Erkunden trainierbarer Klassifizierer
Organisationen klassifizieren Inhalte und versehen sie mit Bezeichnungen, um sie schützen und ordnungsgemäß behandeln zu können. Inhalte klassifizieren und mit Bezeichnungen versehen ist der Ausgangspunkt für den Informationsschutz. Microsoft 365 bietet drei Möglichkeiten zum Klassifizieren von Inhalten:
Manuell: Die manuelle Klassifizierung erfordert menschliches Urteilsvermögen und Handeln. Benutzer und Administratoren wenden sie auf Inhalte an, wenn sie darauf stoßen. Sie können entweder die bereits vorhandenen Bezeichnungen und Typen vertraulicher Informationen oder selbst erstellte verwenden. Anschließend können Sie den Inhalt schützen und seine Löschung verwalten.
Automatisierter Musterabgleich: Diese Kategorie von Klassifizierungsmechanismen umfasst das Ermitteln von Inhalten anhand von:
- Schlüsselwörtern oder Metadatenwerten (Keyword Query Language)
- Zuvor identifizierten Mustern vertraulicher Informationen wie Sozialversicherungs-, Kreditkarten- oder Bankkontonummern
- Einem Element, bei dem es sich um eine Variation einer Vorlage handelt (ein sog. Dokumentfingerabdruck, der in einer späteren Lerneinheit behandelt wird)
- Dem Vorhandensein exakter Zeichenfolgen-/Datenübereinstimmungen
Trainierbare Klassifizierungen: Ein trainierbarer Microsoft 365-Klassifizierer ist ein Tool, das eine Organisation darauf "trainieren" kann, verschiedene Inhaltstypen zu erkennen. Microsoft 365 umfasst zahlreiche vordefinierte Klassifizierer. Organisationen können auch eigene benutzerdefinierte Klassifizierer erstellen. Klassifizierer können trainiert werden, indem Sie ihnen Beispiele zum Analysieren bereitstellen. Nachdem ein Klassifizierer trainiert wurde, kann eine Organisation damit Elemente identifizieren, auf die Office-Vertraulichkeitsbezeichnungen, Richtlinien für die Kommunikationscompliance bzw. für Aufbewahrungsbezeichnungen angewendet werden sollen.
In dieser Lerneinheit wird die Verwendung trainierbarer Klassifizierer erläutert.
Trainierbare Klassifizierungsmerkmale
Um mit der Verwendung trainierbarer Klassifizierer in Microsoft Purview zu beginnen, können Sie zunächst einen Analysescan starten. Bei diesem Vorgang werden die Daten Ihres Unternehmens analysiert und Muster identifiziert, die das System zum Trainieren des Klassifizierers verwenden kann. Nachdem das System Ihre Daten gescannt hat, identifiziert es gängige Themen und Muster. Das System kann mithilfe dieser Informationen Regeln für den trainierbaren Klassifizierer erstellen. Dieser Prozess trägt dazu bei, sicherzustellen, dass der trainierbare Klassifizierer bei der Identifizierung und Kategorisierung von Daten genau und effektiv ist. Sobald der Scanvorgang abgeschlossen ist, können Sie den trainierbaren Klassifizierer mit den identifizierten Mustern und Regeln trainieren. Nachdem Sie das Training des Klassifizierers abgeschlossen haben, können Sie ihn auf neue Daten anwenden, um sie automatisch zu klassifizieren.
Warnung
Es kann 7 bis 14 Tage dauern, bis der Analysescan abgeschlossen ist. Wenn Sie keinen Scan durchführen möchten, um einen benutzerdefinierten trainierbaren Klassifizierer für Ihre Organisation zu erstellen, können Sie die in Microsoft Purview integrierten Klassifizierer verwenden.
Wenn Sie zum ersten Mal die Seite Trainingsklassifizierer im Microsoft Purview-Complianceportal öffnen, wird das im folgenden Screenshot dargestellt Dialogfeld angezeigt.
