Microsoft Dataverse erkunden
Microsoft Dataverse ist eine cloudbasierte Lösung, die auf einfache Weise eine Vielzahl von Daten und Geschäftslogiken strukturiert, um miteinander verbundene Anwendungen und Prozesse auf sichere und konforme Weise zu unterstützen. Dataverse wird von Microsoft verwaltet und gepflegt. Es ist global verfügbar, wird jedoch geografisch bereitgestellt, um Ihrer potenziellen Datenresidenz zu entsprechen. Es ist nicht für die Offline‑ oder eigenständige Verwendung auf Ihren Servern vorgesehen. Aus diesem Grund benötigen Sie zum Zugriff und zur Verwendung eine Internetverbindung.
Dataverse unterscheidet sich von herkömmlichen Datenbanken dadurch, dass es mehr als nur Tabellen enthält. Es integriert Sicherheit, Logik, Daten und Speicher an einem zentralen Ort. Es ist als Ihr zentrales Datenrepository für Geschäftsdaten konzipiert, und möglicherweise nutzen Sie es sogar bereits. Im Hintergrund unterstützt es viele Microsoft Dynamics 365-Lösungen, wie Field Service, Customer Insights, Customer Service und Sales. Es ist auch als Teil von Power Apps und Power Automate mit direkt eingebauter nativer Konnektivität erhältlich. Die AI Builder‑ und Portalfunktionen der Microsoft Power Platform nutzen auch Dataverse.
Das Bild zeigt eine Visualisierung, die die vielen Angebote von Microsoft Dataverse zusammenbringt.
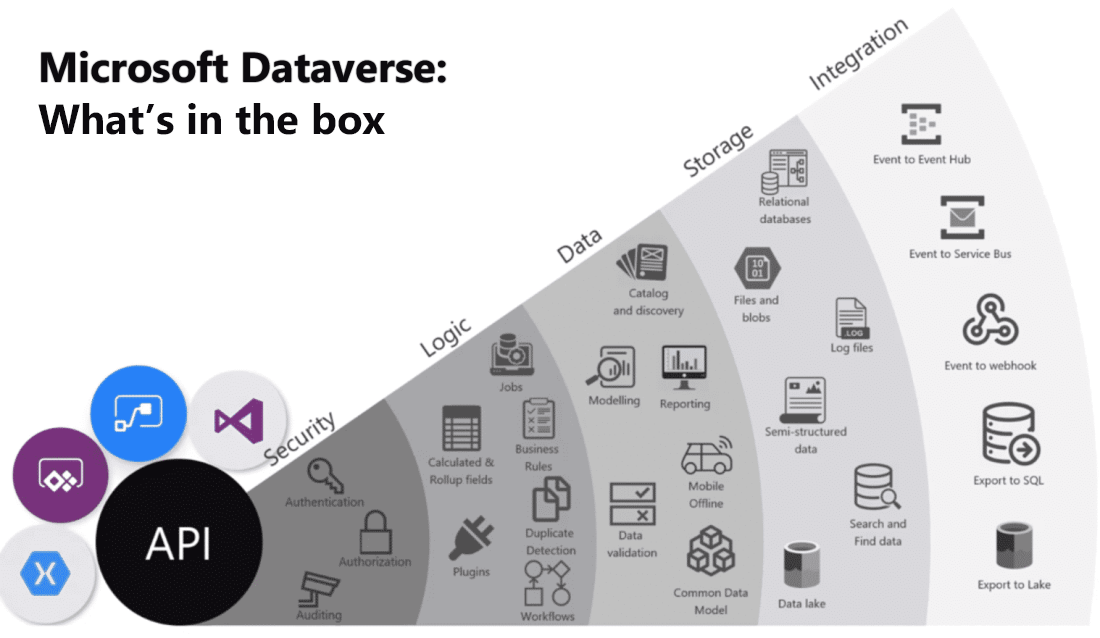
Hier gibt es eine kurze Erklärung der einzelnen Funktionskategorien.
Sicherheit: Dataverse übernimmt die Authentifizierung mit Azure Active Directory (Azure AD) und ermöglicht so bedingten Zugriff und mehrstufige Authentifizierung. Es unterstützt die Autorisierung bis auf Zeilen‑ und Spaltenebene und bietet umfangreiche Funktionen zur Überwachung.
