Beschreiben von Azure Site Recovery
Contoso muss eine Strategie für Geschäftskontinuität und Notfallwiederherstellung (Business Continuity und Disaster Recovery, BCDR) einführen, um Daten zu sichern und Anwendungen und Workloads auch bei geplanten und ungeplanten Ausfällen online bereitzustellen. Contoso kann Azure Site Recovery nutzen, um die Geschäftskontinuität zu gewährleisten, indem Geschäftsanwendungen und Workloads während Ausfällen weiter ausgeführt werden.
Azure Site Recovery repliziert Workloads, die auf physischen Servern und VMs ausgeführt werden, aus einem primären Standort an einen sekundären Standort. Bei einem Ausfall des primären Contoso-Standorts werden die Workloads an einen sekundären Standort ausgelagert, und Benutzer können von dort aus auf Apps zugreifen. Wenn der primäre Speicherort erneut ausgeführt wird, kann ein Administrator ein Failback für Workloads auf den primären Standort durchführen.
Azure Site Recovery kann die Replikation für folgende Bereiche verwalten:
- Replikation von virtuellen Azure-Computern zwischen Azure-Regionen
- Lokale VMs, Azure Stack-VMs und physische Server.
Was ist Azure Site Recovery?
Durch die Verwendung von Azure Site Recovery können Sie Ihre VMs zwischen Azure-Regionen replizieren. Es ist auch möglich, Azure Site Recovery zu verwenden, um lokale VMs und physische Server aus Ihrer lokalen Infrastruktur zu Azure zu migrieren. Angenommen, Contoso hatte einen Ausfall in der New Yorker Niederlassung, vielleicht aufgrund einer Überschwemmung. Das Unternehmen kann Azure Site Recovery verwenden, um solche Ausfälle durch ein Failover auf Azure abzumildern.
Es sind die Standortwiederherstellungsfunktionen in Azure Site Recovery, mit denen Sie zukünftige Ausfälle umgehen können. Azure Site Recovery wurde entwickelt, um Ihre Workloads von einem bestimmten primären Standort oder einer Region in einen sekundären Standort oder eine sekundäre Region zu replizieren, den bzw. die Sie ausgewählt haben. In der folgenden Abbildung befindet sich die primäre Region in „USA, Osten“, während die sekundäre Region „USA, Mitte“ ist.
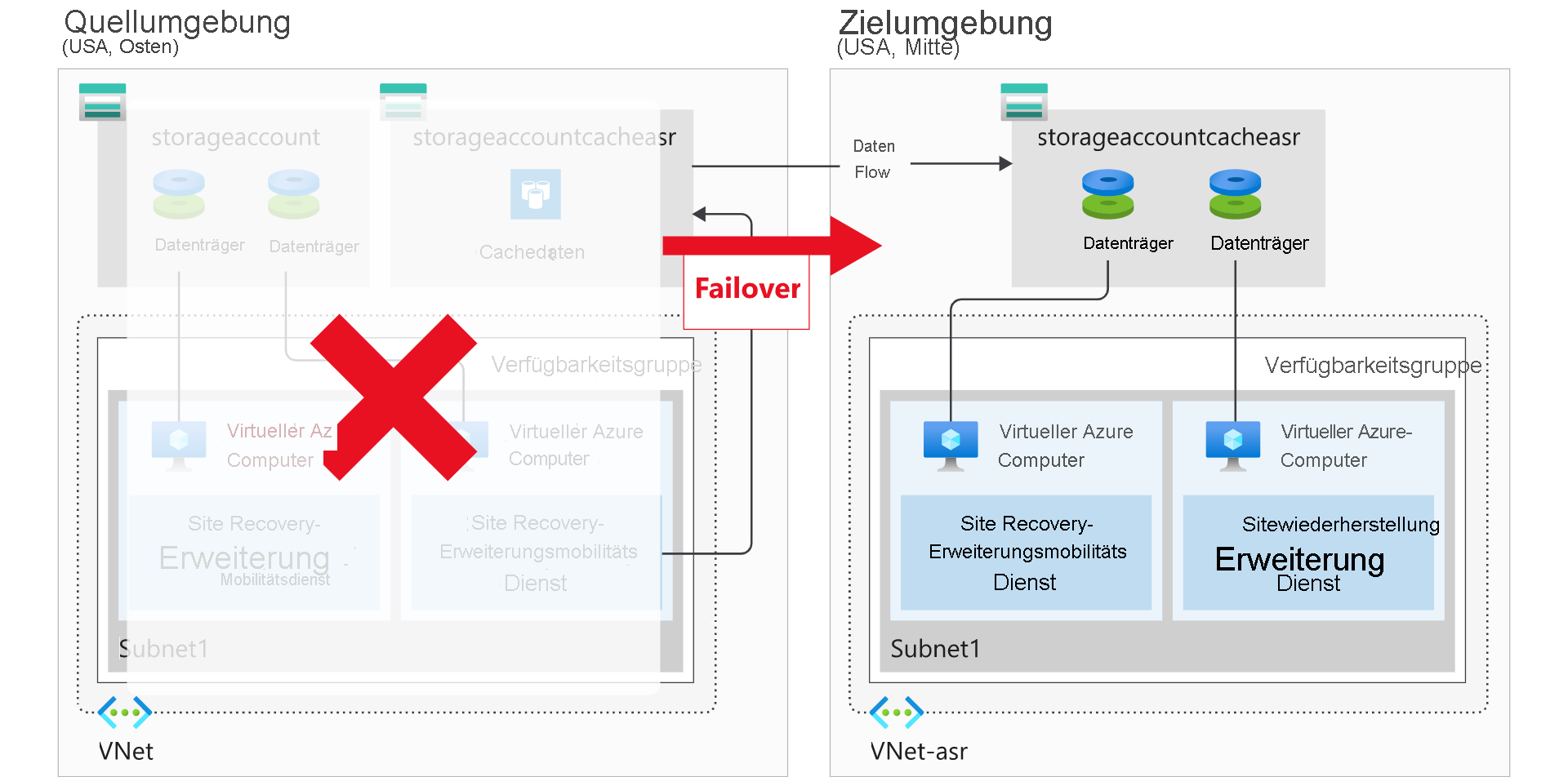
Azure Site Recovery verwaltet die Replikation von:
- Azure-VMs zwischen Regionen.
- Lokale VMs in Azure und zurück.
Tipp
Da Azure Site Recovery eine integrierte Komponente von Azure ist, kann die Anwendung nahtlose Tests (so genannte Drillvorgänge für Notfallwiederherstellung) durchführen, ohne Ihre Produktionsworkloads zu beeinträchtigen. Dies bedeutet, dass Sie überprüfen können, ob Ihre Notfallwiederherstellungspläne wirksam sind, wenn Sie benötigt werden sollten.
Azure Site Recovery stellt die Funktionen bereit, die in der folgenden Tabelle beschrieben werden.
| Funktion | BESCHREIBUNG |
|---|---|
| Schutz virtueller Azure-Computer | Mit Azure Site Recovery können Sie Ihre VMs in Azure automatisch schützen. Azure Site Recovery spiegelt die Konfiguration der Quell-VM in eine sekundäre Azure-Region und erstellt alle erforderlichen oder zugehörigen Ressourcengruppen, Speicherkonten, VNets und Verfügbarkeitsgruppen. Den Ressourcen, die Azure Site Recovery erstellt, wird ein Azure Site Recovery-Suffix hinzugefügt. |
