Protokollanalysen und KQL-Abfragen
Wenn wir anfangen, auf die Zuverlässigkeit unserer Dienste zu achten, brauchen wir eine Möglichkeit, um nachzuverfolgen, wie gut (oder nicht gut) sie funktionieren. Vielfach finden wir diese Informationen in den Protokollen eines Diensts, deshalb benötigen wir ein Tool, um mit diesen Protokollen zu arbeiten. Log Analytics ist das Tool, das wir in Azure zu diesem Zweck verwenden werden. Es erlaubt uns, diese Daten abfragen und sie so anzuzeigen, dass sie für unsere Arbeit im Bereich der Zuverlässigkeit nützlich sind.
Der Abfrageprozess in Log Analytics umfasst das Schreiben von Abfragen in der Kusto-Abfragesprache (Kusto Query Language, KQL). Wenn Sie schon einmal mit einer anderen Abfragesprache gearbeitet haben (z. B. der Structured Query Language, die den meisten Benutzern mit der Abkürzung SQL bekannt ist), werden Sie keine Probleme mit KQL haben. Auch wenn Sie dies nicht der Fall ist, werden Ihnen grundlegende KQL-Abfragen wahrscheinlich leicht fallen, sobald Sie sehen, wie sie funktionieren.
Die Funktionsweise von Log Analytics
Sehen wir uns nun an, wie all das funktioniert. Hier ist ein Diagramm zur Funktionsweise von Log Analytics:
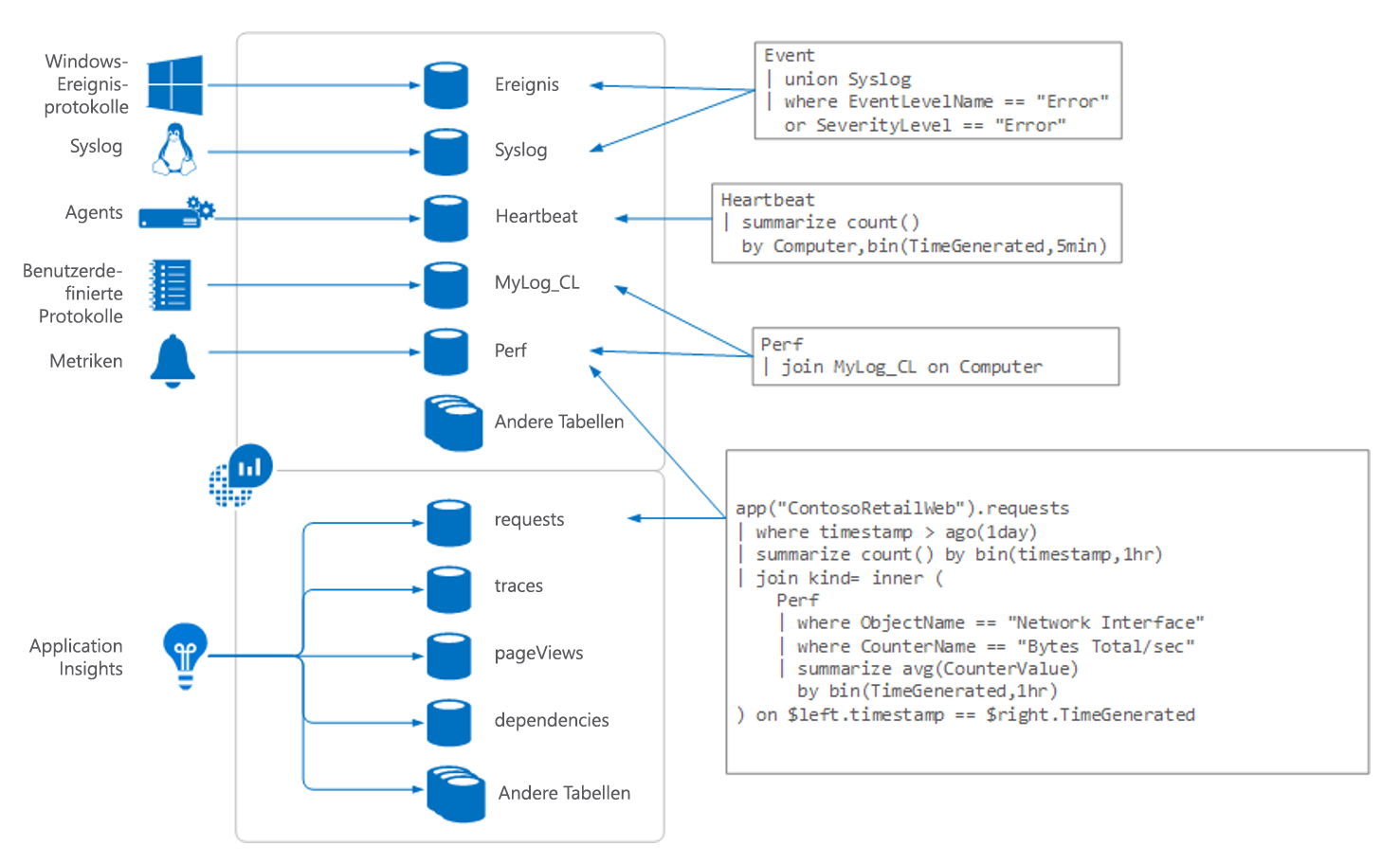