Logik: Dataverse ermöglicht es Ihnen, einfach Geschäftslogik auf Datenebene anzuwenden. Es gelten die gleichen Regeln, unabhängig davon, wie ein Benutzer mit den Daten interagiert. Diese Regeln können sich auf Duplikaterkennung, Geschäftsregeln, Workflows usw. beziehen.
Daten: Dataverse bietet Ihnen die Kontrolle über die Gestaltung Ihrer Daten und ermöglicht Ihnen, Ihre Daten zu entdecken, zu modellieren, zu validieren und Berichte über sie zu erstellen. Diese Steuerung stellt sicher, dass Ihre Daten so aussehen, wie Sie es möchten, unabhängig davon, wie Sie sie verwenden.
Speicher: Dataverse speichert Ihre physische Daten in der Azure-Cloud. Dieser cloudbasierte Speicher nimmt Ihnen die Sorge darüber, wo sich Ihre Daten befinden oder wie sie skaliert werden. Dies wird alles für Sie gehandhabt.
Integration: Dataverse verbindet sich auf unterschiedliche Arten, um Ihre Geschäftsanforderungen zu unterstützen. APIs, Webhooks, Ereignisse und Datenexporte geben Ihnen die Flexibilität, Daten ein‑ und auszugeben.
Wie Sie sehen können, ist Microsoft Dataverse eine leistungsstarke cloudbasierte Lösung zum Speichern und Arbeiten mit Ihren Geschäftsdaten. In den folgenden Abschnitten betrachten Sie Microsoft Dataverse aus der Perspektive der Datenspeicherung für Microsoft Power Platform, wo Sie Ihre Reise beginnen. Denken Sie auch an die anderen umfangreichen Funktionen, die wir besprochen haben. Sie werden im Laufe der Zeit mehr darüber erfahren.
Um zu beginnen, können Sie mit Microsoft Dataverse eine oder mehrere cloudbasierte Instanzen einer standardisierten Datenbank erstellen. Die Datenbank enthält vordefinierte Tabellen und Spalten, in denen Daten gespeichert werden, die in fast allen Organisationen und Unternehmen häufig vorkommen. Sie können die Speicherungen auch anpassen und erweitern, indem Sie neue Spalten oder Tabellen hinzufügen. Durch das einfache Einrichten einer Microsoft Dataverse-Datenbank und eines darunter stehenden standardisierten Datenmodells können Sie sich stärker auf die Erstellung von Lösungen konzentrieren, ohne sich um Infrastruktur, Speicher und Datenintegration kümmern zu müssen. Mit Ihren in Microsoft Dataverse gespeicherten Daten gibt es viele Möglichkeiten, darauf zuzugreifen. Sie können mit den Daten mit Tools wie Power Apps oder Power Automate nativ arbeiten. Jede Geschäftslösung kann zu Dataverse mit Konnektor-APIs Verbindungen herstellen. Dank der Leistungsfähigkeit von Features wie der rollenbasierten Sicherheit und Geschäftsregeln können Sie darauf vertrauen, dass Ihre Daten sicher sind – unabhängig davon, wie auf diese zugegriffen wird.
Skalierbarkeit
Eine Dataverse-Datenbank unterstützt große Datensätze und komplexe Datenmodelle. Tabellen können Millionen von Elementen enthalten; den Speicher in jeder Instanz einer Microsoft Dataverse-Datenbank können Sie auf vier (4) Terabyte erweitern. Die in Ihrer Microsoft Dataverse-Instanz verfügbare Datenmenge basiert auf Anzahl und Typ der damit verknüpften Lizenzen. Der Datenspeicher wird unter allen lizenzierten Benutzern gebündelt, sodass Sie für jede von Ihnen erstellte Lösung nach Bedarf Speicher zuweisen können. Benötigen Sie mehr Speicher, als in der Standardlizenzierung angeboten wird, können Sie inkrementellen Speicher erwerben.
