Die Zuverlässigkeitshierarchie nach Dickerson
Der Aufbau des Lernpfads Die Zuverlässigkeit verbessern orientiert sich an einem Modell aus dem Bereich Site Reliability Engineering, das als Zuverlässigkeitshierarchie nach Dickerson bezeichnet wird. Mikey Dickerson ist ein ehemaliger Site Reliability Engineer, der den staatlichen Beratungsdienst United States Digital Service gründete und auch als dessen erster Leiter fungierte. Er erarbeitete diese Hierarchie, während er mit einer der größten Zuverlässigkeitskrisen aller Zeiten konfrontiert war.
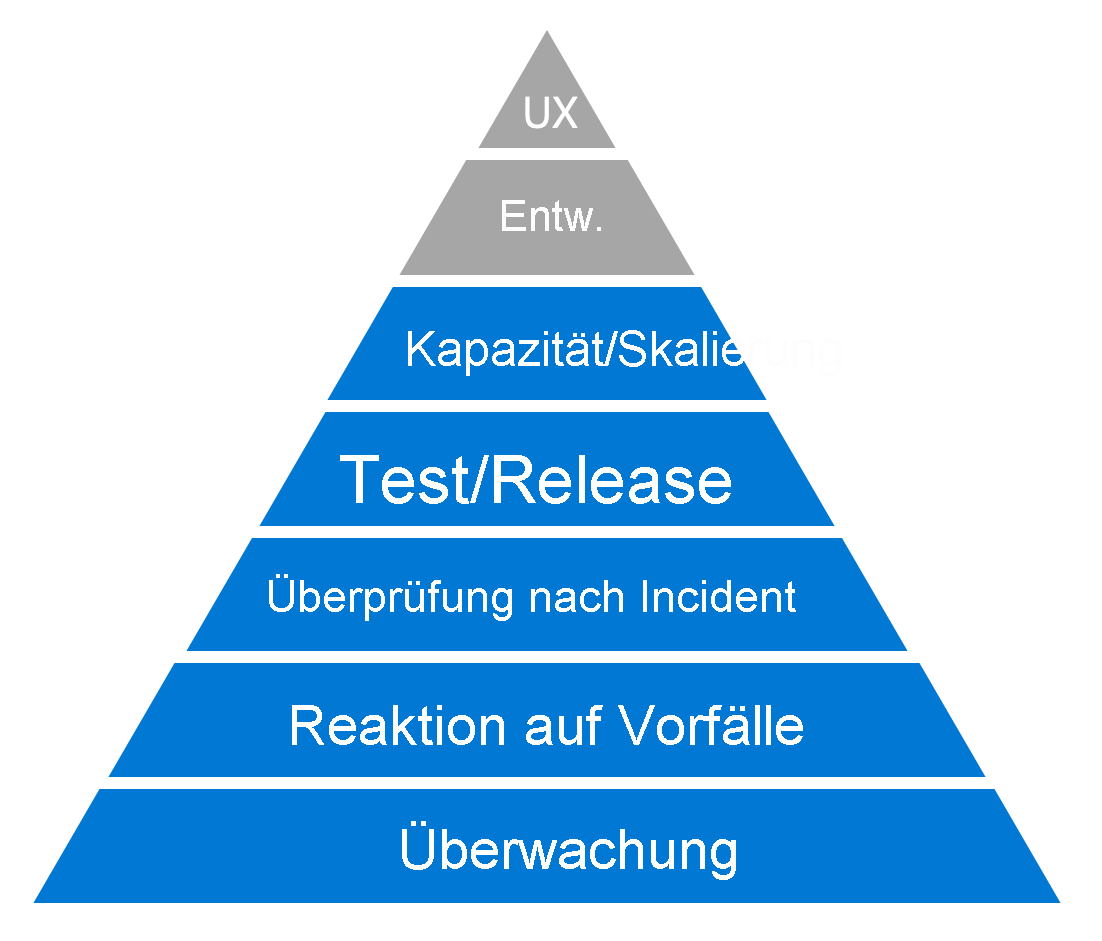
Das Modell ist angelehnt an die Bedürfnishierarchie nach Abraham Maslow, die menschliche Motivation veranschaulicht. Wie bei der Maslowschen Hierarchie geht es zuerst um eine Auseinandersetzung mit den unteren Ebenen, bevor Sie sich mit den Aspekten in den oberen Ebenen befassen können. In diesem Lernpfad werden wir von unten nach oben nacheinander die folgenden Ebenen betrachten:
Überwachung
Diese Ebene bildet die wichtige Grundlage, auf der die weiteren Ebenen aufbauen. Sie fungiert als Informationsquelle und liefert objektive Daten, auf deren Grundlage Sie sich ein konkretes Bild von der Zuverlässigkeit in Ihrer Organisation machen können. Wenn Sie etwas ändern möchten, können Sie sich auf diese Weise ein Bild über die Auswirkung machen. Konkret lernen Sie in dieser Übung zu erkennen, ob Ihre Maßnahmen die Zuverlässigkeit erhöhen oder nicht. Erst wenn Sie über gute Kenntnisse zum Thema Überwachung verfügen, können Sie den Rest der Aufgaben abschließen.
Reaktion auf Incidents
In jeder Produktionsumgebung kommt es irgendwann einmal zu einem Ausfall. Das ist unstrittig. In einem solchen Fall kommen Fragen wie diese auf: „Was ist zu tun, wenn ein Incident auftritt? Was geschieht, wenn Systeme ausfallen und Kunden betroffen sind?“ Sie benötigen einen Standardprozess, um das Problem effektiv zu bewerten, die richtigen Ressourcen einzusetzen und dann die Auswirkungen des Problems abzumildern. Gleichzeitig möchten Sie sicherstellen, dass die Betroffenen über das Problem informiert werden.
