Arbeiten mit Microsoft Fabric-Lakehouses
Nachdem Sie sich mit den wichtigsten Funktionen eines Microsoft Fabric-Lakehouses vertraut gemacht haben, erfahren Sie, wie Sie damit arbeiten können.
Erstellen und Erkunden eines Lakehouse
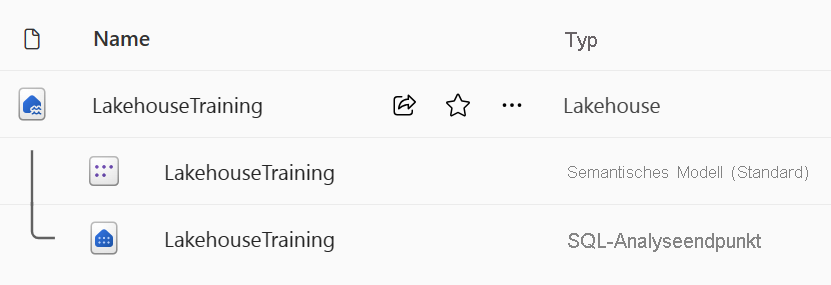
Wenn Sie ein neues Lakehouse erstellen, werden automatisch drei verschiedene Datenelemente in Ihrem Arbeitsbereich erstellt.
- Das Lakehouse enthält Verknüpfungen, Ordner, Dateien und Tabellen.
- Das Semantikmodell (Standard) stellt eine einfache Datenquelle für das Entwickeln von Power BI-Berichten bereit.
- Der SQL-Analyseendpunkt ermöglicht schreibgeschützten Zugriff auf Abfragedaten mit SQL.
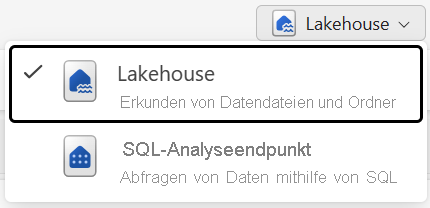
Sie können mit den Daten im Lakehouse in zwei Modi arbeiten:
- Mit einem Lakehouse können Sie Tabellen, Dateien und Ordner im Lakehouse hinzufügen und damit interagieren.
- Mit dem SQL-Analyseendpunkt können Sie SQL verwenden, um die Tabellen im Lakehouse abzufragen und sein relationales semantisches Modell zu verwalten.
Erfassen von Daten in einem Lakehouse
Das Erfassen von Daten in Ihrem Lakehouse ist der erste Schritt im ETL-Prozess. Verwenden Sie eine der folgenden Methoden, um Daten in Ihr Lakehouse zu übertragen.
- Hochladen: Laden Sie lokale Dateien hoch.
- Dataflows Gen2: Importieren und transformieren Sie Daten mithilfe von Power Query.
- Notebooks: Verwenden Sie Apache Spark, um Daten zu erfassen, zu transformieren und zu laden.
- Data Factory-Pipelines: Verwenden Sie die Aktivität „Daten kopieren“.
Diese Daten können anschließend direkt in Dateien oder Tabellen geladen werden. Entscheiden Sie für Ihr Datenlademuster beim Erfassen von Daten, ob Sie alle Rohdaten als Dateien laden sollten, bevor Sie Stagingtabellen verarbeiten oder verwenden.
Spark-Auftragsdefinitionen können ebenfalls dazu verwendet werden, Batch-/Streamingaufträge an Spark-Cluster zu übermitteln. Indem Sie die Binärdateien aus der Kompilierungsausgabe verschiedener Sprachen hochladen (z. B. JAR aus Java), können Sie eine andere Transformationslogik auf die in einem Lakehouse gehosteten Daten anwenden. Über die Binärdatei hinaus können Sie das Verhalten des Auftrags weiter anpassen, indem Sie zusätzliche Bibliotheken und Befehlszeilenargumente hochladen.
Hinweis
Weitere Informationen finden Sie in der Dokumentation zum Erstellen einer Apache Spark-Auftragsdefinition.
Datenzugriff über Verknüpfungen
Eine weitere Möglichkeit, auf Daten in Fabric zuzugreifen und diese zu verwenden, ist die Verwendung von Verknüpfungen. Mit Verknüpfungen können Sie Daten mit Ihr Lakehouse integrieren, während sie im externen Speicher gespeichert bleiben.
Verknüpfungen sind nützlich, wenn Sie Daten aus einem anderen Speicherkonto oder sogar von einem anderen Cloudanbieter beziehen müssen. Sie können in Ihrem Lakehouse Verknüpfungen erstellen, die auf verschiedene Speicherkonten und andere Fabric-Elemente wie Data Warehouses, KQL-Datenbanken und andere Lakehouses verweisen.
Quelldatenberechtigungen und Anmeldeinformationen werden alle von OneLake verwaltet. Beim Zugriff auf Daten über eine Verknüpfung mit einem anderen OneLake-Standort wird die Identität des aufrufenden Benutzers verwendet, um den Zugriff auf die Daten im Zielpfad der Verknüpfung zu autorisieren. Benutzer*innen müssen über Berechtigungen am Zielspeicherort verfügen, um die Daten lesen zu können.
Verknüpfungen können sowohl in Lakehouses als auch in KQL-Datenbanken erstellt und als Ordner im Lake angezeigt werden. Auf diese Weise können Spark, SQL, Echtzeitintelligenz und Analysis Services alle Verknüpfungen beim Abfragen von Daten nutzen.
Hinweis
Weitere Informationen zur Verwendung von Verknüpfungen finden Sie in der Dokumentation zu OneLake-Verknüpfungen in der Microsoft Fabric-Dokumentation.