Struktur und Vorteile von Microsoft Dataverse
Die Struktur einer Microsoft Dataverse-Datenbank basiert auf den Definitionen und dem Schema im Common Data Model. Mit dem Common Data Model als Basis für eine Microsoft Dataverse-Datenbank vereinfacht die Integration von Lösungen, die ein Common Data Model-Schema verwenden. Denn das Common Data Model ist die Grundlage einer Microsoft Dataverse-Datenbank und verwendet ein Common Data Model-Schema. Die Standardtabellen der Lösung sind die gleichen. Außerdem profitieren Sie von einem umfassenden Ökosystem an Lösungen, die Anbieter mithilfe des Common Data Model entwickelt haben. Und das Beste ist, dass es praktisch keine Einschränkung gibt, wie stark Sie eine Microsoft Dataverse-Datenbank erweitern können.
Tabellen, Spalten und Beziehungen beschreiben
Eine Tabelle ist eine logische Struktur, die Zeilen und Spalten enthält, die einen Datensatz darstellen. Im Screenshot werden die Standard-Kontotabelle und verschiedene Elemente angezeigt, die als Teil davon verwaltet werden können.
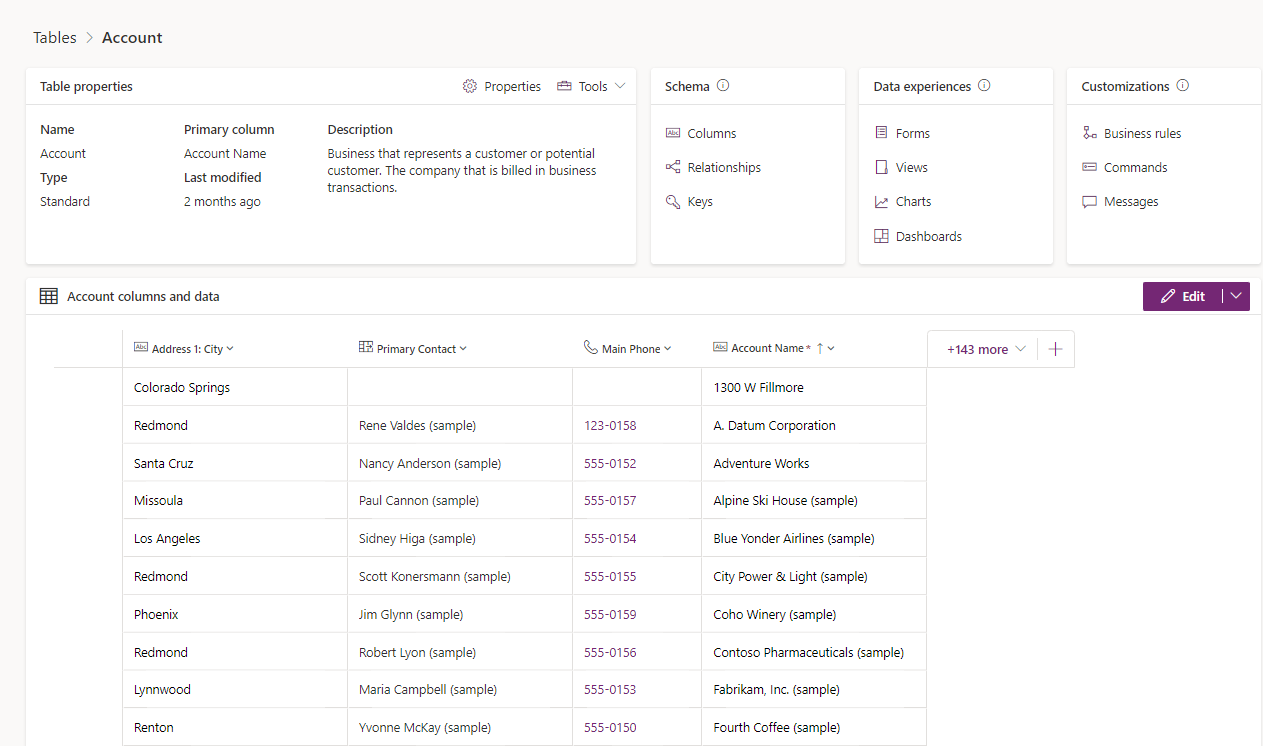
Tabellentypen
Es gibt drei Tabellentypen:
Standard – Mehrere Standardtabellen, auch vorkonfigurierte Tabellen genannt, sind in einer Dataverse-Umgebung enthalten. Konten-, Geschäftsbereichs-, Kontakt-, Aufgaben‑ und Benutzertabellen sind Beispiele für Standardtabellen in Dataverse. Die meisten der im Lieferumfang von Dataverse enthaltenen Standardtabellen können angepasst werden.