Die Daten für Log Analytics stammen aus einer Reihe von Quellen einschließlich der Folgenden:
- Windows-Ereignisprotokolle
syslogauf Linux-Computern- Agents, die auf VMs ausgeführt werden
- Benutzerdefinierte Protokolle, die von Personen eingereicht werden
- Metriken aus Azure-Ressourcen
- Telemetriedaten aus Application Insights
Alle diese Informationen werden in Bereiche eingelesen, die Log Analytics als Tabellen bezeichnet. Sie können sich jede Tabelle als separate Datenbank vorstellen. Sie werden Abfragen schreiben, mit denen Sie die Informationen aus den Tabellen abrufen. In den Beispielen, die wir später in diesem Modul vorstellen, arbeiten wir in erster Linie mit einer Tabelle mit dem Titel „Anforderungen.“
Log Analytics-Benutzeroberfläche
Die folgende Grafik zeigt die verschiedenen Teile der Log Analytics-Schnittstelle.
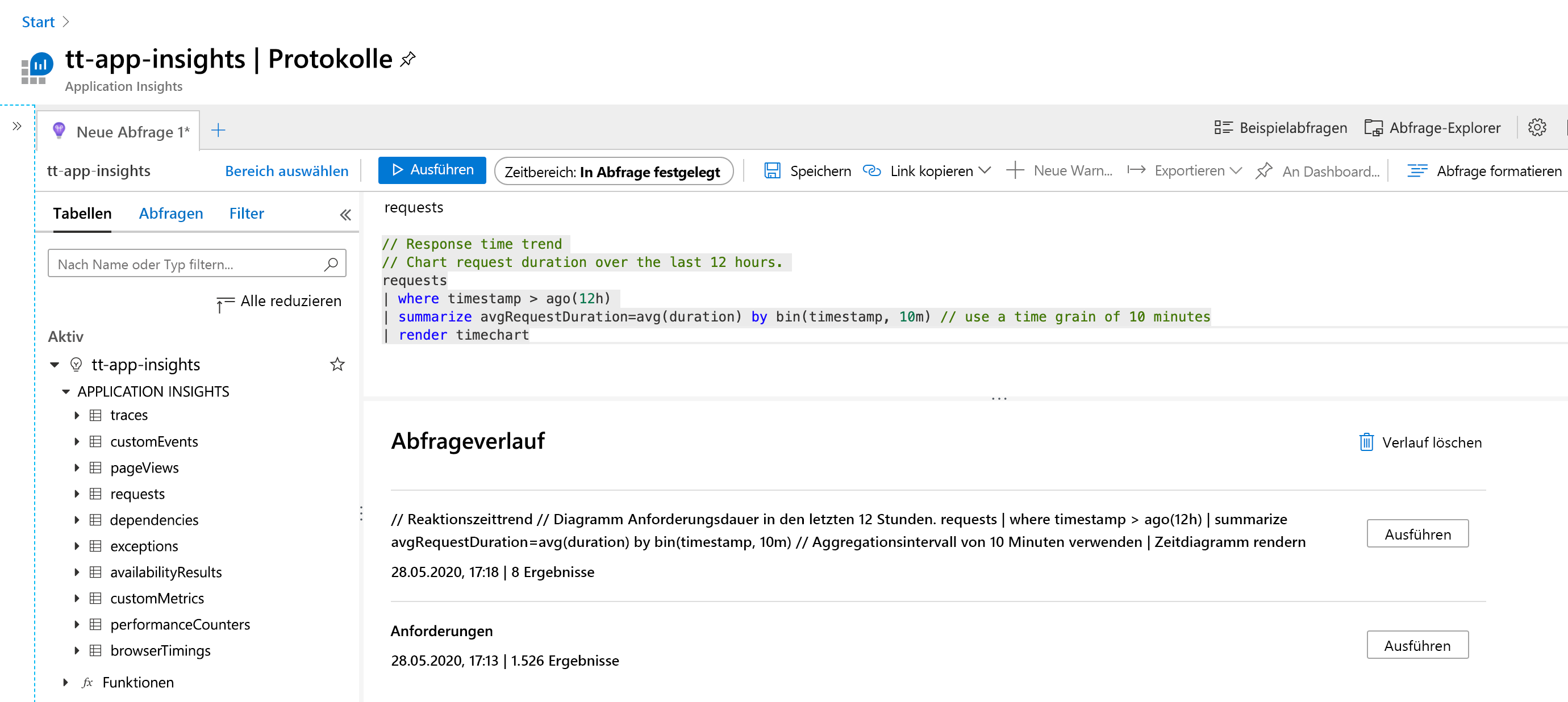
Auf der linken Seite befindet sich ein Bildschirmbereich, der sicherstellt, dass Sie bei der Verwendung von Log Analytics niemals die Orientierung verlieren. Sie zeigt die Tabellen, mit denen Sie möglicherweise arbeiten, und wenn Sie einen Abschnitt erweitern, sehen Sie eine Liste der Felder in dieser Tabelle, die für das Abfragen verfügbar sind. Wenn Sie eines der Felder oder den Tabellennamen auswählen, werden diese in den Bereich zur Abfrageerstellung kopiert.