| Momentaufnahmen und Wiederherstellungspunkte | Azure Site Recovery verfügt über Replikationsrichtlinien, die Sie anpassen können. Mit diesen Richtlinien können Sie den Aufbewahrungsverlauf von Wiederherstellungspunkten und die Häufigkeit von Momentaufnahmen festlegen. Sie können einen Wiederherstellungspunkt aus einer Momentaufnahme des Datenträgers einer VM erstellen. Es sind zwei verschiedene Momentaufnahmen verfügbar: absturzkonsistente und App-konsistente. Die absturzkonsistente Wiederherstellung stellt die Daten auf dem Datenträger zum Erstellungszeitpunkt der Momentaufnahme dar. Die App-konsistente Wiederherstellung erfasst die gleichen Daten wie die absturzkonsistente Wiederherstellung, schließt aber auch alle In-Memory-Daten und In-Process-Transaktionen ein. Durch Einschließen der In-Memory-Daten kann Azure Site Recovery eine VM und alle ausgeführten Apps ohne Datenverlust wiederherstellen. Alle Wiederherstellungspunkte werden standardmäßig 24 Stunden lang aufbewahrt. Sie können diesen Zeitraum jedoch auf 72 Stunden verlängern. |
| Replikation in eine sekundäre Region | Wenn Sie Replikation für eine Azure-VM aktivieren, wird der Azure Site Recovery-Mobilitätsdienst installiert. Diese Erweiterung registriert die VM bei Azure Site Recovery. Die fortlaufende Replikation der VM beginnt damit. Dabei werden alle Schreibvorgänge auf den Datenträger sofort an ein lokales Speicherkonto übertragen. Azure Site Recovery verwendet dieses Konto, um den Cache in ein Speicherkonto in der Zielumgebung zu replizieren. Azure Site Recovery kopiert die im Cache gespeicherten Daten und synchronisiert sie entweder mit dem Zielspeicherkonto oder den replizierten verwalteten Datenträgern. Nach der Verarbeitung der Daten werden absturzkonsistente Wiederherstellungspunkte erstellt. Wenn App-konsistente Wiederherstellungspunkte aktiviert sind, werden sie nach dem Zeitplan generiert, der in der Azure Site Recovery-Replikationsrichtlinie festgelegt ist. |
| Notfallwiederherstellungsübungen | Azure Site Recovery ermöglicht das Ausführen von Notfallwiederherstellungsübungen, nachdem Sie alle erforderlichen Konfigurationsaufgaben abgeschlossen haben. Indem Sie einen Drillvorgang durchführen, können Sie die Replikationsstrategie für Ihre Umgebung validieren, ohne dass Daten verloren gehen, Ausfallzeiten entstehen oder Ihre Produktionsumgebung gefährdet wird. |
| Flexibles Failover und Failback | Sie können Azure Site Recovery-Failover und -Failback schnell starten, indem Sie das Azure-Portal verwenden. Bei der Ausführung eines Failovers wählen Sie einen Wiederherstellungspunkt aus und lassen dann Azure Site Recovery das Failover verwalten. Ein Failback ist einfach der umgekehrte Vorgang. Wenn ein Failover erfolgreich ausgeführt wurde, kann ein Failback ausgeführt werden. |
Failover und Failback mit Azure Site Recovery