Verwaltet – Sind Tabellen, die nicht anpassbar sind und als Teil einer verwalteten Lösung in die Umgebung importiert wurden.
Benutzerdefiniert – Benutzerdefinierte Tabellen sind nicht verwaltete Tabellen, die entweder aus einer nicht verwalteten Lösung importiert werden oder neue Tabellen sind, die direkt in der Dataverse-Umgebung erstellt werden.
Spalten
Spalten sind eine Möglichkeit, einzelne Informationen in einer Zeile einer Tabelle zu speichern. Sie können sie sich als eine Spalte in Excel vorstellen. Spalten haben Datentypen, d. h. Sie können Daten eines bestimmten Typs in einer Spalte speichern, die diesem Datentyp entspricht. Wenn Sie beispielsweise eine Lösung haben, die Datumsangaben erfordert, wie z. B. die Erfassung des Datums eines Ereignisses oder des Zeitpunkts, zu dem etwas passiert ist, dann speichern Sie das Datum in einer Spalte mit dem Typ „Datum“. Genauso speichern Sie die Nummer in einer Spalte mit dem Nummerntyp, wenn Sie eine Nummer speichern möchten.
Die Anzahl der Spalten innerhalb einer Tabelle variiert von einigen Spalten bis zu Hundert oder mehr. Jede Datenbank in Microsoft Dataverse beginnt mit einer Standardmenge an Tabellen und jede Standardtabelle verfügt über eine Standardmenge an Spalten.
Beziehungen verstehen
Für eine effiziente und skalierbare Lösung für die meisten von Ihnen erstellten Lösungen müssen Sie Daten in verschiedene Container (Tabellen) aufteilen. Der Versuch, alles in einem einzigen Container zu speichern, wäre wahrscheinlich ineffizient und schwierig zu verstehen.
Das folgende Beispiel veranschaulicht dieses Konzept.
Stellen Sie sich vor, dass Sie ein System zur Verwaltung von Verkaufsaufträgen erstellen müssen. Sie benötigen eine Produktliste mit dem vorhandenen Bestand, den Kosten des Artikels und dem Verkaufspreis. Sie benötigen auch eine Masterliste der Kunden mit deren Adressen und Kreditwürdigkeiten. Schließlich müssen Sie auch Verkaufsrechnungen verwalten, um Rechnungsdaten zu speichern. Die Rechnung sollte folgende Informationen enthalten:
Datum
Rechnungsnummer
Vertriebsmitarbeiter
Kundeninformationen einschließlich Adresse und Bonität
Eine Position für jeden Artikel auf der Rechnung
Jede Position sollte einen Verweis auf das verkaufte Produkt enthalten. Die Einzelposition sollte auch die korrekten Kosten und Preise für jedes Produkt enthalten. Und schließlich sollte die Zeile auch die verfügbare Menge basierend auf der Menge verringern, die Sie in dieser Position verkauft haben.
Die Erstellung einer einzelnen Tabelle zur Unterstützung der Funktionen im Beispiel wäre ineffizient. Ein besserer Ansatz für dieses Geschäftsszenario besteht darin, die folgenden vier Tabellen zu erstellen:
Kunden
Produkte
Rechnungen
Positionen
Durch das Erstellen einer Tabelle für jedes dieser Elemente und das Verknüpfen dieser Elemente können Sie eine effiziente Lösung erstellen, die skaliert werden kann und gleichzeitig eine hohe Leistungsfähigkeit gewährleistet. Das Aufteilen der Daten in mehrere Tabellen bedeutet auch, dass Sie keine sich wiederholenden Daten speichern oder große Zeilen mit großen Mengen leerer Daten unterstützen müssen. Die Berichterstellung ist zudem erheblich vereinfacht, wenn Sie die Daten in separate Tabellen aufteilen.
Tabellen, die sich aufeinander beziehen, haben eine relationale Verbindung. Beziehungen zwischen Tabellen existieren auf verschiedene Arten, aber die beiden häufigsten sind „Eins-zu-Viele“ und „Viele-zu-Viele“, von denen beide von Microsoft Dataverse unterstützt werden. Weitere Informationen zu den verschiedenen Beziehungstypen finden Sie unter: Tabellenbeziehungen.
