Arten von ML
Es gibt mehrere Arten des maschinellen Lernens. Die für Sie geeignete Art richtet sich danach, was Sie vorhersagen möchten. Im folgenden Diagramm ist eine Aufschlüsselung gängiger Arten von maschinellem Lernen dargestellt.
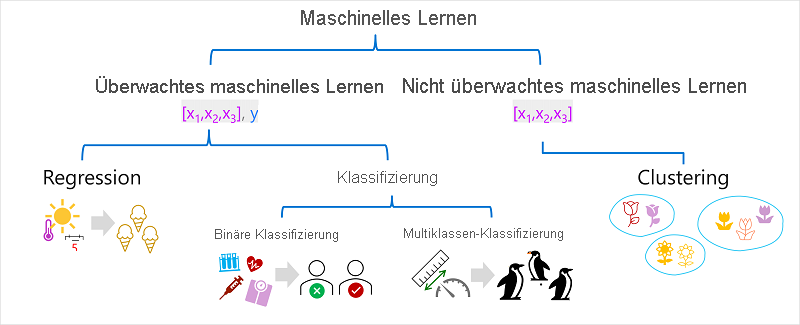
Überwachtes maschinelles Lernen
Überwachtes maschinelles Lernen ist ein allgemeiner Begriff für Machine-Learning-Algorithmen, bei denen die Trainingsdaten sowohl Feature-Werte als auch bekannte Bezeichnungswerte enthalten. Überwachtes maschinelles Lernen wird verwendet, um Modelle zu trainieren, indem eine Beziehung zwischen den Features und Bezeichnungen in früheren Beobachtungen bestimmt wird, sodass in zukünftigen Fällen unbekannte Bezeichnungen für Features vorhergesagt werden können.
Regression
Regression ist eine Form des überwachten maschinellen Lernens, bei der die vom Modell vorhergesagte Bezeichnung ein numerischer Wert ist. Beispiel:
- Die Anzahl der verkauften Portionen Eiscreme an einem bestimmten Tag, basierend auf Temperatur, Niederschlag und Windgeschwindigkeit.
- Der Verkaufspreis einer Immobilie basierend auf ihrer Größe in Quadratmetern, der Anzahl der darin enthaltenen Schlafzimmer und sozioökonomischen Metriken des umliegenden Gebiets.
- Die Kraftstoffeffizienz (in Meilen pro Gallone) eines Autos basierend auf motorischer Größe, Gewicht, Breite, Höhe und Länge.
Klassifizierung
Klassifizierung ist eine Form des überwachten maschinellen Lernens, bei der die Bezeichnung eine Kategorisierung oder Klasse darstellt. Es gibt zwei gängige Klassifizierungsszenarien.
Binäre Klassifizierung
Bei der binären Klassifizierung bestimmt die Bezeichnung, ob das beobachtete Element eine Instanz einer bestimmten Klasse ist (oder nicht). Anders ausgedrückt: Binäre Klassifizierungsmodelle prognostizieren eines von zwei sich gegenseitig ausschließenden Ergebnissen. Beispiel:
- Ob ein Patient ein Diabetesrisiko hat, basierend auf klinischen Metriken wie Gewicht, Alter, Blutzuckerspiegel usw.
- Ob ein Bankkunde einen Kredit nicht zurückzahlt, auf Grundlage von Einkommen, Kreditgeschichte, Alter und anderen Faktoren.
- Ob ein Adresslistenkunde positiv auf ein Marketingangebot reagiert, basierend auf demografischen Attributen und früheren Käufen.
In all diesen Beispielen gibt das Modell eine binäre true/-false- oder positiv/negativ- Vorhersage für eine einzelne mögliche Klasse ab.
Multiklassen-Klassifizierung
Multiklassen-Klassifizierung erweitert die binäre Klassifizierung, um eine Bezeichnung vorherzusagen, die eine von mehreren möglichen Klassen darstellt. Ein auf ein Objekt angewendeter
- Die Art eines Pinguins (Adelie, Gentoo oder Chinstrap) basierend auf seinen Körpermaßen.
- Das Genre eines Films (Komödie, Horror, Romantik, Abenteuer oder Science Fiction) basierend auf seiner Besetzung, seinem Regisseur und seinem Budget.
In den meisten Szenarien, die eine bekannte Gruppe von mehreren Klassen umfassen, wird die Multiklassen-Klassifizierung verwendet, um sich gegenseitig ausschließende Bezeichnungen vorherzusagen. Beispielsweise kann ein Pinguin nicht sowohl ein Gentoo als auch ein Adelie sein. Es gibt jedoch auch einige Algorithmen, die Sie verwenden können, um Multitag--Klassifizierungsmodelle zu trainieren, bei denen mehrere gültige Bezeichnungen für eine einzelne Beobachtung vorhanden sein können. Beispielsweise könnte ein Film potenziell sowohl als Science-Fiction als auch als Komödie kategorisiert werden.
Nicht überwachtes maschinelles Lernen
Unüberwachtes maschinelles Lernen umfasst das Trainieren von Modellen mit Daten, die nur aus Feature-Werten ohne bekannte Bezeichnungen bestehen. Nicht überwachte Machine-Learning-Algorithmen bestimmen Beziehungen zwischen den Features der Beobachtungen in den Trainingsdaten.
Clustering
Die häufigste Form des nicht überwachten maschinellen Lernens ist Clustering. Ein Clustering-Algorithmus identifiziert Ähnlichkeiten zwischen Beobachtungen basierend auf ihren Features und gruppiert sie in unterschiedliche Cluster. Beispiel:
- Gruppieren ähnlicher Blumen basierend auf ihrer Größe, der Anzahl der Blätter und der Anzahl der Blütenblätter.
- Identifizieren von Gruppen ähnlicher Kunden basierend auf demografischen Attributen und Kaufverhalten.
In gewisser Weise ähnelt Clustering der Klassifizierung mit mehreren Klassen, da Beobachtungen in unterschiedliche Gruppen kategorisiert werden. Der Unterschied besteht darin, dass Sie bei Verwendung der Klassifizierung bereits die Klassen kennen, zu denen die Beobachtungen in den Trainingsdaten gehören. Der Algorithmus funktioniert also, indem er die Beziehung zwischen den Features und der bekannten Klassifizierungsbezeichnung ermittelt. Beim Clustering gibt es keine zuvor bekannte Clusterbezeichnung, und der Algorithmus gruppiert die Datenbeobachtungen ausschließlich auf Grundlage der Ähnlichkeit von Features.
In einigen Fällen wird Clustering verwendet, um die Gruppe von Klassen zu bestimmen, die vor dem Trainieren eines Klassifizierungsmodells vorhanden sind. Beispielsweise können Sie Clustering verwenden, um Ihre Kunden in Gruppen zu segmentieren, und dann diese Gruppen analysieren, um verschiedene Kundenklassen zu identifizieren und zu kategorisieren (hoher Wert – geringes Volumen, häufige kleine Einkäufe usw.). Sie können dann Ihre Kategorisierungen verwenden, um die Beobachtungen in Ihren Clusteringergebnissen zu bezeichnen, und die bezeichneten Daten verwenden, um ein Klassifizierungsmodell zu trainieren, das vorhersagt, zu welcher Kundenkategorie ein neuer Kunde gehören könnte.