Modellieren kleiner Nachschlageentitäten
Unser Datenmodell enthält zwei kleine Verweisdatenentitäten, ProductCategory und ProductTag. Diese Entitäten werden für Verweiswerte verwendet und sind anderen Entitäten durch eine 1:Many relationship zugeordnet.
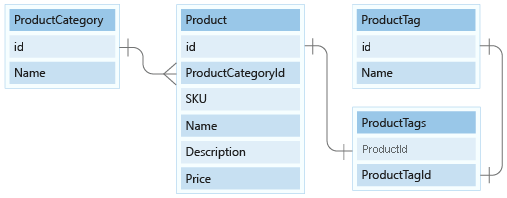
In dieser Lerneinheit modellieren wir die Entitäten ProductCategory und ProductTag in unserem Dokumentmodell.
Modellieren von Produktkategorien
Für die Kategorien modellieren wir zunächst die Daten mit den Spalten ID und Name als einzige Eigenschaften und fügen sie in einen neuen Container namens ProductCategory ein.
Als Nächstes muss ein Partitionsschlüssel ausgewählt werden. Nachstehend werden die Vorgänge erläutert, die für diese Daten ausgeführt werden müssen.
Sie erstellen eine neue Produktkategorie, dann bearbeiten Sie eine Produktkategorie, dann listen Sie alle Produktkategorien auf. Produktkategorien werden nicht häufig erstellt und bearbeitet. Unsere E-Commerce-Anwendung listet häufig alle Produktkategorien auf, wenn Kunden die Website besuchen. Der letzte Vorgang ist also der am häufigsten ausgeführte.
Die Abfrage für diesen letzten Vorgang sieht wie folgt aus: SELECT * FROM c.
Mit ID als ausgewähltem Partitionsschlüssel wird diese Abfrage jetzt partitionsübergreifend ausgeführt, auch wenn wir versuchen möchten, diese leseintensiven Vorgänge zu optimieren, indem wir möglichst nur eine einzelne Partition verwenden. Wir wissen auch, dass die Daten für die Produktkategorie niemals annähernd 20 GB groß sein werden, sodass diese Information uns bei der Modellierung der Daten in einer Weise helfen würde, die zu einer Abfrage mit einer einzelnen Partition führt, wenn wir alle Produktkategorien auflisten.
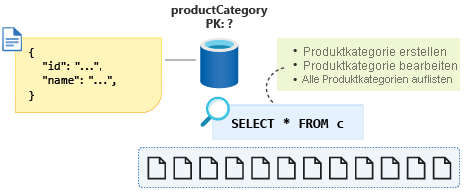
Um diese geringe Datenmenge wieder in eine einzelne Partition zu zwingen, können wir die Entitätsdiskriminatoreigenschaft zu unserem Schema hinzufügen und diese als Partitionsschlüssel für diesen Container verwenden. Indem wir dieser Eigenschaft einen konstanten Wert für alle Dokumente dieses Typs im Container zuweisen, stellen wir sicher, dass wir jetzt eine einzige Partitionsabfrage haben. In diesem Fall rufen wir die Eigenschaft type auf und geben einen konstanten Wert von category an. Unsere Abfrage würde nun wie folgt aussehen: SELECT * FROM c WHERE c.type = ”category”.

Modellieren von Produkttags
Als nächstes folgt die Entität ProductTag. Diese Entität ist in ihrer Funktion fast identisch mit der ProductCategory-Entität, die wir im vorherigen Abschnitt besprochen haben. Wir gehen hier genauso vor und modellieren das Dokument so, dass es ID- und Name-Eigenschaften enthält, und erstellen eine Entitätsdiskriminatoreigenschaft mit dem Namen type, in diesem Fall mit einem konstanten Wert von tag. Es wird ein neuer Container mit der Bezeichnung ProductTag erstellt und type als neuer Partitionsschlüssel festgelegt.
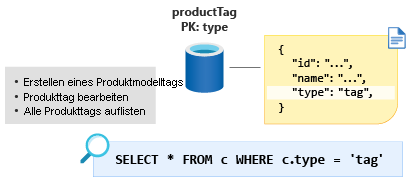
Einige Benutzer finden diese Technik zum Modellieren kleiner Nachschlagetabellen ungewöhnlich. Wenn die Daten auf diese Weise modelliert werden, ist es möglich, eine weitere Optimierung im nächsten Modul vorzunehmen.