Übung: Visualisieren von Daten mit dem „render“-Operator
Sie haben ein meteorologisches Dataset verwendet, um die Anzahl bestimmter Arten von Sturmereignissen in verschiedenen US-Bundesstaaten für das Jahr 2007 zu aggregieren und zu vergleichen. Hier visualisieren Sie diese Ergebnisse mithilfe von nach Zeitintervallen aufgeschlüsselten Diagrammen.
Verwenden Sie den render-Operator
Erinnern Sie sich daran, dass Sie den summarize-Operator verwendet haben, um Ereignisse nach einem gemeinsamen Feld wie State zu gruppieren. In der vorherigen Einheit haben Sie verschiedene Versionen des count-Operators verwendet, um die Anzahl und die Arten der Ereignisse nach Bundesstaat zu vergleichen. Die Visualisierung dieser Ergebnisse kann ein nützliches Hilfsmittel zum Vergleichen der Aktivität zwischen den Bundesstaaten sein.
Zum Visualisieren der Ergebnisse verwenden Sie den render-Operator. Dieser Operator steht am Ende einer Abfrage. Innerhalb des render-Operators geben Sie an, welche Art von Visualisierung verwendet werden soll, z. B. columnchart, barchart, piechart, scatterchart, pivotchart und andere. Außerdem können Sie optional verschiedene Eigenschaften der Visualisierung definieren, z. B. die x-Achse oder die y-Achse.
In diesem Beispiel visualisieren Sie die vorherige Abfrage mithilfe eines Balkendiagramms.
Führen Sie die folgende Abfrage aus.
StormEvents | summarize count(), EventsWithDamageToCrops = countif(DamageCrops > 0), dcount(EventType) by State | sort by count_ | render barchartSie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:
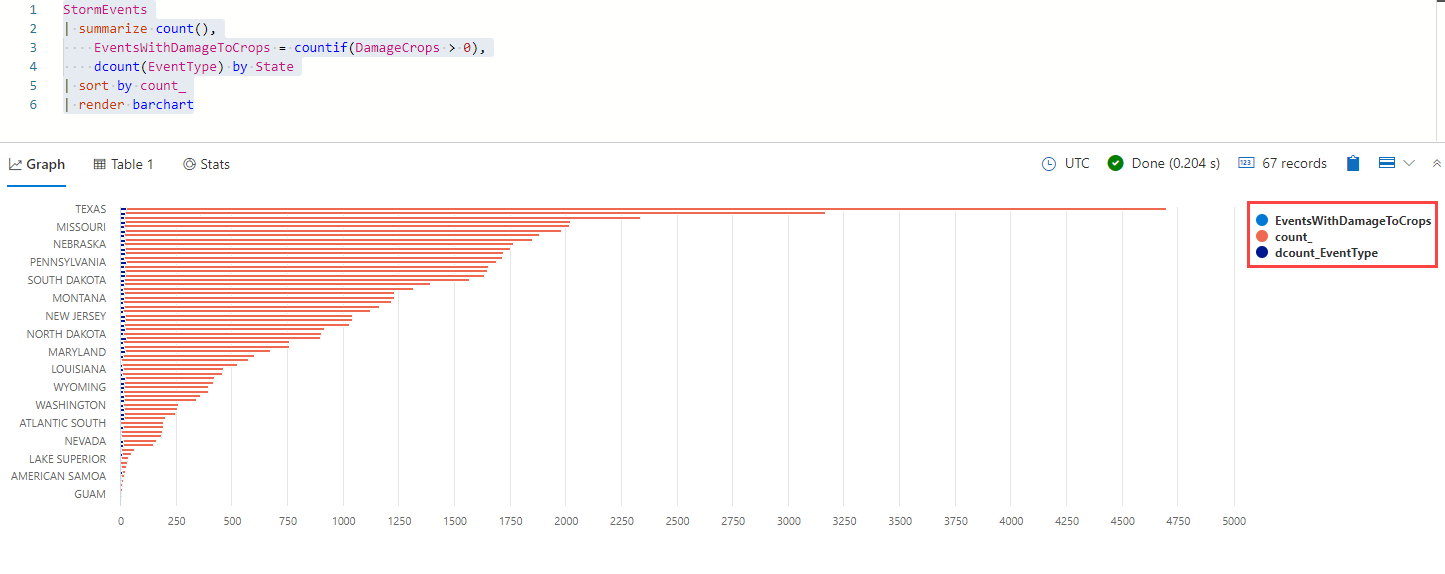
Beachten Sie die Legende rechts neben dem Balkendiagramm. Jeder Wert in der Legende stellt eine andere Datenspalte dar, zusammengefasst nach dem State in der Abfrage. Versuchen Sie, einen der Werte auszuwählen, etwa count_, um die Darstellung der Daten im Balkendiagramm umzuschalten. Durch Deaktivieren von count_ entfernen Sie die Gesamtzahl, zurück bleiben die Anzahl der Ereignisse, die Schäden verursacht haben, und die Anzahl der Einzelereignisse. Sie sollten ein Diagramm erhalten, das aussieht wie in der folgenden Abbildung:
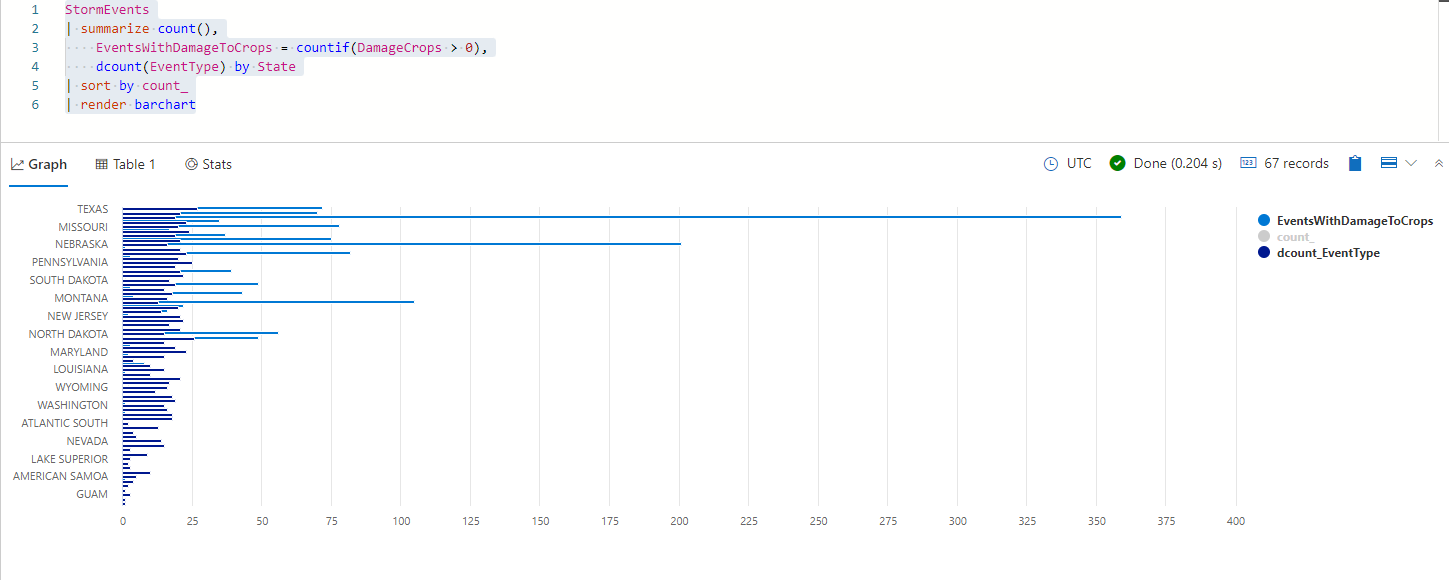
Sehen Sie sich das resultierende Balkendiagramm an. Welche Erkenntnisse können Sie daraus gewinnen? Beispielsweise fällt Ihnen vielleicht auf, dass Texas die meisten einzelnen Sturmereignisse hatte, Iowa aber die höchste Inzidenz von Sturmereignissen mit Schäden.


Gruppieren von Werten mithilfe der bin()-Funktion
Bisher haben Sie Aggregationsfunktionen zum Gruppieren von Ereignissen nach State verwendet. Sehen wir uns nun die Verteilung von Stürmen über das Jahr an, indem wir Daten nach Zeit gruppieren. Die Zeitwerte, die wir in jedem Datensatz haben, sind die Anfangs- und die Endzeit. Gruppieren wir die Anfangszeiten der Ereignisse nach Woche, sodass wir sehen können, wie viele Stürme im Jahr 2007 jede Woche stattgefunden haben.
Sie verwenden die bin()-Funktion, die Werte in festgelegten Intervallen gruppiert. Vielleicht verfügen Sie für jeden Tag des Jahres über Daten, und Sie möchten diese Daten nach Wochen gruppieren. Oder Sie möchten Bevölkerungsdaten nach Altersintervallen gruppieren. Dies ist die Syntax dieses Operators:
bin(value,roundTo)
Der Intervallwert kann eine Zahl, ein Datum oder ein Zeitbereich sein. Sie aggregieren die Anzahl mithilfe der bin()-Funktion, um eine Anzahl von Ereignissen pro Woche zu erhalten. Der Wert, den Sie gruppieren möchten, ist die StartTime des Sturmereignisses, wobei die roundTo-Intervallgröße 7Days oder kurz 7d beträgt. Rendern Sie die Daten schließlich als Säulendiagramm, um ein Histogramm zu erstellen.
Führen Sie die folgende Abfrage aus:
StormEvents | summarize count() by bin(StartTime, 7d) | render columnchartSie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:
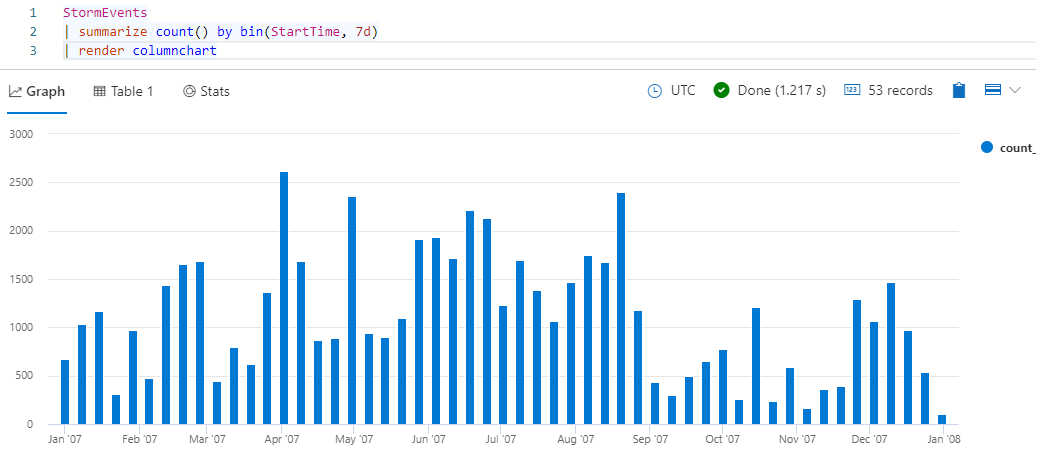
Sehen Sie sich das resultierende Histogramm an. Zeigen Sie mit der Maus auf einen der Balken, um die Anfangszeit (x-Wert) und die Ereignisanzahl (y-Wert) anzuzeigen.
Verwenden Sie den sum-Operator
In der vorherigen Abfrage haben Sie sich die Anzahl der Sturmereignisse im zeitlichen Ablauf angesehen. Sehen wir uns nun die Schäden an, die durch diese Sturme verursacht wurden. Dazu verwenden Sie die sum-Aggregationsfunktion, da Sie die Gesamtmenge der Schäden sehen möchten, die in jedem Zeitintervall verursacht wurden. Das Dataset, mit dem Sie arbeiten, weist zwei Spalten auf, die sich auf Schäden beziehen: DamageProperty und DamageCrops.
In der folgenden Abfrage erstellen Sie zunächst eine berechnete Spalte, in der diese beiden Schadensquellen addiert werden. Anschließend erstellen Sie eine Aggregation der Gesamtschäden im Wochenintervall. Schließlich rendern Sie ein Säulendiagramm, das die wöchentlichen Schäden darstellt, die durch alle Stürme verursacht werden.
Führen Sie die folgende Abfrage aus:
StormEvents | extend damage = DamageProperty + DamageCrops | summarize sum(damage) by bin(StartTime, 7d) | render columnchartSie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:
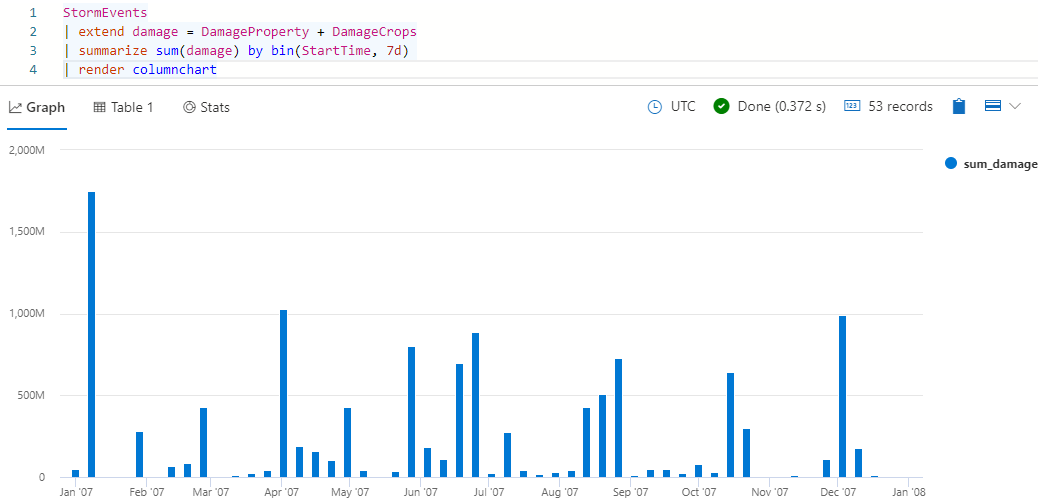
Die vorherige Abfrage zeigt Ihnen Schäden als Funktion der Zeit. Eine weitere Möglichkeit zum Vergleichen der Schäden ist nach der Ereignisart. Führen Sie die folgende Abfrage aus, um ein Kreisdiagramm zum Vergleichen der Schäden zu verwenden, die durch verschiedene Ereignisarten verursacht wurden.
StormEvents | extend damage = DamageProperty + DamageCrops | summarize sum(damage) by EventType | render piechartSie sollten Ergebnisse erhalten, die wie in der folgenden Abbildung aussehen:
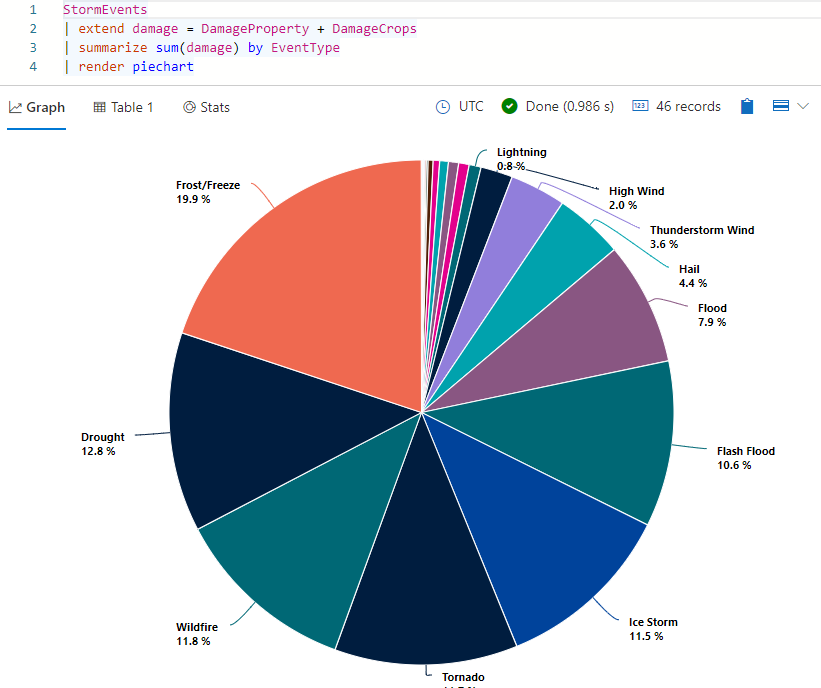
Zeigen Sie auf eins der Segmente des Kreisdiagramms. Sie sollten den absoluten Wert (Gesamtschaden, der durch diese Ereignisart verursacht wurde) und den entsprechenden Prozentsatz am Gesamtschaden sehen.