Der Bereich für die Abfrageerstellung befindet sich oben. An dieser Stelle geben Sie eine Abfrage an und führen sie aus. Sie können einen Zeitrahmen für die Daten angeben, wenn dieser nicht bereits als Teil der Abfrage angegeben wurde. Sie können Abfragen speichern oder zusätzliche Registerkarten öffnen, wenn Sie an mehreren Abfragen gleichzeitig arbeiten wollen.
Am unteren Rand der Seite finden Sie weitere hilfreiche Informationen. Hier zeigt Log Analytics frühere Abfragen an, die Sie ausgeführt haben. Dies kann hilfreich sein, wenn Sie zu etwas zurückkehren müssen, das Sie bereits zuvor angegeben haben, beispielsweise wenn Sie an einer Abfrage gearbeitet haben, etwas ausprobiert haben und zurückgehen mussten.
Schreiben von KQL-Abfragen
KQL ist eine leistungsfähige Abfragesprache. Wir werden die Oberfläche nur mit einigen einfachen Abfragen durchgehen, damit Sie sehen können, wie einfach sie zu verwenden ist. Wenn Sie später eine ausführlichere Erläuterung der erweiterten Features (einschließlich einiger Funktionalitäten zum maschinellen Lernen) erhalten möchten, sollten Sie sich das Log Analytics-Tutorial ansehen.
