Bewerten, Bereitstellen und Testen eines optimierten Basismodells
Wenn Sie ein Basismodell aus dem Modellkatalog in Azure Machine Learning optimiert haben, können Sie das Modell auswerten und bereitstellen, um es einfach zu testen und zu nutzen.
Auswerten des optimierten Modells
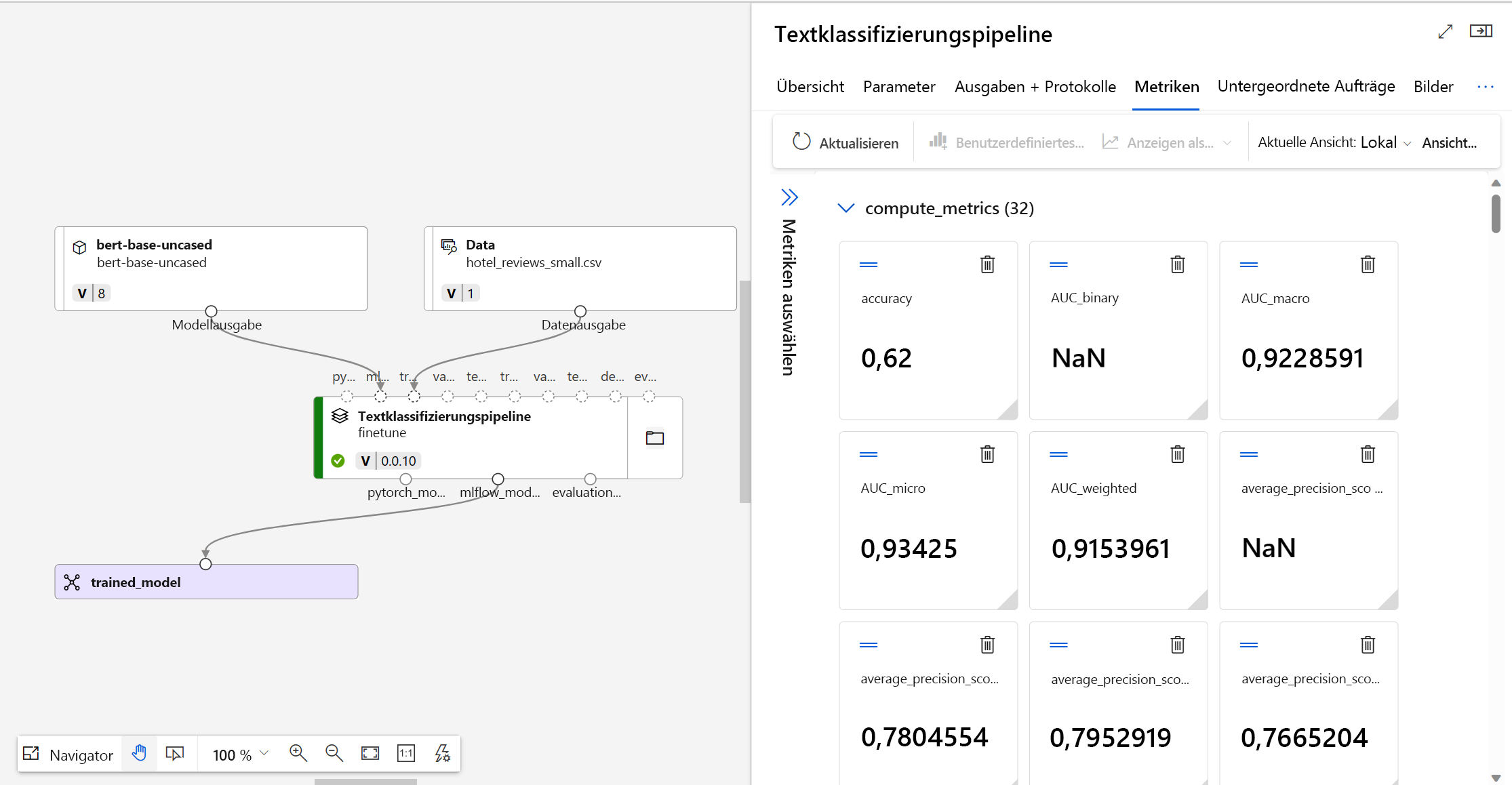
Um zu bestimmen, ob Ihr optimiertes Modell wie erwartet funktioniert, können Sie die Trainings- und Auswertungsmetriken überprüfen.