Überprüfung nach dem Incident (Lernen aus Fehlern)
Dieser Prozess ermöglicht uns, unsere Betriebsmethoden zu verbessern, indem wir die Erfahrungen aus jedem bedeutenden Vorfall gemeinsam untersuchen, bewerten und diskutieren. Die Analyse im Anschluss an den Vorfall ermöglicht uns, aus Fehlern zu lernen, und ist entscheidend für unsere Anstrengungen für mehr Zuverlässigkeit.
Test/Release (Bereitstellung)
Im nächsten Schritt konzentrieren wir uns auf die Test-, Release- und Bereitstellungsprozesse. Hier geht es gewissermaßen um folgende Frage: „Wie gut sind Sie darin, Systeme und Prozesse zu entwickeln, die Probleme erkennen, bevor sie zu Incidents führen?“
Kapazitätsplanung/Skalierung
Erfolg und das daraus resultierende Wachstum können die Zuverlässigkeit genauso bedrohen wie jedes andere Systemproblem. Ein Kunde kann nicht unterscheiden zwischen einem System, das wegen eines Fehlers im Code ausgefallen ist, und einem System, das nicht funktioniert, weil zu viele Leute gleichzeitig darauf zugreifen wollen. Auf dieser Ebene der Hierarchie geht es darum, der Kapazitätsplanung und Skalierung als Mittel zur Bekämpfung dieser Bedrohung Aufmerksamkeit zu schenken.
Entwicklungsprozess und Benutzererfahrung
In der Hierarchie gibt es noch zwei weitere Ebenen, die im Lernpfad Verbessern der Zuverlässigkeit nicht behandelt werden: den Entwicklungsprozess und die Arbeit, die in das Schaffen eines guten Benutzererlebnisses einfließt. Diese beiden Themen sind nicht Gegenstand des Lernpfads Verbessern der Zuverlässigkeit, aber es stehen weitere hilfreiche Learn-Module zu diesen Themen zur Verfügung.
Wir haben für jede Ebene in der Hierarchie der Zuverlässigkeit ein eigenes Learn-Modul erstellt. Wir hoffen, dass Sie alle fünf Module dieses Lernpfads absolvieren.