Servicelevelindikatoren (SLIs) und Servicelevelziele (SLOs)
In diesem Modul haben wir bisher erfahren, wie wir unser operatives Bewusstsein schärfen und das Verständnis und die Rahmenbedingungen bezüglich der Zuverlässigkeit erweitern, und wir haben die Azure Monitor-Tools kennengelernt, die wir für unsere Arbeit benötigen werden. Jetzt ist es an der Zeit, eine der wichtigsten Ideen in diesem Modul und die Prozesse zu deren Implementierung kennen zu lernen.
Lassen Sie uns eine Antwort auf die Frage „Wie verwende ich all das, um die Zuverlässigkeit in meiner Organisation zu optimieren?“ finden.
Eintreten in die Feedbackschleife
Hier ist das großartige Konzept, mit dem unser Problem gelöst werden kann:
Die richtigen Feedbackschleifen optimieren die Zuverlässigkeit in Ihrer Organisation.
Das Verbessern der Zuverlässigkeit in Ihrer Organisation ist ein iterativer Prozess. In dieser Lerneinheit erfahren Sie mehr über eine äußerst effektive Praxis aus der Welt der Sitezuverlässigkeits-Entwicklung, bei der es darum geht, die Art von Feedbackschleife in einer Organisation zu erstellen und zu pflegen, die bei der Verbesserung der Zuverlässigkeit hilft. Zumindest wird es in Ihrem Unternehmen konkrete Gespräche über Zuverlässigkeit auf der Grundlage objektiver Daten auslösen.
An früherer Stelle in diesem Modul haben wir folgende Definition des Site Reliability Engineering angeführt:
Beim Site Reliability Engineering handelt es sich um einen Aufgabenbereich der Entwicklung, der Organisationen dabei unterstützen soll, nachhaltig einen angemessenen Grad an Zuverlässigkeit ihrer Systeme, Dienste und Produkte zu erzielen.
An dieser Stelle kommt das Konzept des angemessenen Zuverlässigkeitsgrades ins Spiel.
Servicelevelindikatoren (SLIs)
Servicelevelindikatoren (Service Level Indicators, SLIs) stehen mit der obigen Erörterung über ein umfassendes Verständnis von Zuverlässigkeit in Verbindung. Erinnern Sie sich an dieses Diagramm?
SLIs sind unser Versuch, genau zu spezifizieren, wie wir die Zuverlässigkeit unseres Systems messen wollen. Was ist der Indikator dafür, dass sich unser Dienst zuverlässig verhält (das tut, was wir erwarten)? Was können wir messen, um dies zu beantworten?
Beispiel: Webserververfügbarkeit und -latenz
Nehmen wir an, wir arbeiten mit einem Webserver und seiner Verfügbarkeit. Möglicherweise interessieren wir uns für die Anzahl der empfangenen HTTP-Anforderungen und die Anzahl der HTTP-Anforderungen, auf die erfolgreich reagiert wurde. Genauer gesagt möchten wir verstehen, wie erfolgreich er als Webserver war, indem wir das Verhältnis zwischen erfolgreichen Anforderungen und der Gesamtzahl an Anforderungen verstehen.
Wenn wir die Gesamtzahl der Anforderungen durch die Anzahl erfolgreicher Anforderungen teilen, erhalten wir das Verhältnis. Wir können dieses Verhältnis mit 100 multiplizieren, um einen Prozentsatz zu erhalten. Nehmen wir als ein Beispiel mit runden Zahlen an, unser Webserver hat 100 Anforderungen empfangen und auf 80 erfolgreich geantwortet, dann ist das Verhältnis 0,8. Multiplizieren Sie es mit 100, und wir können angeben, dass seine Verfügung 80 % betragen hat.
Versuchen wir es noch einmal. Diesmal wollen wir eine Messung angeben, die mit der Wartezeit unseres Webdienstes verbunden ist. Möglicherweise möchten wir das Verhältnis zwischen der Anzahl der in weniger als 10 Millisekunden abgeschlossenen Vorgänge und der Gesamtzahl an Vorgängen kennen. Wenn wir dieselbe Berechnung anstellen – 100 Anforderungen insgesamt dividiert durch 80 Anforderungen, die schneller als unser Schwellenwert zurückgegeben wurden –, erhalten wir wiederum ein Verhältnis von 0,8. Multiplizieren Sie es mit 100, und wir können auch hier angeben, dass die Wartezeitanforderungen bei dieser Messung zu 80 % erfüllt sind.
Um es klar zu machen: Dies betrifft nicht nur eine Website. Wenn wir einen Pipelinedienst hätten, der Daten verarbeitet, könnten wir sagen, dass wir die Abdeckung messen müssten (z. B. wie viele Daten verarbeitet wurden). Sehr unterschiedliche Systeme, aber die gleiche zugrundeliegende Mathematik.