Wenn Sie ein Modell zur Optimierung übermitteln, erstellt Azure Machine Learning innerhalb eines Experiments einen neuen Pipelineauftrag. Der Pipelineauftrag enthält eine Komponente, die für die Optimierung des Modells steht. Sie können Protokolle, Metriken und Ausgaben des Auftrags analysieren, indem Sie den abgeschlossenen Pipelineauftrag auswählen. Wenn sie die bestimmte Optimierungskomponente auswählen, können Sie diese näher erkunden.
Tipp
In Azure Machine Learning werden Modellmetriken mit MLflow nachverfolgt. Für einen programmgesteuerten Zugriff auf Metriken und deren Überprüfung können Sie MLflow in einem Jupyter-Notebook verwenden.
Bereitstellen Ihres optimierten Modells
Zum Testen und Nutzen Ihres optimierten Modells können Sie das Modell an einem Endpunkt bereitstellen.
Ein Endpunkt in Azure Machine Learning ist eine Anwendungsprogrammierschnittstelle (Application Programming Interface, API), die das trainierte oder angepasste Modell verfügbar macht, sodass Benutzer*innen oder Anwendungen Vorhersagen basierend auf neuen Daten treffen können.
Es gibt zwei Arten von Endpunkten in Azure Machine Learning:
- Echtzeitendpunkte: Für die Verarbeitung sofortiger oder On-the-Fly-Vorhersagen entwickelt
- Batchendpunkte: Für die gleichzeitige Verarbeitung großer Datenmengen optimiert
Da Sie mit Echtzeitendpunkte sofortige Vorhersagen erhalten können, sind diese Endpunkte auch ideal zum Testen von Modellvorhersagen.
Registrieren Ihres Modells mithilfe von Azure Machine Learning Studio
Zum Bereitstellen Ihres optimierten Modells mithilfe von Azure Machine Learning Studio können Sie die Ausgabe des Optimierungsauftrags verwenden.
Azure Machine Learning verwendet MLflow, um Aufträge nachzuverfolgen und Metriken sowie Modelldateien zu protokollieren. Durch die Integration von MLflow mit Azure Machine Learning Studio können Sie ein Modell aus einem Auftrag mit minimalem Aufwand bereitstellen.
Zunächst müssen Sie das Modell aus der Auftragsausgabe registrieren. Navigieren Sie zur Auftragsübersicht, um die Option + Modell registrieren zu finden.
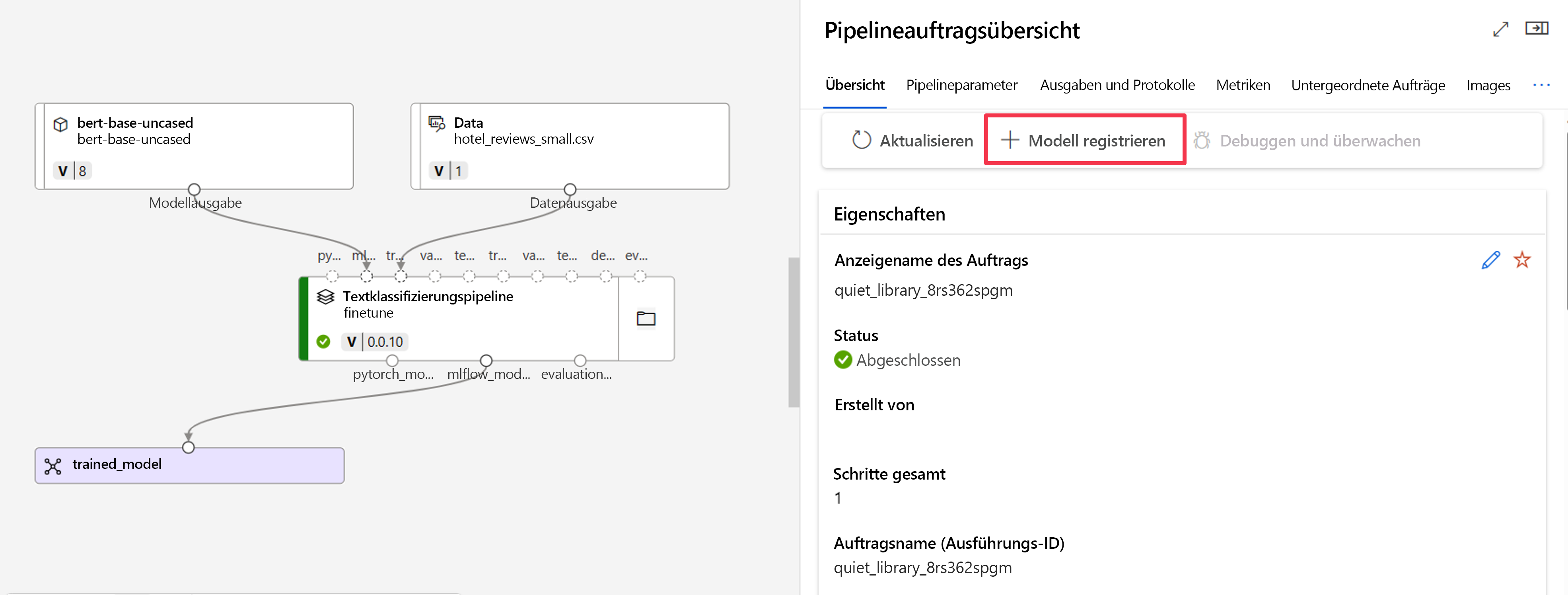
Der registrierte Modelltyp ist MLflow, und Azure Machine Learning fügt automatisch den Ordner mit den Modelldateien ein. Sie müssen einen Namen für das registrierte Modell und optional eine Version angeben.