Schreiben wir zu Beginn eine einfache KQL-Abfrage. Fast alle KQL-Abfragen beginnen mit der Datenquelle, also der Tabelle, die Sie abfragen. Wenn Sie also Daten aus der Tabelle „Anforderungen“ abfragen würden, würden Sie damit im Abfragebereich beginnen:
Requests
Der nächste Teil einer KQL-Abfrage besteht darin, die Tabelle mit dem Vorgang zu verbinden, den Sie ausführen möchten. Verwenden Sie einen senkrechten Strich (den horizontalen Strich auf der Tastatur, der sich meistens über dem Schrägstrich befindet) zwischen dem Tabellennamen und dem Befehl.
Hier eine einfache Abfrage zum Sortieren der Tabelle mit den ersten zehn (Top 10) gefundenen Datensätzen:
Requests
|top 10
Im Folgenden finden Sie einige Beispiele für weitere gängige Befehle, die Sie anstelle von „Top 10“ verwenden können:
Wenn Sie anstelle der ersten zehn Datensätze (beispielsweise zum Anzeigen der Tabellenstruktur) zehn zufällige Datensätze anzeigen möchten, können Sie den folgenden Befehl verwenden:
requests |take 10Zum Anzeigen von Datensätzen, die in der letzten halben Stunde eingegangen sind, können Sie die folgende Abfrage verwenden:
requests |where timestamp > ago(30m)Eine weitere häufige Aufgabe besteht darin, die Reihenfolge anzugeben, in der die Daten zurückgegeben werden sollen. Hier finden Sie ein Beispiel für eine Abfrage, die nach einem bestimmten Feld (Zeitstempel) in absteigender Reihenfolge sortiert wird (z. B. werden die aktuellsten Daten zuerst angezeigt):
requests |sort by timestamp desc
Wie bei SQL können Sie mehrere Bedingungen festlegen, um anzugeben, welche Datensätze zurückgegeben werden sollen. Verwenden Sie zusätzliche senkrechte Striche und Klauseln, um sie hinzuzufügen. Der senkrechte Strich trennt Befehle, sodass die Ausgabe des ersten Befehls die Eingabe des nächsten Befehls ist. Eine einzelne Abfrage kann beliebig viele Befehle enthalten.
Hier finden Sie ein Beispiel für eine Abfrage, die alle Datensätze mit 404-Antwortcode (z. B. alle Datensätze vom Typ „Seite nicht gefunden“ von einem Webdienst) der letzten 30 Minuten zurückgibt:
requests
|where timestamp > ago(30m)
|where toint(resultCode) == 404
Diese Abfrage wird geschrieben, um die Effizienz zu maximieren. Wenn Sie zunächst nur die Datensätze der letzten 30 Minuten auswählen, verringern Sie die Anzahl Datensätze, die die zweite Bedingung durchsuchen muss, drastisch. Wenn Sie diese Abfrage in umgekehrter Reihenfolge schreiben würden, würde sie zunächst alle 404-Datensätze seit der Anfangszeit in den Daten finden und dann die große Mehrheit verwerfen, so dass Sie nur die Daten der letzten halben Stunde erhalten. Beachten Sie beim Schreiben von Abfragen mit mehreren Bedingungen immer die Reihenfolge der Verarbeitung.
Es folgt ein letztes Beispiel für eine Abfrage, bevor wir uns später in diesem Modul wieder mit der Leistungsfähigkeit von Log Analytics beschäftigen, wenn es darum geht, die Zuverlässigkeit zu optimieren. Im Folgenden finden Sie eine Abfrage mit einer datenbasierten Berechnung:
requests
|where timestamp > ago(30m)
|summarize count() by name, URL
Diese Abfrage gibt eine Zusammenfassung der Anforderungen zurück, die wir in der letzten halben Stunde empfangen haben. Bei einem Webdienst könnte es also vorkommen, dass es 2875 Mal eine GET index.html-Anforderung an die URL http://tailwindtraders.com gab. Wir unterbrechen unsere Betrachtung von KQL mit dieser Abfrage, weil sie eine gute Verbindung zu den KQL-Abfragen herstellt, die wir in der nächsten Lerneinheit verwenden werden.