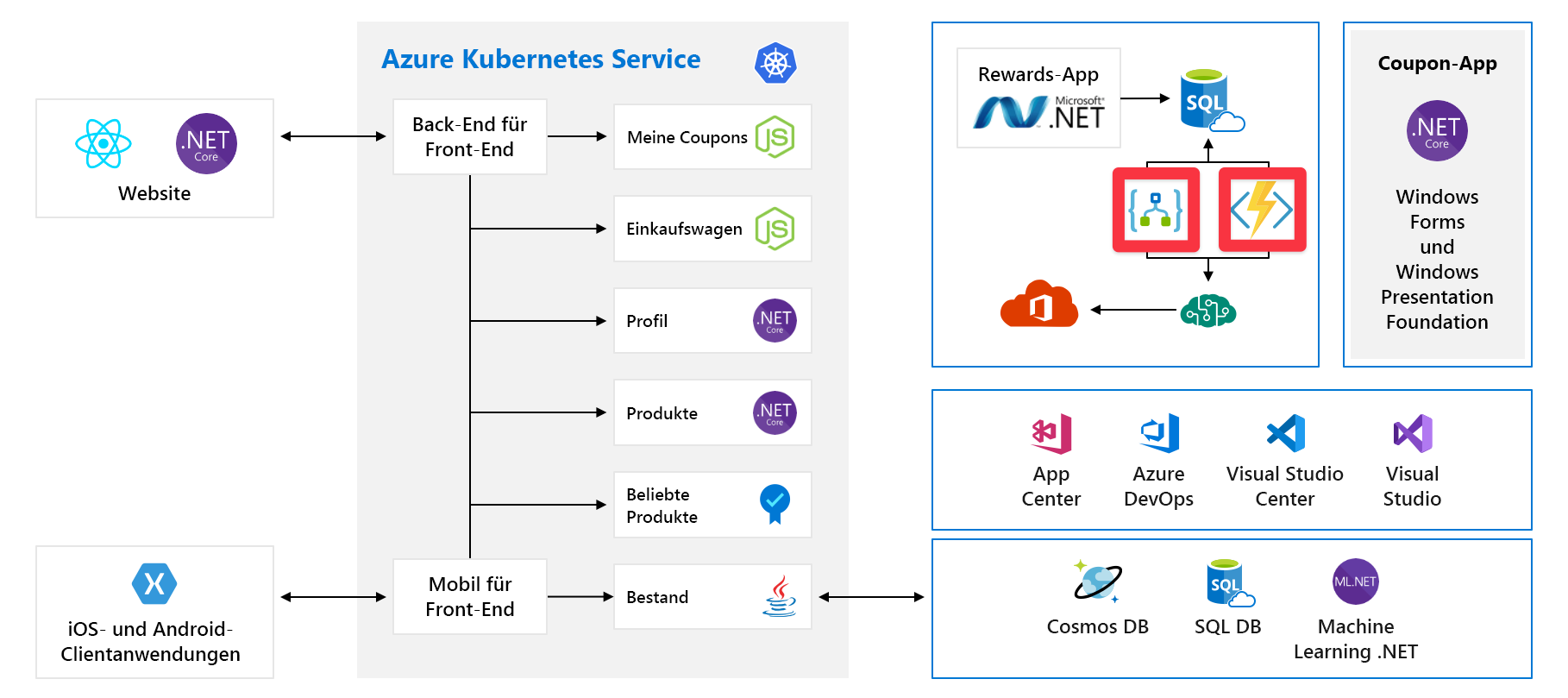
Hier verwenden wir Azure Logic Apps und Azure Functions – beides Beispiele für serverlose Technologien. Diese Dienste werden automatisch skaliert und pro Anforderung abgerechnet. Je größer Ihre Kundenbasis wird, desto höher fallen auch Ihre Kosten aus. Wir sollten zumindest wissen, welche Auswirkungen anstehende Ereignisse wie eine Produkteinführung auf unsere Cloudausgaben haben können. Später in diesem Modul beschäftigen Sie sich auch mit dem Verstehen und Vorhersagen der Cloudausgaben.