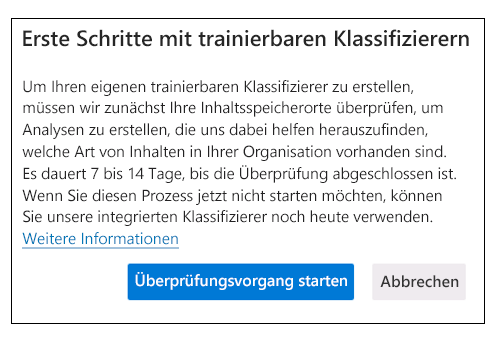
Das Erstellen eines benutzerdefinierten trainierbaren Klassifizierers umfasst zunächst die Bereitstellung manuell ausgewählter Beispiele, die der Kategorie positiv entsprechen. Nachdem der trainierbare Klassifizierer diese Stichproben verarbeitet hat, testen Sie dessen Fähigkeit zur Vorhersage, indem Sie ihm eine Mischung aus positiven und negativen Stichproben bereitstellen. In dieser Lerneinheit wird das Erstellen und Trainieren eines benutzerdefinierten Klassifizierers erläutert. Außerdem wird untersucht, wie die Leistung von benutzerdefinierten trainierbaren Klassifizierern und vortrainierten Klassifizierern während ihrer Lebensdauer durch erneutes Training verbessert werden kann.
Die Klassifizierungsmethode eignet sich gut für Inhalte, die mit automatisierten oder manuellen Musterabgleichsmethoden nicht einfach identifiziert werden können. Bei dieser Klassifizierungsmethode geht es eher um die Verwendung eines Klassifizierers, um ein Element anhand dessen zu identifizieren, was das Element ist, und nicht anhand von Elementen, die sich im Element befinden (Musterabgleich). Ein Klassifizierer lernt, eine Art von Inhalt zu identifizieren, indem er hunderte Beispiele des entsprechenden Inhaltstyps analysiert.
Hinweis
Sie können trainierbare Klassifizierer im Inhaltsexplorer anzeigen, indem Sie "Trainierbare Klassifizierer" im Filterbereich erweitern. Die trainierbaren Klassifizierer zeigen automatisch die Anzahl der in SharePoint, Microsoft Teams und OneDrive gefundenen Vorkommen an, ohne dass eine Bezeichnung erforderlich ist. Wenn Sie dieses Feature nicht verwenden möchten, müssen Sie eine Anforderung an den Microsoft-Support stellen, um die standardmäßige Klassifizierung zu deaktivieren. Dadurch wird die Analyse vertraulicher und mit Bezeichnungen versehener Inhalte vor dem Erstellen von Bezeichnungsrichtlinien deaktiviert.
Klassifizierer können als Bedingung für Folgendes verwendet werden:
- Automatisches Anwenden von Vertraulichkeitsbezeichnungen in Office
- Automatisches Anwenden einer Richtlinie für Aufbewahrungsbezeichnungen auf der Grundlage einer Bedingung
- Kommunikationscompliance
Hinweis
Klassifizierer funktionieren nur mit unverschlüsselten Elementen.
Es gibt zwei Arten von trainierbaren Klassifizierern:
- Vortrainierte Klassifizierer: Microsoft hat mehrere Klassifizierer erstellt und vorab trainiert, die Sie ohne weiteres Training verwenden können. Diese Klassifizierer weisen den Status Einsatzbereit auf.
- Benutzerdefinierte trainierbare Klassifizierer: Wenn die Klassifizierungsanforderungen einer Organisation über das hinausgehen, was die vortrainierten Klassifizierer abdecken, können eigene Klassifizierer erstellt und trainiert werden.
In den folgenden Abschnitten werden diese Klassifizierertypen näher beleuchtet.
Vortrainierte Klassifizierer
Microsoft 365 bietet mehrere vortrainierte Klassifizierer:
Nicht jugendfrei, anstößig und blutrünstig: Erkennt Bilder dieser Kategorien. Die Bilder müssen zwischen 50 KB (Kilobyte) und 4 MB (Megabyte) groß sein. Sie müssen außerdem größer als 50 x 50 Pixel (Höhe x Breite) sein. Das System unterstützt die Analyse von und Erkennung in Exchange Online E-Mail-Nachrichten sowie in Microsoft Teams-Kanälen und Chats.