Geschäftslogik in Microsoft Dataverse
Viele Organisationen haben eine Geschäftslogik, die sich auf ihre Arbeit mit Daten auswirkt. Beispielsweise eine Organisation, die Dataverse verwendet, um Kundeninformationen zu speichern, möchte möglicherweise das Feld „Identifikationsnummer“ als Pflichtfeld festlegen. In Microsoft Dataverse erstellen Sie diese Logik mit Geschäftsregeln. Mit Geschäftsregeln können Sie Geschäftslogik auf Datenebene anstatt auf App-Ebene anwenden und verwalten. Wenn Sie also grundsätzlich Geschäftsregeln in Microsoft Dataverse erstellen, sind die Regeln unabhängig davon wirksam, wie Benutzer mit den Daten interagieren.
Geschäftsregeln werden beispielsweise in Canvas‑ oder modellgesteuerten Apps verwendet, um Werte in einem oder mehreren Spalten einer Tabelle festzulegen oder zu löschen. Sie können auch verwendet werden, um gespeicherte Daten zu validieren oder Fehlermeldungen anzuzeigen. Modellgesteuerte Apps können Geschäftsregeln verwenden, um Spalten ein‑ oder auszublenden, Spalten zu aktivieren oder zu deaktivieren und Empfehlungen basierend auf Business Intelligence zu erstellen.
Mit Geschäftsregeln können Sie Regeln erzwingen, Werte festlegen oder Daten validieren, unabhängig davon, in welcher Form Daten eingegeben werden. Geschäftsregeln tragen effektiv dazu bei, die Genauigkeit von Daten zu erhöhen, die Anwendungsentwicklung zu vereinfachen und die Formulare für Endbenutzer zu optimieren.