Azure Site Recovery ermöglicht Ihrer Organisation Flexibilität, um entweder manuell ein Failover in eine sekundäre Azure-Region durchzuführen oder ein Failback auf eine Quell-VM vorzunehmen. Der einfachste Weg, diesen Vorgang zu verwalten, ist manuell über das Azure-Portal.
Ein Failover erfolgt, wenn Sie entscheiden, einen Notfallwiederherstellungsplan für Ihre Organisation durchzuführen. Die vorhandene Produktionsumgebung, die durch Azure Site Recovery geschützt wird, wird auf eine andere Region umgeschaltet. Die Zielumgebung wird zur Produktionsumgebung, in der die Produktionsdienste Ihrer Organisation weiter ausgeführt werden.
Hinweis
Sobald die Zielregion aktiv ist, sollte die Quellumgebung nicht mehr verwendet werden. Dies wird dadurch erzwungen, dass die Quell-VMs beendet bleiben.
Es gibt einen weiteren Vorteil beim Herunterfahren der Quell-VMS. Die Verwendung einer heruntergefahrenen VM führt nur zu minimalem Datenverlust, weil Azure Site Recovery wartet, bis alle Daten auf den Datenträger geschrieben wurden, bevor das Failover ausgelöst wird.
Was ist der erneute Schutz, und warum ist dieser wichtig?
Wenn für eine VM ein Failover erfolgt, findet die von Azure Site Recovery durchgeführte Replikation nicht mehr statt. Stattdessen müssen Sie den Schutz erneut aktivieren, um mit dem Schutz der Failover-VM zu beginnen. Da die Infrastruktur bereits in einer anderen Region ist, können Sie die Replikation zurück in die Quellregion starten. Durch den erneuten Schutz kann Azure Site Recovery die neue Zielumgebung erneut in die ursprüngliche Quellumgebung replizieren.
Die Flexibilität, die das Ausführen eines Failovers für einzelne VMs oder mithilfe eines Wiederherstellungsplans Ihnen bietet, kann zum erneuten Schützen der betroffenen Infrastruktur verwendet werden. Sie können jede VM einzeln oder mehrere VMs mithilfe eines Wiederherstellungsplans erneut schützen.
Hinweis
Die Wiederherstellung des Schutzes dauert je nach Größe und Art der VM bis zu zwei Stunden. Im Gegensatz zu den anderen Site Recovery-Prozessen, die Sie durch Überwachung des Fortschritts überwachen können, müssen Sie den erneuten Schutz auf VM-Ebene überwachen.
Was ist ein Failback?
Ein Failback ist das Gegenteil eines Failovers. Ein Failback liegt vor, wenn ein Failover auf eine sekundäre Region abgeschlossen wurde, die jetzt zur Produktionsumgebung geworden ist. Die Wiederherstellung des Schutzes wurde für Umgebung abgeschlossen, für die ein Failover ausgeführt wurde, und die Quellumgebung ist jetzt deren Replikat.
Hinweis
In einem Failbackszenario führt Azure Site Recovery ein Failover auf die Quell-VMS zurück aus.
Failover-Arten
Site Recovery stellt verschiedene Failoveroptionen bereit:
- Testen des Failovers. Sie verwenden diese Option, um einen Drillvorgang auszuführen, der Ihre BCDR-Strategie ohne Datenverlust oder Ausfallzeiten validiert. Es wird eine Kopie der VM in Azure erstellt, ohne dass sich dies auf laufende Replikationsprozesse oder Ihre Produktionsumgebung auswirkt. So überprüfen Sie Ihre BCDR-Strategie:
- Führen Sie ein Testfailover für eine einzelne VM oder mehrere VMs in einem Wiederherstellungsplan aus.