Verträge und Vereinbarungen: Dieser Klassifizierer erkennt Inhalte im Zusammenhang mit rechtlichen Vereinbarungen. Beispiele hierfür sind Leistungsbeschreibungen, Darlehens- und Mietverträge sowie Arbeitsverträge und Wettbewerbsklauseln.
Kundenbeschwerden: Der Klassifizierer für Kundenbeschwerden erkennt Feedback und Beschwerden zu den Produkten oder Dienstleistungen Ihrer Organisation. Dieser Klassifizierer kann Ihnen helfen, gesetzliche Anforderungen hinsichtlich der Erkennung und Sichtung von Beschwerden zu erfüllen, z. B. die Anforderungen des Consumer Financial Protection Bureau (Verbraucherschutzbehörde) und der Food and Drug Administration (US-amerikanische Behörde für Lebensmittel- und Arzneimittelsicherheit).
Diskriminierung: Dieser Klassifizierer erkennt explizit diskriminierende Sprache und reagiert auf diskriminierende Sprache gegenüber der Afroamerikanischen/Schwarzen Community, wenn sie mit anderen Bevölkerungsgruppen verglichen werden.
Finanzen: Dieser Klassifizierer erkennt Inhalte der Kategorien Unternehmensfinanzierung, Buchhaltung, Wirtschaft, Banking und Investment.
Belästigungen: Dieser Klassifizierer erkennt eine bestimmte Kategorie beleidigender Textelemente. Diese Elemente müssen im Zusammenhang mit beleidigendem Verhalten stehen, das gegen eine oder mehreren Personen gerichtet ist, basierend auf den folgenden Merkmalen: ethnische Zugehörigkeit, Religion, nationale Herkunft, Geschlecht, sexuelle Orientierung, Alter, Behinderung.
Gesundheitswesen: Dieser Klassifizierer erkennt Inhalte im Zusammenhang mit medizinischen und verwaltungstechnischen Aspekten im Gesundheitswesen. Zum Beispiel medizinische Dienstleistungen, Diagnosen, Behandlungen, Ansprüche usw.
Personalwesen: Dieser Klassifizierer erkennt Inhalte, die mit dem Personalwesen in Zusammenhang stehen. Beispiele für diese Inhaltskategorien: Einstellung, Vorstellungsgespräche, Personalsuche, Schulung, Bewertung, Abmahnung und Kündigung.
Geistiges Eigentum: Dieser Klassifizierer erkennt Inhalte in Kategorien mit Bezug auf geistiges Eigentum, z. B. Geschäftsgeheimnisse und ähnliche vertrauliche Informationen.
Informationstechnologie (IT): Dieser Klassifizierer erkennt Inhalte in den Kategorien Informationstechnologie und Cybersicherheit. Beispiele hierfür sind Netzwerkeinstellungen, Informationssicherheit, Hardware und Software.
Rechtsangelegenheiten: Dieser Klassifizierer erkennt Inhalte in Kategorien, die mit Rechtsfragen zu tun haben. Zum Beispiel Rechtsstreitigkeiten, Gerichtsverfahren, rechtliche Auflagen, Rechtsterminologie, Gesetze und Gesetzgebung.
Beschaffung: Dieser Klassifizierer erkennt Inhalte in Kategorien wie Angebote, Ausschreibungen, Kauf und Bezahlung für die Lieferung von Waren und Dienstleistungen.
Obszönitäten: Dieser Klassifizierer erkennt eine bestimmte Kategorie von Textelementen in anstößiger Sprache, die Ausdrücke enthalten, die für die meisten Menschen peinlich sind.
Lebensläufe: Dieser Klassifizierer erkennt DOCX-, PDF-, RTF- und TXT-Elemente, bei denen es sich um die Darstellung in Textform der persönlichen, schulischen und beruflichen Qualifikationen eines Bewerbers, seiner Berufserfahrung und anderer persönlicher Informationen handelt.
Quellcode: Dieser Klassifizierer erkennt Elemente, die eine Reihe von Anweisungen und Angaben enthalten, die in den 25 auf GitHub am häufigsten verwendeten Programmiersprachen geschrieben wurden: ActionScript, C, C#, C++, Clojure, CoffeeScript, Go, Haskell, Java, JavaScript, Lua, MATLAB, Objective-C, Perl, PHP, Python, R, Ruby, Scala, Shell, Swift, TeX, Vim Script.
Hinweis
Der Quellcodeklassifizierer erkennt, wenn der Großteil des Texts aus Quellcode besteht. Er erkennt keinen Quelltext, der mit einfachem Text durchsetzt ist.
Steuerrecht: Dieser Klassifizierer erkennt Inhalte mit Bezug auf steuerrechtliche Aspekte wie Steuerplanung, Steuerformulare, Steuererklärungen, Steuervorschriften.
Bedrohung. Dieser Klassifizierer erkennt eine bestimmte Kategorie von Textelementen in anstößiger Sprache im Zusammenhang mit Gewaltandrohungen oder Körperverletzung oder Schaden an einer Person oder einer Sache.
Diese trainierbaren Klassifizierer werden im Microsoft Purview-Complianceportal angezeigt. Wählen Sie im Navigationsbereich Datenklassifizierung aus. Wählen Sie auf der Seite Datenklassifizierung die Registerkarte Trainierbare Klassifizierer aus. Zeigen Sie die Klassifizierer mit dem Status Einsatzbereit an.
Benutzerdefinierte trainierbare Klassifizierer
Die vortrainierten Klassifizierer erfüllen nicht alle Datenklassifizierungsanforderungen einiger Organisationen. In solchen Fällen kann eine Organisation eigene Klassifizierer erstellen und trainieren. Das Erstellen eines benutzerdefinierten Klassifizierer erfordert mehr Arbeit, aber sie können besser an die Anforderungen einer Organisation angepasst werden. Die allgemeinen Schritte zum Erstellen eines benutzerdefinierten Klassifizierers umfassen:
- Sie beginnen mit der Erstellung eines benutzerdefinierten trainierbaren Klassifizierers, indem Sie ihn Beispiele analysieren lassen, die voll und ganz der betreffenden Kategorie entsprechen.
- Nachdem der Klassifizierer diese Beispiele verarbeitet hat, testen Sie ihn, indem Sie ihm eine Mischung aus übereinstimmenden und nicht übereinstimmenden Beispielen bereitstellen.
- Der Klassifizierer trifft dann Vorhersagen darüber, ob ein bestimmtes Element in die Kategorie fällt, die Sie erstellen.
- Anschließend überprüfen Sie die Ergebnisse und sortieren sie nach Positiv, Negativ, Falsch-Positiv und Falsch-Negativ, um die Genauigkeit der Vorhersagen des Klassifizierers zu erhöhen.
- Wenn Sie mit den Testergebnissen zufrieden sind, veröffentlichen Sie den Klassifizierer, um ihn bereitzustellen.
Wenn Sie den Klassifizierer veröffentlichen, geht er die Elemente an Speicherorten wie SharePoint Online, Exchange und OneDrive durch und klassifiziert die Inhalte. Nachdem Sie den Klassifizierer veröffentlicht haben, können Sie ihn mittels eines Feedbackprozesses trainieren, der dem anfänglichen Trainingsprozess ähnelt.
Sie können trainierbare Klassifizierer u. A. für Folgendes erstellen:
- Rechtsdokumente: Beispielsweise Anwaltsgeheimnisse, Transaktionsabschlüsse und Leistungsbeschreibungen.
- Strategische Geschäftsdokumente: Beispielsweise Pressemitteilungen, Fusionen und Übernahmen, Deals, Geschäfts- oder Marketingpläne, geistiges Eigentum, Patente und Designdokumente.
- Preisinformationen: Beispielsweise Rechnungen, Preisangebote, Arbeitsaufträge und Gebotsdokumente.
- Finanzinformationen: Beispielsweise Organisationsinvestitionen und Quartals- oder Jahresergebnisse.
Vorbereitung auf einen benutzerdefinierten trainierbaren Klassifizierer
Vor dem Einstieg ist es hilfreich, die Komponenten zu verstehen, die an der Erstellung eines benutzerdefinierten trainierbaren Klassifizierers beteiligt sind. In den folgenden Abschnitten werden die einzelnen Komponenten näher erläutert.