Betrachten Sie dieses Beispiel für eine einfache, aber leistungsstarke Anwendung von Geschäftsregeln. Die Geschäftsregel ist so konfiguriert, dass das Feld Kreditlimit-VP-Genehmiger als Pflichtfeld gekennzeichnet wird, wenn der Kreditrahmen auf mehr als $1,000,000 festgelegt ist. Wenn der Kreditrahmen unter $1,000,000 liegt, bleibt das Feld optional.
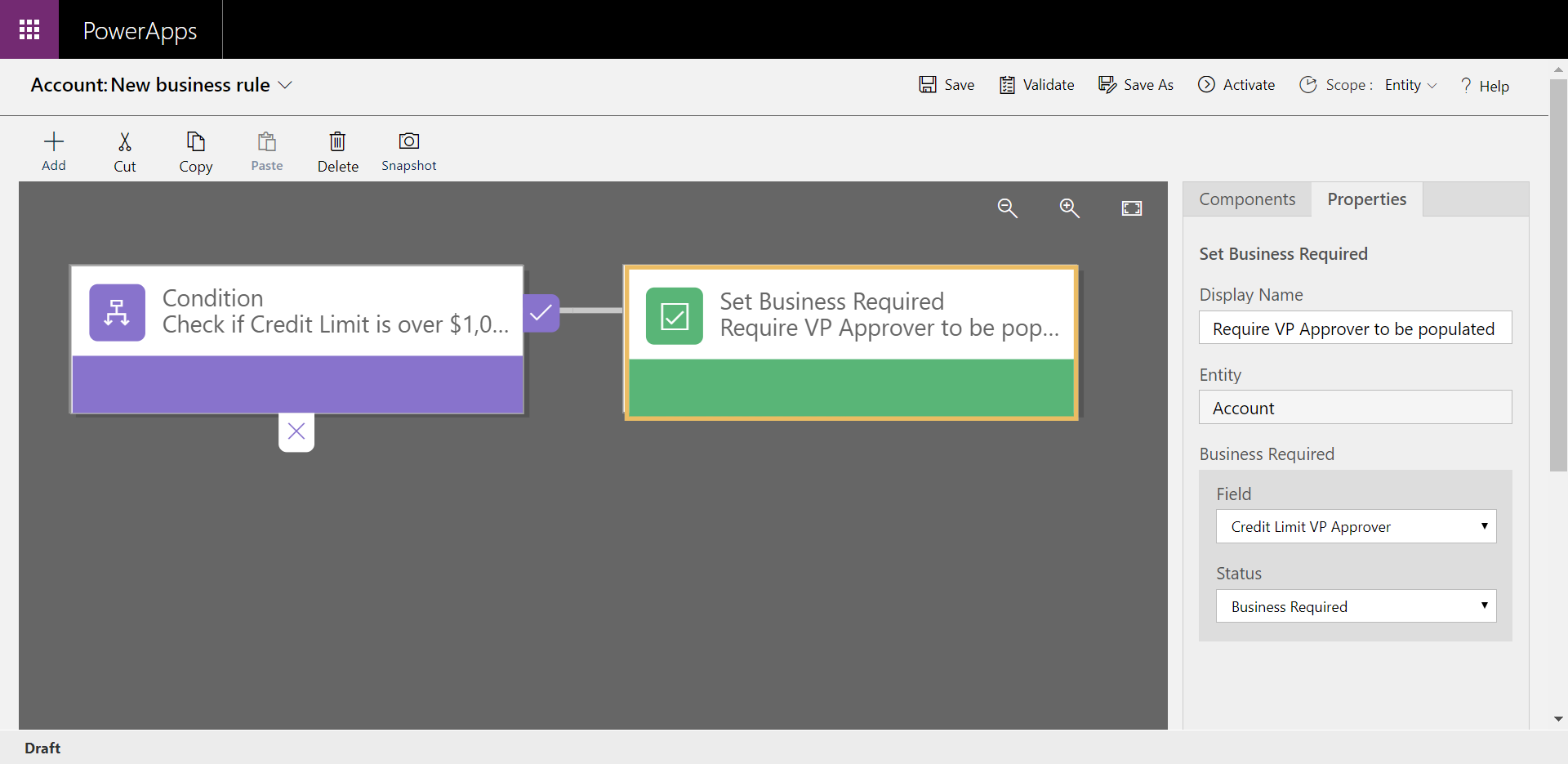
Wenn Sie diese Geschäftsregel auf Datenebene und nicht auf App-Ebene anwenden, haben Sie mehr Kontrolle über Ihre Daten. So wird sichergestellt, dass Ihre Geschäftslogik befolgt wird, unabhängig davon, ob der Zugriff direkt von Power Apps, Power Automate oder sogar über eine API erfolgt. Die Regel ist an die Daten gebunden, nicht an die App.
Weitere Informationen zur Verwendung von Geschäftsregeln in Dataverse finden Sie unter: EineGeschäftsregel für eine Tabelle erstellen.
Mit Dataflows arbeiten
Dataflows sind eine cloudbasierte Self-Service-Technologie zur Datenaufbereitung. Mit Dataflows können Daten aufgenommen, umgewandelt und in Microsoft Dataverse-Umgebungen, Power BI-Arbeitsbereiche oder das Azure Data Lake Storage-Konto von Ihrer Organisation laden. Dataflows werden mit Power Query erstellt, einer einheitlichen Datenkonnektivitäts‑ und Vorbereitungserfahrung, die bereits in vielen Microsoft-Produkten, wie Excel und Power BI, enthalten ist. Debitoren können Dataflows auslösen, dass sie entweder bei Bedarf oder automatisch nach einem Zeitplan ausgeführt werden, und die Daten bleiben immer auf dem neuesten Stand.
Da ein Dataflow die resultierenden Entitäten in einem cloudbasierten Speicher speichert, können andere Dienste mit den von Dataflows erzeugten Daten interagieren.