SLIs: Messpunkte
Damit SLIs in konkreten Diskussionen mithilfe von objektiven Daten hilfreich sind, müssen wir zusätzlich zur Messung ein weiteres Element angeben. Beim Erstellen eines SLI müssen wir nicht nur die gemessenen Elemente beachten, sondern auch, wo die Messung durchgeführt wurde.
Wenn wir beispielsweise angegeben haben, womit wir die Verfügbarkeit des zuvor erwähnten Webservers gemessen haben, fehlt dabei die Angabe, woher die Werte der Anzahl erfolgreicher HTTP-Anforderungen und der Gesamtzahl an Anforderungen stammen. Wenn Sie versuchen, mit Kollegen ein Gespräch über die Zuverlässigkeit dieses Webservers zu führen, und sich dazu die Anforderungsstatistik ansehen, die vor dem Server an einem Lastenausgleich erfasst wurde, die Kollegen jedoch die Statistiken vom Server selbst betrachten, verläuft das Gespräch möglicherweise nicht so gut. Die Zahlen können sich grundlegend unterscheiden, da der Lastenausgleich möglicherweise alle im Netzwerk ankommenden Anforderungen sieht. Wenn jedoch ein Problem mit dem Netzwerk oder dem Lastenausgleich selbst vorliegt, erreichen unter Umständen nicht alle Anforderungen den Server. Wir würden Schlussfolgerungen basierend auf zwei unterschiedlichen Datasets ziehen.
Eine einfache Möglichkeit, dieses Problem zu lösen, besteht darin, die Datenquelle im SLI genau anzugeben. Für den Webserver wäre die Verfügbarkeit „das Verhältnis zwischen erfolgreichen Anforderungen und den Gesamtanforderungen gemäß Messung durch den Lastenausgleich“. Für die Wartezeit würden wir etwas sagen wie „das Verhältnis zwischen der Anzahl der Vorgänge, die in weniger als 10 Millisekunden abgeschlossen wurden im Vergleich zur Gesamtanzahl der Vorgänge gemäß Messung auf dem Client“.
Dies führt zur logischen Frage: Wo ist der beste Ort, um SLIs zu messen? Unglücklicherweise gibt es keine generell „richtige“ Antwort. Bei dieser Entscheidung müssen Sie verstehen, dass es in jedem Fall Kompromisse gibt. Ein Ratschlag, den wir geben können, knüpft an unsere obige Erläuterung zur Zuverlässigkeit an: Versuchen Sie, Werte an einem Ort zu messen, der die Erfahrung Ihrer Kunden am genauesten widerspiegelt.
Servicelevelziele (SLO)
Die Entscheidung, was (und wo) gemessen werden muss, ist ein hervorragender Einstieg, aber wir erreichen damit unser Ziel nur zur Hälfte. Nehmen wir an, dass wir die Metriken abrufen, die wir für den SLI zur Verfügbarkeit des Webservers benötigen, und wir stellen fest, dass er tatsächlich 80 % verfügbar ist.
Ist das gut oder schlecht? Ist das der „angemessene Grad an Zuverlässigkeit“?
Wir müssen zur Beantwortung dieser Fragen ein Ziel für diesen SLI festlegen: ein Servicelevelziel (Service Level Objective, SLO). Dieses Ziel gibt die Zielstellung für den jeweiligen Dienst eindeutig an.
Die grundlegende Anleitung zum Erstellen eines SLO umfasst Folgendes:
Das„Ding“, das Sie messen werden: Anzahl der Anforderungen, Speicherprüfungen, Vorgänge; das, was Sie messen.
Der gewünschte Anteil: Beispielsweise „in 50 % der Fälle erfolgreich“, „in 99,9 % der Fälle lesbar“, „in 90 % der Fälle in 10 ms zurück“.
Der Zeithorizont: Wie lautet die Zeitspanne, die wir für das Ziel betrachten werden: die letzten 10 Minuten, während des letzten Quartals, über ein rollierendes 30-Tage-Fenster? SLOs werden meistens mithilfe eines rollierenden Zeitfensters und nicht über eine Kalendereinheit wie „ein Monat“ angegeben, damit wir Daten aus unterschiedlichen Zeiträumen vergleichen können.
Wenn Sie diese Komponenten kombinieren und die wichtige Information zum Wo einschließen, könnte ein Beispiel-SLO wie folgt aussehen:
90 % der HTTP-Anforderungen, die vom Lastenausgleich gemeldet wurden, wurden im letzten 30-tägigen Zeitfenster erfolgreich abgeschlossen.
Ebenso könnte ein einfaches SLO zur Messung der Latenz wie folgt aussehen:
90 % der vom Client gemeldeten HTTP-Anforderungen wurden im letzten 30-tägigen Zeitfenster in < 20 ms zurückgegeben.