Zeitachse
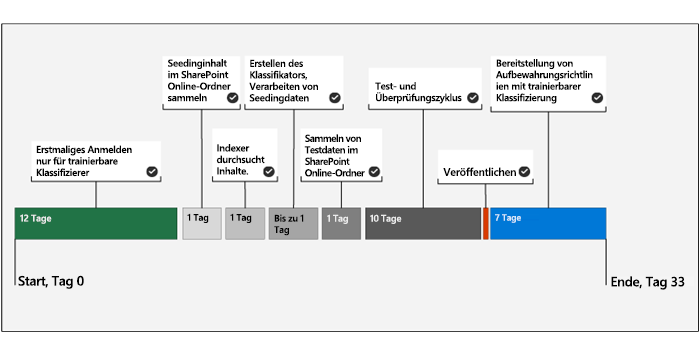
Das folgende Diagramm zeigt eine Zeitleiste, die eine Beispielbereitstellung trainierbarer Klassifizierer darstellt.
Tipp
Das System erfordert ein einmaliges Opt-in für trainierbare Klassifizierer. Die grundlegende Bewertung der Inhalte einer Organisation durch Microsoft 365 nimmt 12 Tage in Anspruch. Der Opt-in-Vorgang muss von einem globalen Microsoft 365-Administrator gestartet werden.
Allgemeiner Workflow
Ausführlichere Informationen zum allgemeinen Workflow zum Erstellen benutzerdefinierter trainierbarer Klassifizierer finden Sie unter Ablauf zum Erstellen benutzerdefinierter trainierbarer Klassifizierer.
Seeding-Inhalte
Microsoft Purview verwendet trainierbare Klassifizierer, um ein Element unabhängig und präzise einer bestimmten Inhaltskategorie zuzuordnen. Um einen trainierbaren Klassifizierer zu erstellen, muss eine Organisation ihn zunächst viele Beispiele des Inhaltstyps der betreffenden Kategorie analysieren lassen. "Seeding" ist der Prozess, bei dem dem trainierbaren Klassifizierer Proben zugeführt werden. Eine Organisation muss die Seeding-Inhalte auswählen, die repräsentativ für eine bestimmte Inhaltskategorie verwendet werden sollen.
Tipp
Sie benötigen mindestens 50 positive Stichproben (maximal 500 Stichproben). Der trainierbare Klassifizierer verarbeitet bis zu 500 zuletzt erstellte Stichproben (nach Erstellungsdatum/Zeitstempel der Dateien). Je mehr Beispiele Sie bereitstellen, desto genauer sind die Vorhersagen des Klassifizierers.
Testinhalte
Sobald der trainierbare Klassifizierer genügend positive Stichproben verarbeitet hat, um ein Vorhersagemodell zu erstellen, muss die Organisation testen, wie seine Vorhersagen ausfallen. Sie sollten die Tests mit anderen Daten als den anfänglich verwendeten Seeding-Daten durchführen. Bei den Tests sollte überprüft werden, ob der Klassifizierer in der Lage ist, korrekt zwischen Elementen zu unterscheiden, die zu einer bestimmten Kategorie gehören, und solchen, bei denen dies nicht der Fall ist. Die Tests sollten mit anderen, möglichst umfangreicheren, manuell ausgewählten Inhalten beginnen, der sog. Testprobe. Diese sollte aus Stichproben bestehen, die in die betreffende Kategorie fallen, sowie aus solchen, bei denen dies nicht der Fall ist.
Nachdem der Klassifizierer dieses Testbeispiel verarbeitet hat, müssen Sie die Ergebnisse manuell überprüfen. Dabei sollten Sie überprüfen, ob die einzelnen Vorhersagen richtig oder falsch sind bzw. ob es unsicher ist, ob sie zutreffen. Der trainierbare Klassifizierer verbessert anhand dieses Feedbacks sein Vorhersagemodell.
Tipp
Um optimale Ergebnisse zu erzielen, verwenden Sie mindestens 200 Elemente in Ihrer Testprobe. Sie sollte eine gleichmäßige Verteilung positiver und negativer Übereinstimmungen enthalten.