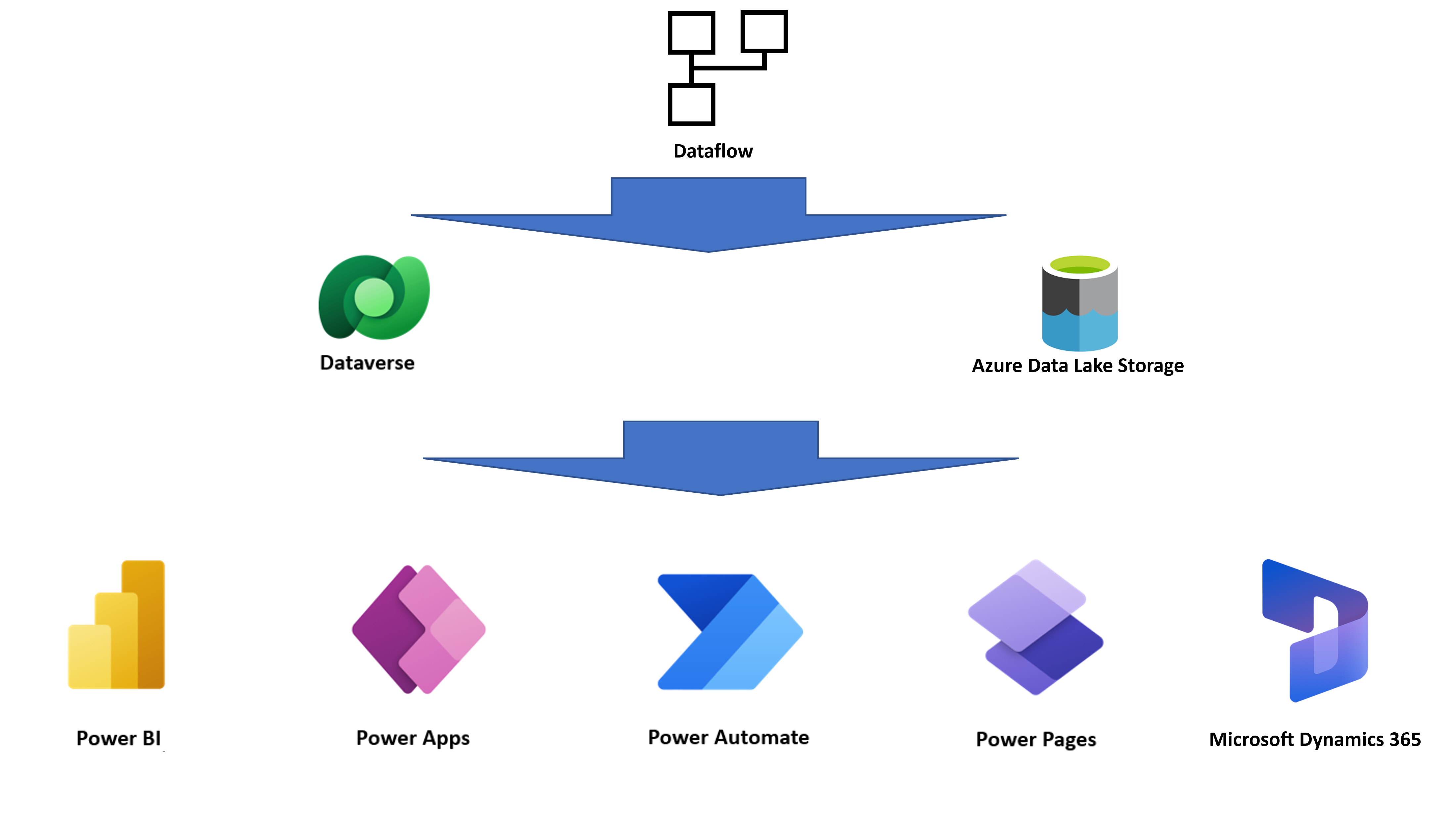
Beispielsweise können Power BI‑, Power Apps‑, Power Automate-, Power Virtual Agents‑ und Dynamics 365-Anwendungen die vom Dataflow erzeugten Daten abrufen, indem sie eine Verbindung zu Dataverse, einem Power Platform-Dataflow-Konnektor herstellen. Alternativ können sie die Daten direkt über den Lake beziehen, je nachdem, welches Ziel bei der Erstellung des Dataflows konfiguriert wurde.
Die folgende Liste hebt einige der Vorteile der Verwendung von Dataflows hervor:
Ein Dataflow entkoppelt die Datentransformationsebene von der Modellierungs‑ und Visualisierungsebene in einer Power BI-Lösung.
Der Datenumwandlungscode kann an einem zentralen Ort, einem Dataflow, gespeichert werden, anstatt über mehrere Artefakte verteilt zu sein.
Ein Dataflow-Ersteller benötigt nur Power Query-Skills. In einer Umgebung mit mehreren Entwicklern kann der Entwickler des Dataflows Teil eines Teams sein, das gemeinsam die gesamte BI-Lösung oder betriebliche Anwendung erstellt.