Bereitstellen Ihres Modells mithilfe von Azure Machine Learning Studio
Nachdem das Modell im Azure Machine Learning-Arbeitsbereich registriert wurde, können Sie zur Modellübersicht navigieren und das Modell an einem Echtzeit- oder Batchendpunkt bereitstellen.
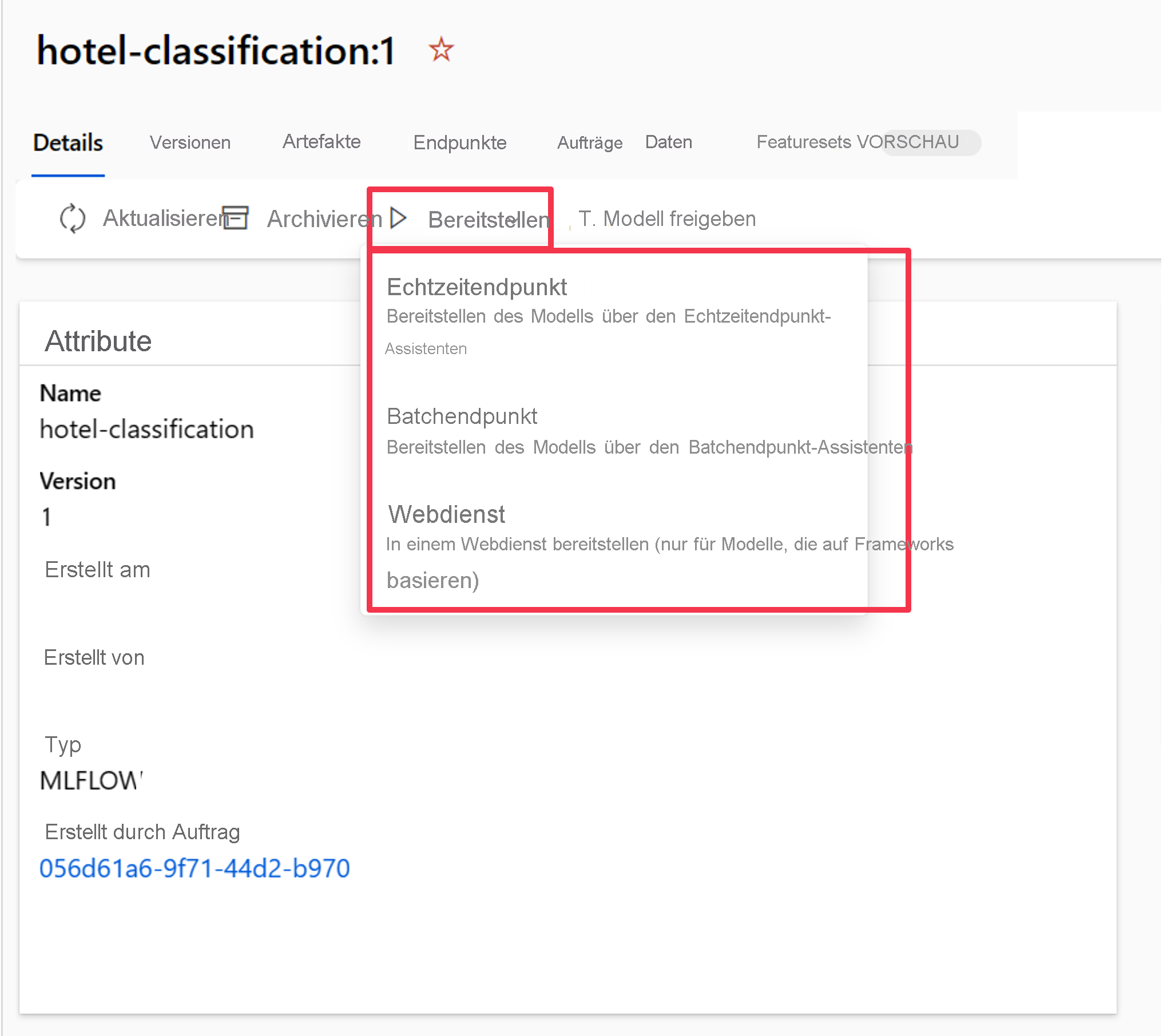
Sie können beispielsweise Ihr Modell für einen Echtzeitendpunkt mit den folgenden Angaben bereitstellen:
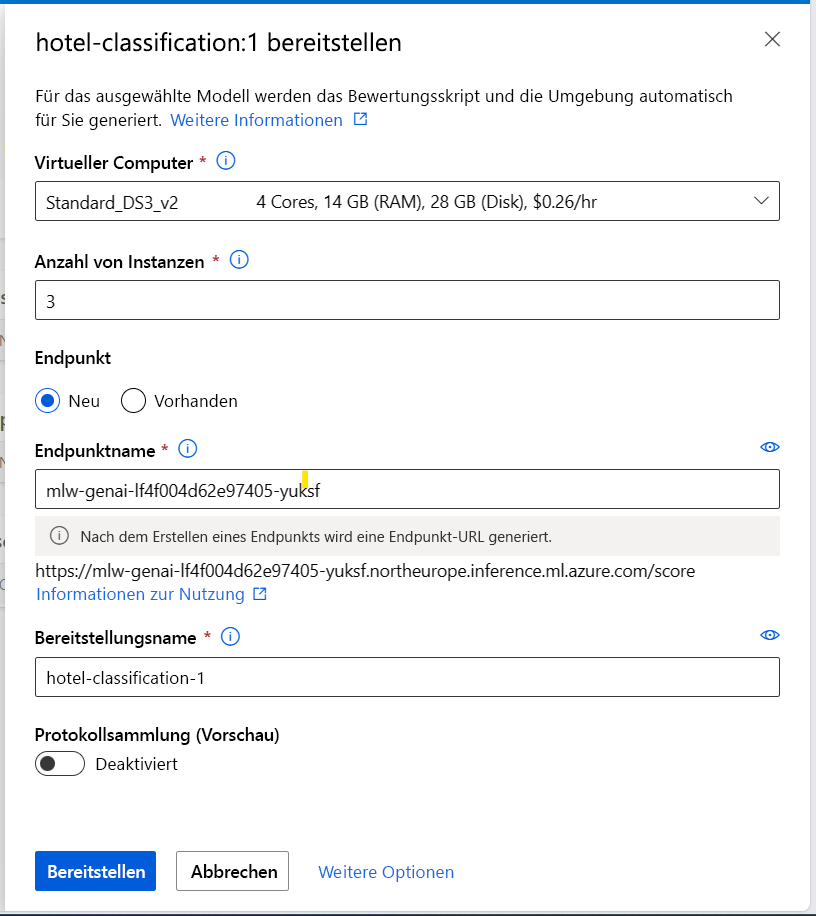
- VM: Die vom Endpunkt verwendete Computeressource
- Anzahl der Instanzen: Die Anzahl der Instanzen, die für die Bereitstellung verwendet werden
- Endpunkt: Bereitstellung Ihres Modells an einem neuen oder vorhandenen Endpunkt
- Endpunktname: Zum Generieren der Endpunkt-URL
- Bereitstellungsname: Name des Bereitstellungsmodells an einem Endpunkt
Hinweis
Sie können mehrere Modelle an einem Batchendpunkt bereitstellen. Die Erstellung des Endpunkts und die Bereitstellung eines Modells für einen Endpunkt dauern einige Zeit. Warten Sie, bis sowohl der Endpunkt als auch die Bereitstellung verfügbar sind, bevor Sie versuchen, das bereitgestellte Modell zu testen oder zu nutzen.