Beginnen Sie mit einfachen SLOs wie diesen, wenn Sie den Vorgang in Ihrer Organisation einführen. Sie können später bei Bedarf komplexere SLOs erstellen.
SLIs und SLOs in Azure Monitor
Im letzten Teil dieser Einheit sehen wir uns an, wie einfache SLIs/SLOs mithilfe von Log Analytics in Azure Monitor dargestellt werden können. Um konsistent zu bleiben, kehren wir zum Beispiel des Webservers zurück.
Sie haben in der letzten Lerneinheit erfahren, dass Sie Abfragen in Log Analytics mithilfe der Kusto-Abfragesprache (KQL) erstellen können. Im Folgenden finden Sie eine KQL-Abfrage, die einen Verfügbarkeits-SLI für einen Webdienst anzeigt:
requests
| where timestamp > ago(30d)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| project SLI, timestamp
| render timechart
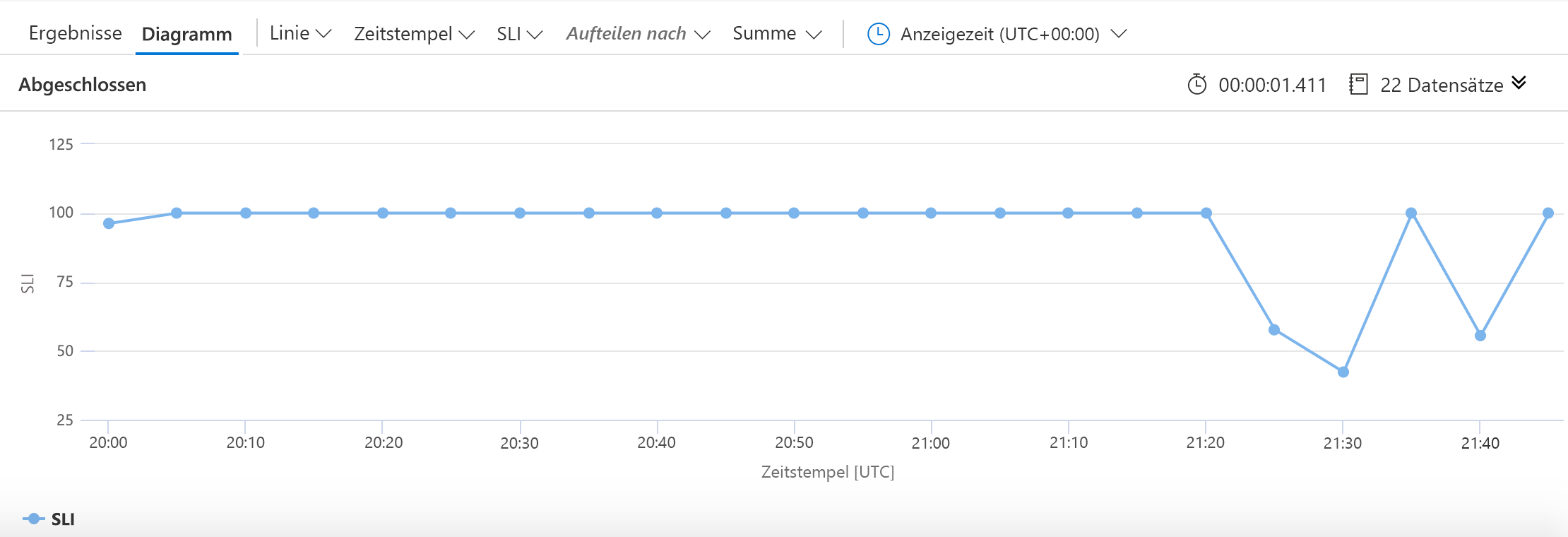
Wie zuvor beginnen Sie mit der Angabe der Quelle der Daten: die requests-Tabelle. Anschließend schränken wir die Daten, mit denen wir arbeiten werden, auf die letzten 30 Tage ein. Dann sammeln wir (in 5-Minuten-Abschnitten) die Anzahl der erfolgreicher Anforderungen, die Anzahl der fehlgeschlagener Anforderungen und die Gesamtzahl der Anforderungen. Der SLI wird mithilfe der einfachen Arithmetik erstellt, die wir zuvor betrachtet haben. Wir teilen KQL mit, dass wir diesen SLI zusammen mit Zeitstempeln zeichnen möchten, und erstellen dann ein Diagramm, das in etwa wie folgt aussieht:
Nun geht es um eine einfache Darstellung eines SLO:
requests
| where timestamp > ago(5h)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| extend SLO = 80.0
| project SLI, timestamp, SLO
| render timechart
Dieses Beispiel unterscheidet sich in zwei geänderten Zeilen von dem vorherigen. Der erste definiert die Zahl, die wir für das SLO verwenden werden, und der zweite teilt KQL mit, dass das SLO in das Diagramm einbezogen werden soll. Das Ergebnis sieht wie folgt aus:
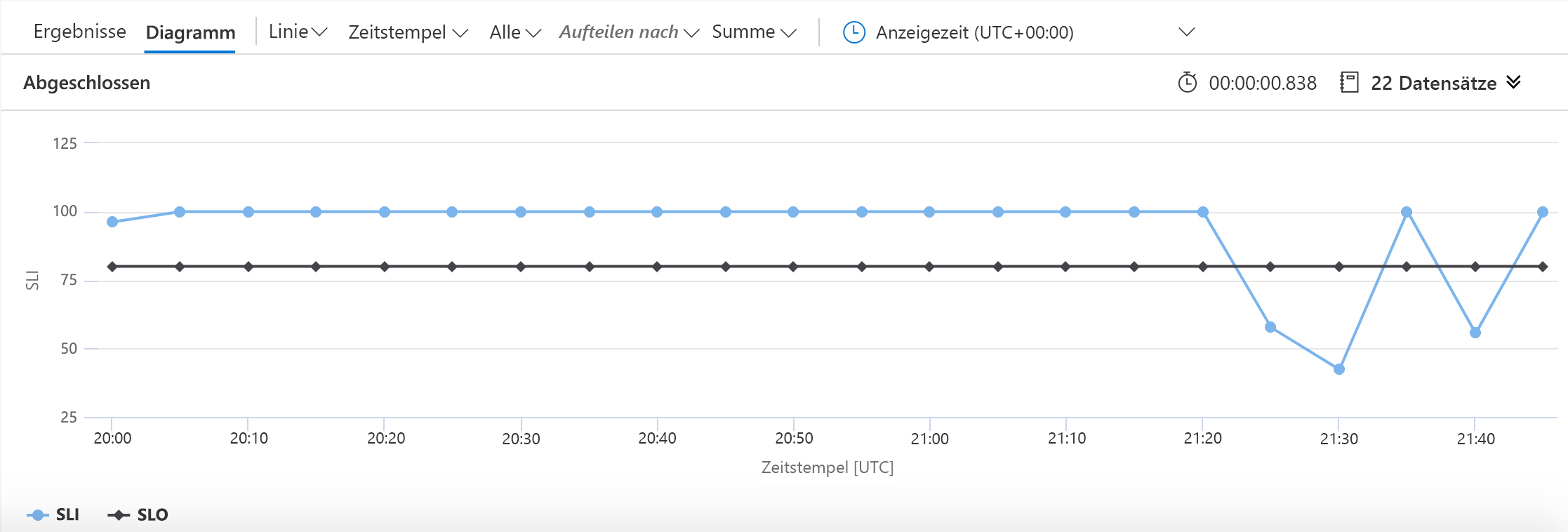
In diesem Diagramm ist gut zu erkennen, wann wir unter unser Verfügbarkeitsziel gefallen sind.
Verwenden von SLIs/SLOs
Es ist unvermeidlich, dass Sie Ihre SLIs und SLOs etwas anpassen müssen (schließlich ist dies ein iterativer Prozess). Aber was tun Sie danach mit den Informationen?
Die gute Nachricht ist, dass Sie wahrscheinlich feststellen werden, dass allein das Erstellen der SLIs und SLOs positive Auswirkungen auf die Organisation haben wird. Hierfür sind Diskussionen mit Projektbeteiligten und andere Kommunikationen erforderlich, um die Dinge in die richtige Richtung zu lenken. Die darauf folgenden Diskussionen darüber, was mit ihnen zu tun ist, können ebenfalls hilfreich sein.
Schlussendlich handelt es sich bei SLIs und SLOs um Tools zur Arbeitsplanung. Sie können Ihnen dabei helfen, Entwicklungsentscheidungen wie die folgende zu treffen: „Sollten wir an neuen Features für den Dienst arbeiten, oder sollten wir uns stattdessen auf die Zuverlässigkeit konzentrieren?“ Sie können bei den Feedbackschleifen helfen, die wir bereits besprochen haben.
Ein sekundärer, aber recht gängiger Verwendungsbereich für SLIs und SLOs liegt im Rahmen eines unmittelbareren Überwachungs- bzw. Antwortsystems. Zusätzlich zum Arbeitsplanungsaspekt (auf den Sie sich zuerst konzentrieren sollten) verwenden viele Personen sie als Vorgangssignal. Beispielsweise können sie ihre Mitarbeiter benachrichtigen, wenn der Dienst über einen längeren Zeitraum sein SLO verfehlt. Diese Art von Warnung führt uns zu unserer nächsten Einheit in diesem Modul.