- Wählen Sie einen Wiederherstellungspunkt für das Testfailover aus.
- Wählen Sie ein Azure-Netzwerk aus, in dem die Azure-VM platziert wird, wenn sie nach dem Failover erstellt wird. Das Netzwerk wird nur für das Testfailover verwendet.
- Überprüfen Sie, ob das Testfailover wie erwartet funktioniert hat. Nach dem Test bereinigt Site Recovery automatisch alle VMs, die während der Übung in Azure erstellt wurden.
- Geplantes failover-Hyper-V. Üblicherweise für geplante Wartungsarbeiten verwendet, werden bei einer geplanten Failover-Hyper-V-Strategie die Quell-VMs heruntergefahren und die neuesten Daten synchronisiert, bevor das Failover eingeleitet wird. Das geplante Failover verursacht einige Ausfallzeiten, aber während des geplanten Failovers gehen keine Daten verloren.
- Planen Sie ein Wartungsfenster für die Ausfallzeit, und benachrichtigen Sie die Benutzer.
- Schalten Sie Apps für Benutzer offline.
- Initiieren Sie ein geplantes Failover mit dem neuesten Wiederherstellungspunkt. (Das Failover wird nicht ausgeführt, wenn der Computer nicht heruntergefahren wird oder wenn Fehler auftreten.)
- Überprüfen Sie nach dem Failover, ob die Azure-Replikat-VM in Azure aktiv ist.
- Führen Sie ein Commit für das Failover aus, um den Vorgang abzuschließen. Die Commitaktion löscht alle verfügbaren Wiederherstellungspunkte.
- Failover-Hyper-V. Normalerweise führen Sie diese Failoveroption aus, wenn ein ungeplanter Ausfall auftritt oder der primäre Standort nicht verfügbar ist. Optional können Sie die VM herunterfahren und letzte Änderungen synchronisieren, bevor Sie das Failover einleiten. Diese Methode führt zu minimalem Datenverlust für Apps.
- Initiieren Sie Ihren BCDR-Plan.
- Initiieren Sie ein Failover. Legen Sie vor dem Auslösen des Failovers fest, ob Site Recovery die VM herunterfahren und die letzten Änderungen synchronisieren/replizieren soll.
- Sie können ein Failover für eine Reihe unterschiedlicher Wiederherstellungspunktoptionen ausführen:
- Wenn Sie die Option zum Herunterfahren der VM nicht aktivieren oder Site Recovery die VM nicht herunterfahren kann, wird der letzte Wiederherstellungspunkt verwendet.
- Das Failover wird auch dann ausgeführt, wenn der Computer nicht heruntergefahren werden kann.
- Überprüfen Sie nach dem Failover, ob die Azure-Replikat-VM in Azure aktiv ist. Ggf. können Sie aus dem Aufbewahrungszeitraum, der 24 Stunden umfasst, einen anderen Wiederherstellungspunkt auswählen.
- Führen Sie ein Commit für das Failover aus, um den Vorgang abzuschließen. Die Commitaktion löscht alle verfügbaren Wiederherstellungspunkte.
- Failover-VMware. Diese Failoveroption wird normalerweise ausgeführt, wenn ein ungeplanter Ausfall auftritt oder der primäre Standort nicht verfügbar ist. Optional können Sie angeben, dass Site Recovery versuchen soll, ein Herunterfahren der VM auszulösen und letzte Änderungen zu synchronisieren und zu replizieren, bevor das Failover eingeleitet wird. Die Verwendung dieser Methode führt zu minimalem Datenverlust für Apps.
- Initiieren Sie Ihren BCDR-Plan.
- Initiieren Sie ein Failover aus Site Recovery:
- Geben Sie an, ob Site Recovery versuchen soll, das Herunterfahren der VM auszulösen und eine Synchronisierung durchzuführen, bevor das Failover ausgeführt wird. (Das Failover wird auch dann ausgeführt, wenn die Computer nicht heruntergefahren werden können.)
- Überprüfen Sie nach dem Failover, ob die Azure-Replikat-VM in Azure aktiv ist.
- Wenn erforderlich, können Sie aus dem Aufbewahrungszeitraum, der 72 Stunden umfasst, einen anderen Wiederherstellungspunkt auswählen.
- Führen Sie ein Commit für das Failover aus, um den Vorgang abzuschließen. Die Commitaktion löscht alle Wiederherstellungspunkte. Bei Windows-VMs deaktiviert Site Recovery die VMware-Tools während des Failovers.