Testen des Modells in Azure Machine Learning Studio
Wenn Ihr Modell an einem Echtzeitendpunkt bereitgestellt wird, können Sie das Modell schnell in Azure Machine Learning Studio testen.
Navigieren Sie zum Endpunkt, und erkunden Sie die Registerkarte Test.
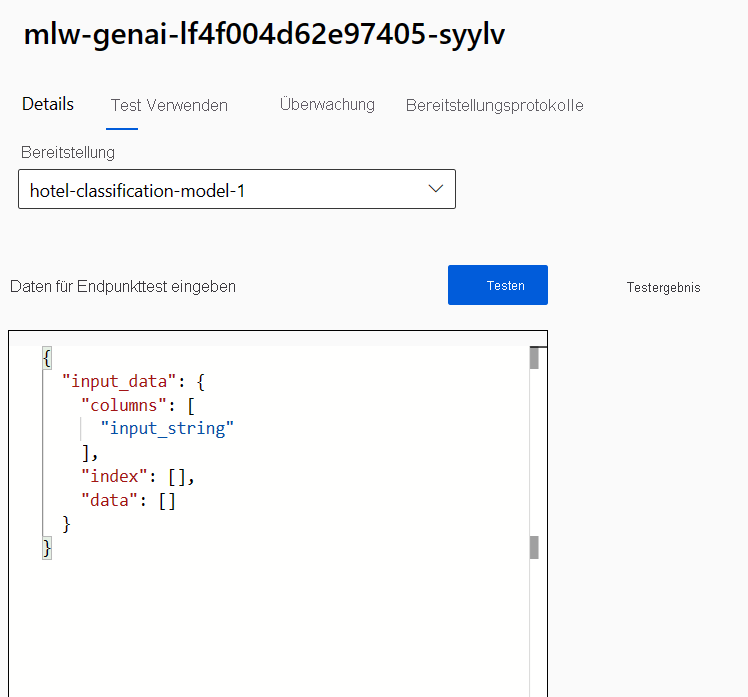
Da der Echtzeitendpunkt als API fungiert, erwartet er die Eingabedaten im JSON-Format. Ein Beispiel für die erwartete Ausgabe wird auf der Registerkarte Test bereitgestellt:
{
"input_data": {
"columns": [
"input_string"
],
"index": [],
"data": []
}
}
Das Format der Testdaten sollte mit Ausnahme der Bezeichnungsspalte den Trainingsdaten ähneln. Wenn Sie beispielsweise ein Modell testen möchten, das für die Textklassifizierung optimiert ist, müssen Sie dem Endpunkt den zu klassifizierenden Satz als Spalte bereitstellen:
{
"input_data": {
"columns": [
"input_string"
],
"index": [0, 1],
"data": [["This would be the first sentence you want to classify."], ["This would be the second sentence you want to classify."]]
}
}
Sie können alle Testdaten im Studio eingeben und Testen auswählen, um die Daten an den Endpunkt zu senden. Das Ergebnis wird fast sofort unter Testergebnis angezeigt.
Tipp
Wenn Sie die erwartete Antwort nicht unter Testergebnis finden, besteht die wahrscheinlichste Ursache darin, dass das Format der Eingabedaten falsch ist. Das Bewertungsskript wird für Sie automatisch generiert, wenn Sie ein MLflow-Modell bereitstellen. Das bedeutet, dass das Format der Eingabedaten den Trainingsdaten ähneln sollte (mit Ausnahme der Bezeichnungsspalte).