Ein Dataflow ist produktunabhängig. Es handelt sich dabei nicht nur um eine Komponente von Power BI, da Sie die Daten auch in anderen Tools und Diensten abrufen können.
Dataflows profitieren von Power Query, einer leistungsstarken, grafischen Self-Service-Datentransformationserfahrung.
Dataflows werden vollständig in der Cloud ausgeführt. Es wird keine andere Infrastruktur erforderlich.
Sie haben mehrere Möglichkeiten, mit der Arbeit mit Dataflows zu beginnen, indem Sie Lizenzen für Power Apps, Power BI und Customer Insights verwenden.
Dataflows ermöglichen erweiterte Transformationen, sind jedoch für Self-Service-Szenarien konzipiert und erfordern keine IT‑ oder Entwicklerkenntnisse.
Common Data Model
Bei der Entwicklung von Geschäftslösungen müssen Sie oft Daten aus unterschiedlichen Geschäftsanwendungen Ihres Unternehmens integrieren. Manchmal kann es eine Herausforderung sein, diese App-übergreifende Integration zu erreichen. Obwohl die Daten ähnlich sind, werden sie nicht unbedingt in allen Anwendungen auf die gleiche Art und Weise gespeichert. Mehrere Technologieführer haben die Initiative „Common Data Model“ ins Leben gerufen, um dabei zu helfen, dies zu vereinfachen. Das Ziel ist eine gemeinsame Struktur, die einfach auf verschiedene Anwendungen angewendet werden kann. Organisationen können ihre eigenen Datentypen und Tags erstellen und gemeinsam verwenden, indem sie das Common Data Model von Microsoft verwenden, das über ein umfassendes Metadatensystem verfügt. Dies trägt dazu bei, wertvolle Geschäftseinblicke zu erhalten, die mit Daten integriert und angereichert werden können, um umsetzbare Informationen bereitzustellen.
Mit dem Common Data Model können Sie Ihre Daten so strukturieren, dass sie Konzepte und Aktivitäten repräsentieren, die allgemein verwendet werden und leicht zu verstehen sind. Sie können diese Daten abfragen und analysieren, sie erneut verwenden und mit anderen Unternehmen und Apps zusammenarbeiten, die das gleiche Format nutzen. Organisationen können ihre eigenen Datentypen und Tags erstellen und gemeinsam verwenden, indem sie das Common Data Model von Microsoft verwenden, das über ein umfassendes Metadatensystem verfügt.
Sie können die für Sie verfügbaren Tabellendefinitionen verwenden, anstatt ein neues Datenmodell für Ihre App zu erstellen. Das Common Data Model wird von verschiedenen Anwendungen und Diensten verwendet, dazu gehören Microsoft Dataverse, Dynamics 365 Microsoft Power Platform und Azure. Dieses gemeinsame Datenmodell stellt sicher, dass alle Ihre Dienste auf die gleichen Daten zugreifen können. Ein passendes Beispiel für die Nutzung des Common Data Model sind die Datenvorbereitungsfunktionen in Power BI-Dataflows. Diese Dataflows erstellen Datendateien, die der Common Data Model-Definition entsprechen. Diese Datendateien sind im Azure Data Lake gespeichert. Die Definitionen des Common Data Model sind offen und stehen für jeden Dienst oder jede Anwendung zur Verfügung, die sie verwenden möchte.

Daten, die mit dem Common Data Model beschrieben wurden, können mit Azure-Diensten verwendet werden, um eine skalierbare analytische Lösung zu erstellen. Es kann außerdem eine Quelle semantisch reichhaltiger Daten für Anwendungen sein, die umsetzbare Erkenntnisse liefern, wie z. B. Dynamics 365 Customer Insights. Das Common Data Model wird zum Definieren von Entitäten für Dynamics 365-Anwendungen in den Bereichen Sales, Finance, Supply Chain Management und Commerce verwendet und ist im Azure Data Lake sofort verfügbar.
Microsoft erweitert das Common Data Model in Zusammenarbeit mit vielen Partnern und Fachexperten weiterhin. Durch den Aufbau von Branchenbeschleunigern ermöglicht Microsoft den folgenden Branchen, vom Common Data Model und den unterstützenden Plattformen zu profitieren: